|
Katalog > |
|
|
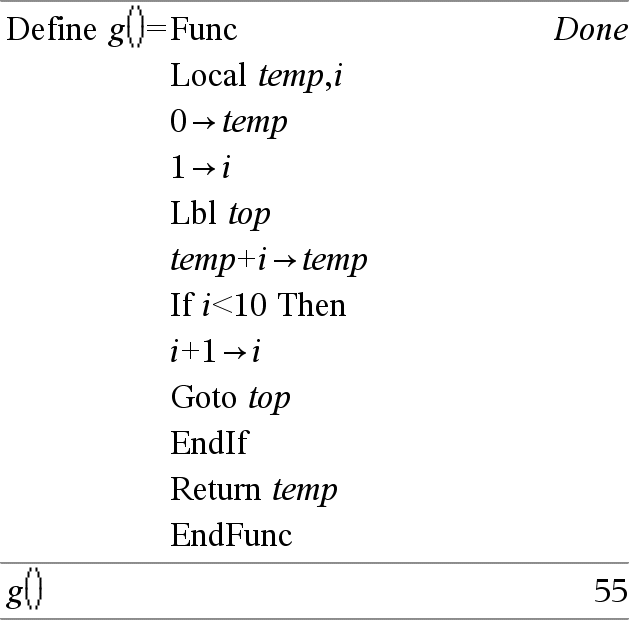
Lbl MarkeName Definiert in einer Funktion eine Marke mit dem Namen MarkeName. Mit der Anweisung Goto MarkeName können Sie die Ausführung an der Anweisung fortsetzen, die unmittelbar auf die Marke folgt. Für MarkeName gelten die gleichen Benennungsregeln wie für einen Variablennamen. Hinweis zum Eingeben des Beispiels: Anweisungen für die Eingabe von mehrzeiligen Programm- und Funktionsdefinitionen finden Sie im Abschnitt „Calculator“ des Produkthandbuchs. |
|

|
Katalog > |
|
|
lcm(Zahl1, Zahl2)ÞAusdruck lcm(Liste1, Liste2)ÞListe lcm(Matrix1, Matrix2)ÞMatrix Gibt das kleinste gemeinsame Vielfache der beiden Argumente zurück. Das lcm zweier Brüche ist das lcm ihrer Zähler dividiert durch den größten gemeinsamen Teiler (gcd) ihrer Nenner. Das lcm von Dezimalbruchzahlen ist ihr Produkt. Für zwei Listen oder Matrizen wird das kleinste gemeinsame Vielfache der entsprechenden Elemente zurückgegeben. |
|
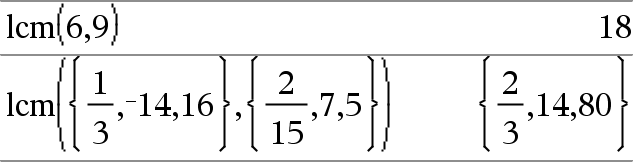
|
Katalog > |
|
|
left(Quellstring[, Anz])ÞString Gibt Anz Zeichen zurück, die links in der Zeichenkette Quellstring enthalten sind. Wenn Sie Anz weglassen, wird der gesamte Quellstring zurückgegeben. |
|
|
left(Liste1[, Anz])ÞListe Gibt Anz Elemente zurück, die links in Liste1 enthalten sind. Wenn Sie Anz weglassen, wird die gesamte Liste1 zurückgegeben. |
|
|
left(Vergleich)ÞAusdruck Gibt die linke Seite einer Gleichung oder Ungleichung zurück. |


|
Katalog > |
|
|
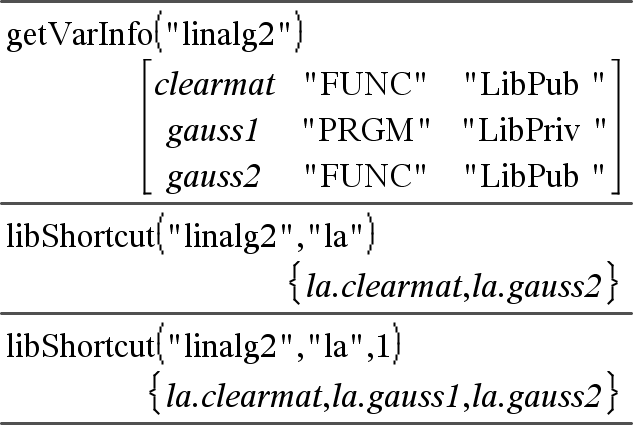
libShortcut(BiblioNameString, VerknNameString [, BiblioPrivMerker])ÞListe von Variablen Erstellt eine Variablengruppe im aktuellen Problem, die Verweise auf alle Objekte im angegebenen Bibliotheksdokument BiblioNameString enthält. Fügt außerdem die Gruppenmitglieder dem Variablenmenü hinzu. Sie können dann auf jedes Objekt mit VerknNameString verweisen. Setzen Sie BiblioPrivMerker=0, um private Bibliotheksobjekte auszuschließen (Standard) Setzen Sie BiblioPrivMerker=1, um private Bibliotheksobjekte einzubeziehen Informationen zum Kopieren einer Variablengruppe finden Sie unter CopyVar (hier). Informationen zum Löschen einer Variablengruppe finden Sie unter DelVar (hier). |
Dieses Beispiel setzt ein richtig gespeichertes und aktualisiertes Bibliotheksdokument namens linalg2 voraus, das als clearmat, gauss1 und gauss2 definierte Objekte enthält.
|
|
Katalog > |
|
|
LinRegBx X,Y[,[Häuf][,Kategorie,Mit]] Berechnet die lineare Regressiony = a+b·xauf Listen X und Y mit der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Alle Listen außer Mit müssen die gleiche Dimension besitzen. X und Y sind Listen von unabhängigen und abhängigen Variablen. Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in Häuf gibt die Häufigkeit für jeden entsprechenden Datenpunkt X und Y an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein. Kategorie ist eine Liste von Kategoriecodes Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur solche Datenelemente, deren Kategoriecode in dieser Liste enthalten ist, sind in der Berechnung enthalten. Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: a+b·x |
|
stat.a, stat.b |
Regressionskoeffizienten |
|
stat.r2 |
Bestimmungskoeffizient |
|
stat.r |
Korrelationskoeffizient |
|
stat.Resid |
Residuen von der Regression |
|
stat.XReg |
Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.YReg |
Liste der Datenpunkte in der modifizierten Y-Liste, die schließlich in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.FreqReg |
Liste der Häufigkeiten für stat.XReg und stat.YReg |
|
Katalog > |
|
|
LinRegMx X,Y[,[Häuf][,Kategorie,Mit]] Berechnet die lineare Regression y = m·x+b auf Liste X und Y mit der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Alle Listen außer Mit müssen die gleiche Dimension besitzen. X und Y sind Listen von unabhängigen und abhängigen Variablen. Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in Häuf gibt die Häufigkeit für jeden entsprechenden Datenpunkt X und Y an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein. Kategorie ist eine Liste von Kategoriecodes Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur solche Datenelemente, deren Kategoriecode in dieser Liste enthalten ist, sind in der Berechnung enthalten. Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: m·x+b |
|
stat.m, stat.b |
Regressionskoeffizienten |
|
stat.r2 |
Bestimmungskoeffizient |
|
stat.r |
Korrelationskoeffizient |
|
stat.Resid |
Residuen von der Regression |
|
stat.XReg |
Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.YReg |
Liste der Datenpunkte in der modifizierten Y-Liste, die schließlich in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.FreqReg |
Liste der Häufigkeiten für stat.XReg und stat.YReg |
|
Katalog > |
|
|
LinRegtIntervals X,Y[,F[,0[,KStufe]]] Für Steigung. Berechnet ein Konfidenzintervall des Niveaus K für die Steigung. LinRegtIntervals X,Y[,F[,1,XWert[,KStufe]]] Für Antwort. Berechnet einen vorhergesagten y-Wert, ein Niveau-K-Vorhersageintervall für eine einzelne Beobachtung und ein Niveau-K-Konfidenzintervall für die mittlere Antwort. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Alle Listen müssen die gleiche Dimension besitzen. X und Y sind Listen von unabhängigen und abhängigen Variablen. F ist eine optionale Liste von Frequenzwerten. Jedes Element in F gibt die Häufigkeit für jeden entsprechenden X und Y Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein. Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: a+b·x |
|
stat.a, stat.b |
Regressionskoeffizienten |
|
stat.df |
Freiheitsgrade |
|
stat.r2 |
Bestimmungskoeffizient |
|
stat.r |
Korrelationskoeffizient |
|
stat.Resid |
Residuen von der Regression |
Nur für Steigung
|
Ausgabevariable |
Beschreibung |
|
[stat.CLower, stat.CUpper] |
Konfidenzintervall für die Steigung |
|
stat.ME |
Konfidenzintervall-Fehlertoleranz |
|
stat.SESlope |
Standardfehler der Steigung |
|
stat.s |
Standardfehler an der Linie |
Nur für Antwort
|
Ausgabevariable |
Beschreibung |
|
[stat.CLower, stat.CUpper] |
Konfidenzintervall für die mittlere Antwort |
|
stat.ME |
Konfidenzintervall-Fehlertoleranz |
|
stat.SE |
Standardfehler der mittleren Antwort |
|
[stat.LowerPred, stat.UpperPred] |
Vorhersageintervall für eine einzelne Beobachtung |
|
stat.MEPred |
Vorhersageintervall-Fehlertoleranz |
|
stat.SEPred |
Standardfehler für Vorhersage |
|
stat.y |
a + b·XWert |
|
Katalog > |
|
|
LinRegtTest X,Y[,Häuf[,Hypoth]] Berechnet eine lineare Regression auf den X- und Y-Listen und einen t-Test auf dem Wert der Steigung b und den Korrelationskoeffizienten r für die Gleichung y=a+bx. Er berechnet die Null-Hypothese H0:b=0 (gleichwertig, r=0) in Bezug auf eine von drei alternativen Hypothesen. Alle Listen müssen die gleiche Dimension besitzen. X und Y sind Listen von unabhängigen und abhängigen Variablen. Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein. Hypoth ist ein optionaler Wert, der eine von drei alternativen Hypothesen angibt, in Bezug auf die die Nullhypothese (H0:b=r=0) untersucht wird. Für Ha: bÉ0 und rÉ0 (Standard) setzen Sie Hypoth=0 Für Ha: b<0 und r<0 setzen Sie Hypoth<0 Für Ha: b>0 und r>0 setzen Sie Hypoth>0 Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: a + b·x |
|
stat.t |
t-Statistik für Signifikanztest |
|
stat.PVal |
Kleinste Signifikanzebene, bei der die Nullhypothese verworfen werden kann |
|
stat.df |
Freiheitsgrade |
|
stat.a, stat.b |
Regressionskoeffizienten |
|
stat.s |
Standardfehler an der Linie |
|
stat.SESlope |
Standardfehler der Steigung |
|
stat.r2 |
Bestimmungskoeffizient |
|
stat.r |
Korrelationskoeffizient |
|
stat.Resid |
Residuen von der Regression |
|
Katalog > |
|
|
Liefert eine Liste mit Lösungen für die Variablen Var1, Var2, ... Das erste Argument muss ein System linearer Gleichungen bzw. eine einzelne lineare Gleichung ergeben. Anderenfalls tritt ein Argumentfehler auf. Die Auswertung von |
|

|
Katalog > |
|
|
@list(Liste1)ÞListe Hinweis: Sie können diese Funktion über die Tastatur Ihres Computers eingeben, indem Sie deltaList(...) eintippen. Ergibt eine Liste mit den Differenzen der aufeinander folgenden Elemente in Liste1. Jedes Element in Liste1 wird vom folgenden Element in Liste1 subtrahiert. Die Ergebnisliste enthält stets ein Element weniger als die ursprüngliche Liste1. |
|
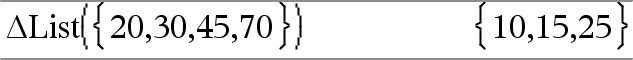
|
Katalog > |
|
|
list4mat(Liste [, ElementeProZeile])ÞMatrix Gibt eine Matrix zurück, die Zeile für Zeile mit den Elementen aus Liste aufgefüllt wurde. ElementeProZeile gibt (sofern angegeben) die Anzahl der Elemente pro Zeile an. Vorgabe ist die Anzahl der Elemente in Liste (eine Zeile). Wenn Liste die resultierende Matrix nicht vollständig auffüllt, werden Nullen hinzugefügt. Hinweis: Sie können diese Funktion über die Tastatur Ihres Computers eingeben, indem Sie list@>mat(...) eintippen. |
|
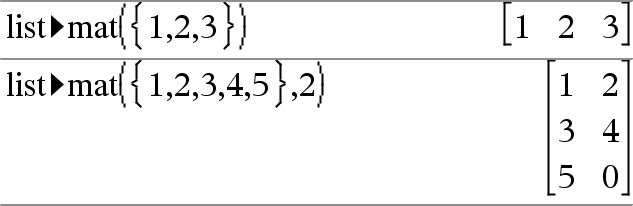
|
/u Tasten |
|
|
ln(Wert1)ÞWert ln(Liste1)ÞListe Gibt den natürlichen Logarithmus des Arguments zurück. Gibt für eine Liste die natürlichen Logarithmen der einzelnen Elemente zurück. |
Bei Komplex-Formatmodus reell:
Bei Komplex-Formatmodus kartesisch:
|
|
ln(Quadratmatrix1)ÞQuadratmatrix Ergibt den natürlichen Matrix-Logarithmus von Quadratmatrix1. Dies ist nicht gleichbedeutend mit der Berechnung des natürlichen Logarithmus jedes einzelnen Elements. Näheres zum Berechnungsverfahren finden Sie im Abschnitt cos(). Quadratmatrix1 muss diagonalisierbar sein. Das Ergebnis enthält immer Fließkommazahlen. |
Im Winkelmodus Bogenmaß und Komplex-Formatmodus “kartesisch”:
Um das ganze Ergebnis zu sehen, drücken Sie 5 und verwenden dann 7 und 8, um den Cursor zu bewegen. |


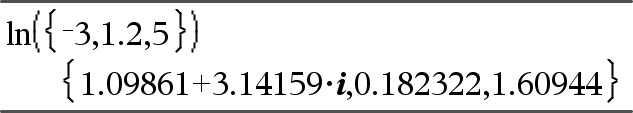

|
Katalog > |
|
|
LnReg X, Y[, [Häuf] [, Kategorie, Mit]] Berechnet die logarithmische Regression y = a+b·ln(x) auf Listen X und Y mit der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Alle Listen außer Mit müssen die gleiche Dimension besitzen. X und Y sind Listen von unabhängigen und abhängigen Variablen. Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein. Kategorie ist eine Liste von Kategoriecodes Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur solche Datenelemente, deren Kategoriecode in dieser Liste enthalten ist, sind in der Berechnung enthalten. Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: a+b·ln(x) |
|
stat.a, stat.b |
Regressionskoeffizienten |
|
stat.r2 |
Koeffizient der linearen Bestimmtheit für transformierte Daten |
|
stat.r |
Korrelationskoeffizient für transformierte Daten (ln(x), y) |
|
stat.Resid |
Mit dem logarithmischen Modell verknüpfte Residuen |
|
stat.ResidTrans |
Residuen für die lineare Anpassung transformierter Daten |
|
stat.XReg |
Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.YReg |
Liste der Datenpunkte in der modifizierten Y-Liste, die schließlich in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.FreqReg |
Liste der Häufigkeiten für stat.XReg und stat.YReg |
|
Katalog > |
|
|
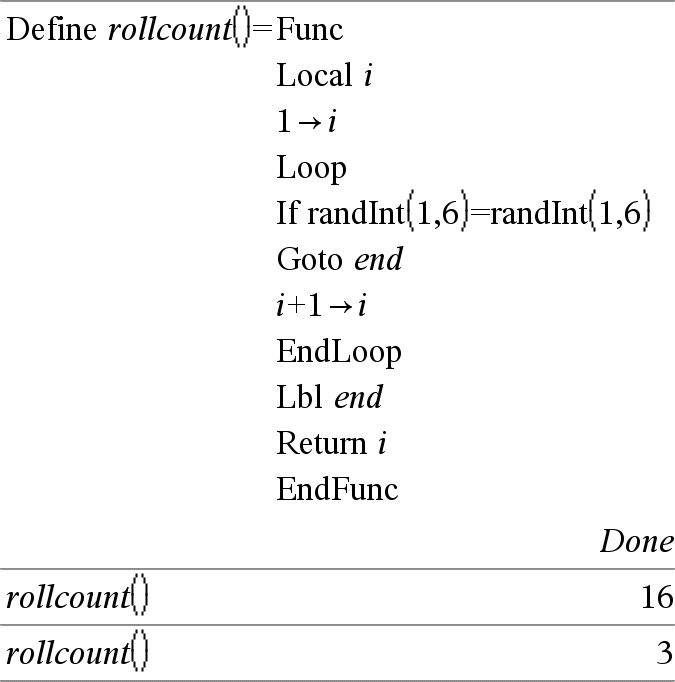
Local Var1[, Var2] [, Var3] ... Deklariert die angegebenen Variablen Variable als lokale Variablen. Diese Variablen existieren nur während der Auswertung einer Funktion und werden gelöscht, wenn die Funktion beendet wird. Hinweis: Lokale Variablen sparen Speicherplatz, da sie nur temporär existieren. Außerdem stören sie keine vorhandenen globalen Variablenwerte. Lokale Variablen müssen für For-Schleifen und für das temporäre Speichern von Werten in mehrzeiligen Funktionen verwendet werden, da Änderungen globaler Variablen in einer Funktion unzulässig sind. Hinweis zum Eingeben des Beispiels: Anweisungen für die Eingabe von mehrzeiligen Programm- und Funktionsdefinitionen finden Sie im Abschnitt „Calculator“ des Produkthandbuchs. |
|
|
Katalog > |
|
|
Sperrt die angegebenen Variablen bzw. die Variablengruppe. Gesperrte Variablen können nicht geändert oder gelöscht werden. Die Systemvariable Ans können Sie nicht sperren oder entsperren, ebenso können Sie die Systemvariablengruppen stat. oder tvm. nicht sperren. Hinweis: Der Befehl Sperren (Lock) löscht den Rückgängig/Wiederholen-Verlauf, wenn er für nicht gesperrte Variablen verwendet wird. |
|

|
/s Tasten |
|
|
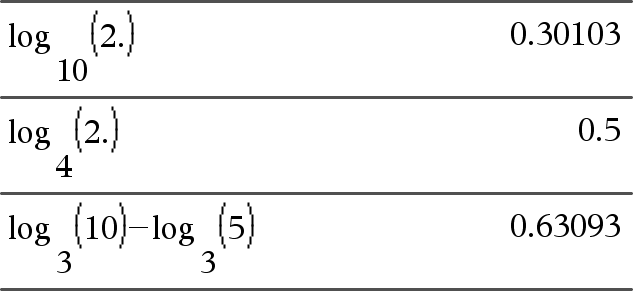
log(Liste1[,Wert2])ÞListe
Gibt für den Logarithmus des Arguments zur Basis Ausdr2 zurück. Hinweis: Siehe auch Vorlage Logarithmus, hier. Gibt bei einer Liste den Logarithmus der Elemente zur Basis Wert2 zurück. Wenn Wert weggelassen wird, wird 10 als Basis verwendet. |
Bei Komplex-Formatmodus reell:
Bei Komplex-Formatmodus kartesisch:
|
|
Gibt den Matrix-Logarithmus von Zahl2 zur Basis Quadratmatrix1 zurück. Dies ist nicht gleichbedeutend mit der Berechnung des Logarithmus jedes Elements zur Basis Zahl2. Näheres zur Berechnungsmethode finden Sie im Abschnitt cos(). Quadratmatrix1 muss diagonalisierbar sein. Das Ergebnis enthält immer Fließkommazahlen. Wenn das Basisargument weggelassen wird, wird 10 als Basis verwendet. |
Im Winkelmodus Bogenmaß und Komplex-Formatmodus “kartesisch”:
Um das ganze Ergebnis zu sehen, drücken Sie 5 und verwenden dann 7 und 8, um den Cursor zu bewegen. |



|
Katalog > |
|
|
Logistic X, Y[, [Häuf] [, Kategorie, Mit]] Berechnet die logistische Regressiony = (c/(1+a·e-bx))auf Listen X und Y mit der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Alle Listen außer Mit müssen die gleiche Dimension besitzen. X und Y sind Listen von unabhängigen und abhängigen Variablen. Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein. Kategorie ist eine Liste von Kategoriecodes Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur solche Datenelemente, deren Kategoriecode in dieser Liste enthalten ist, sind in der Berechnung enthalten. Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: c/(1+a·e-bx) |
|
stat.a, stat.b, stat.c |
Regressionskoeffizienten |
|
stat.Resid |
Residuen von der Regression |
|
stat.XReg |
Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.YReg |
Liste der Datenpunkte in der modifizierten Y-Liste, die schließlich in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.FreqReg |
Liste der Häufigkeiten für stat.XReg und stat.YReg |
|
Katalog > |
|
|
LogisticD X, Y [, [Iterationen], [Häuf] [, Kategorie, Mit] ] Berechnet die logistische Regression y = (c/(1+a·e-bx)+d) auf Listen X und Y mit der Häufigkeit Häuf unter Verwendung einer bestimmten Anzahl von Iterationen. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Alle Listen außer Mit müssen die gleiche Dimension besitzen. X und Y sind Listen von unabhängigen und abhängigen Variablen. Iterationen ist ein optionaler Wert, der angibt, wie viele Lösungsversuche maximal stattfinden. Bei Auslassung wird 64 verwendet. Größere Werte führen in der Regel zu höherer Genauigkeit, aber auch zu längeren Ausführungszeiten, und umgekehrt. Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein. Kategorie ist eine Liste von Kategoriecodes Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur solche Datenelemente, deren Kategoriecode in dieser Liste enthalten ist, sind in der Berechnung enthalten. Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: c/(1+a·e-bx)+d) |
|
stat.a, stat.b, stat.c, stat.d |
Regressionskoeffizienten |
|
stat.Resid |
Residuen von der Regression |
|
stat.XReg |
Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit -Kategorien verwendet wurde |
|
stat.YReg |
Liste der Datenpunkte in der modifizierten Y-Liste, die schließlich in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit -Kategorien verwendet wurde |
|
stat.FreqReg |
Liste der Häufigkeiten für stat.XReg und stat.YReg |
|
Katalog > |
|
|
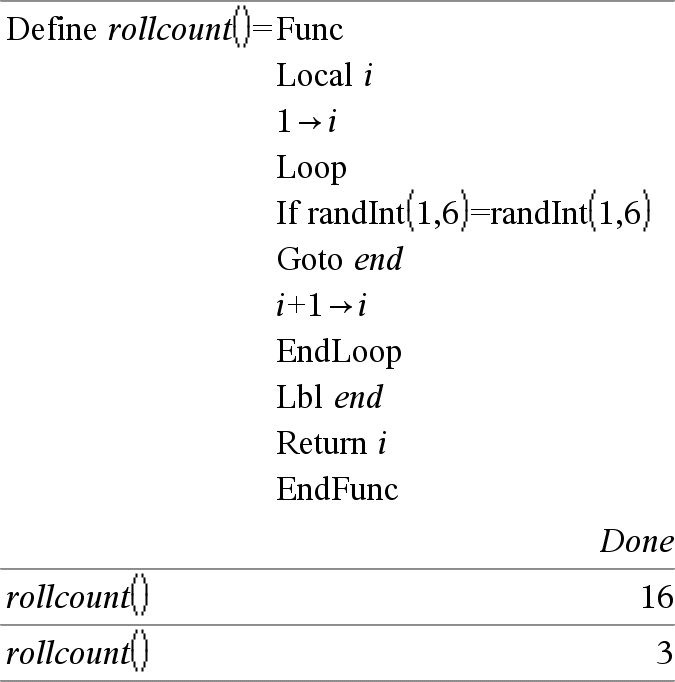
Loop Führt die in Block enthaltenen Anweisungen wiederholt aus. Beachten Sie, dass dies eine Endlosschleife ist. Beenden Sie sie, indem Sie die Anweisung Goto oder Exit in Block ausführen. Block ist eine Folge von Anweisungen, die durch das Zeichen “:” voneinander getrennt sind. Hinweis zum Eingeben des Beispiels: Anweisungen für die Eingabe von mehrzeiligen Programm- und Funktionsdefinitionen finden Sie im Abschnitt „Calculator“ des Produkthandbuchs. |
|
|
Katalog > |
|||||||
|
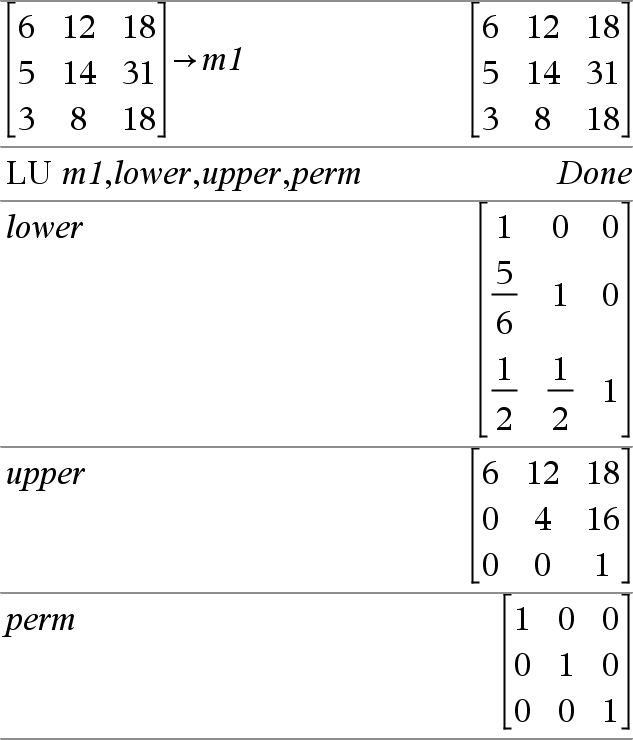
LU Matrix, lMatrix, uMatrix, pMatrix[,Tol] Berechnet die Doolittle LU-Zerlegung (LR-Zerlegung) einer reellen oder komplexen Matrix. Die untere (bzw. linke) Dreiecksmatrix ist in lMatrix gespeichert, die obere (bzw. rechte) Dreiecksmatrix in uMatrix und die Permutationsmatrix (in welcher der bei der Berechnung vorgenommene Zeilentausch dokumentiert ist) in pMatrix. lMatrix · uMatrix = pMatrix · Matrix Sie haben die Option, dass jedes Matrixelement als Null behandelt wird, wenn dessen absoluter Wert geringer als Tol ist. Diese Toleranz wird nur dann verwendet, wenn die Matrix Fließkommaelemente aufweist und keinerlei symbolische Variablen ohne zugewiesene Werte enthält. Anderenfalls wird Tol ignoriert.
Der LU-Faktorisierungsalgorithmus verwendet partielle Pivotisierung mit Zeilentausch. |
|