|
Katalog > |
|
|
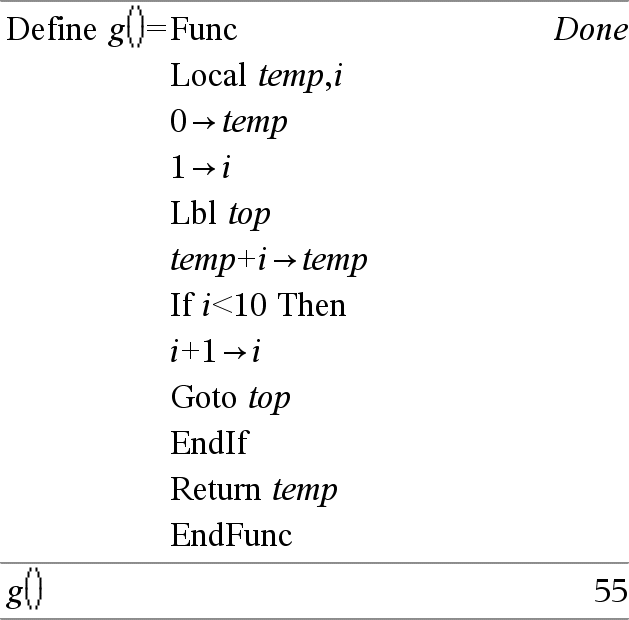
Lbl etiketNavn Definerer en etiket med navnet etiketNavn i en funktion. Du kan anvende en Goto etiketNavn-kommando til at videregive kontrollen til kommandoen lige efter etiketten. EtiketNavn skal opfylde de samme navngivningskrav som et variabelnavn. Bemærk indtastning af eksemplet: For instruktioner til at indtaste programmer over flere linjer og definering af funktioner se Beregninger-afsnittet i din produktvejledning. |
|

|
Katalog > |
|
|
lcm(Værdi1, Værdi2)Þudtryk lcm(Liste1, Liste2)Þliste lcm(Matrix1, Matrix2)Þmatrix Returnerer det mindste fælles multiplum af to argumenter. lcm af to brøker er lcm af deres tællere divideret med gcd af deres nævnere. lcm af brøker med flydende komma er deres produkt. For to lister eller matricer returneres det mindste fælles multiplum af deres tilsvarende elementer. |
|
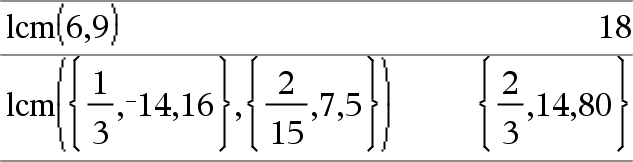
|
Katalog > |
|
|
left(kildeStreng[, Tal])Þstreng Returnerer Antal-tegn fra venstre i tegnstrengen kildeStreng. Hvis du udelader Antal, returneres alle kildeStreng-variable. |
|
|
left(Liste1[, Antal])Þliste Returnerer Antal-elementer til venstre i Liste1. Hvis du udelader Antal, returneres hele Liste1. |
|
|
left(Sammenligning)Þudtryk Returnerer venstre af en ligning eller ulighed. |


|
Katalog > |
|
|
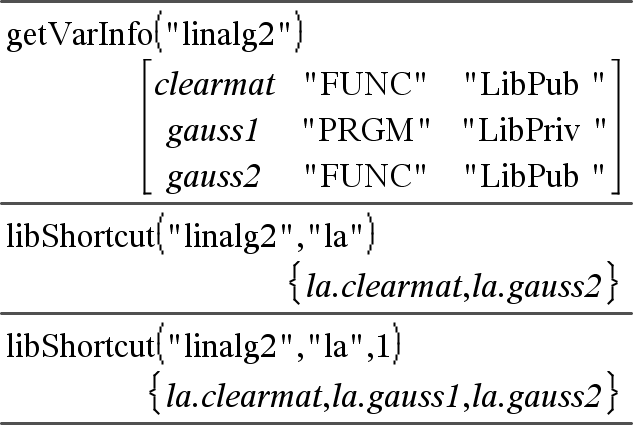
libShortcut(BibNavneStreng, GenvejNavneStreng [, BibPrivFlag])Þ liste med variable Opretter en variabelgruppe i den aktuelle opgave, som indeholder referencer til alle objekter i det specificerede biblioteksdokument bibNavneStreng. Tilføjer også gruppemedlemmerne til variabelmenuen. Du kan henvise til hvert objekt ved brug af GenvejNavneStreng. Sæt BibPrivFlag = 0 for at udelukke private biblioteksobjekter (standard) Sæt BibPrivFlag = 1 for at medtage private biblioteksobjekter For at kopiere en variabelgruppe, se CopyVar på her. For at slette en variabelgruppe, se DelVar på her. |
Dette eksempel forudsætter et korrekt gemt og opdateret biblioteksdokument med navnet, linalg2, som indeholder objekter defineret som clearmat, gauss1, og gauss2.
|
|
Katalog > |
|
|
LinRegBx X, Y[, [Frekv][ Kategori, Medtag]] Beregner den lineære regressiony = a+b·xpå listerne X og Y med hyppigheder Frekv. En sammenfatning af resultaterne lagres i stat.results variable. (her.) Alle lister skal have ens dimensioner med med undtagelse af undtagelse af Medtag. X og Y er lister med uafhængige og afhængige variable. Frekv er en valgfri liste med hyppigheder. Hvert element i Frekvangiver hyppigheden af hændelse for hver tilsvarende X og Y datapunkt. Standardværdien er 1. Alle elementer skal være heltal | 0. Kategory er en liste, der indeholder Medtag er en liste med en eller flere af kategorikoderne. Kun de dataelementer hvis kategorikode er medtaget i denne liste, er medtaget i beregningen. Oplysninger om effekten af tomme elementer i en liste findes “Tomme (ugyldige) elementer,” her. |
|
|
Output-variabel |
Beskrivelse |
|
stat.RegEqn |
Regressionsligning: a+b·x |
|
stat.a, stat.b |
Regressionskoefficienter |
|
stat.r2 |
Forklaringsgraden |
|
stat.r |
Korrelationskoefficient |
|
stat.Resid |
Residualer fra regressionen |
|
stat.XReg |
Liste af datapunkter i den modificerede X-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, kategoriliste,og Medtag kategorier |
|
stat.YReg |
Liste af datapunkter i den modificerede Y-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, kategoriliste,og Medtag kategorier |
|
stat.FreqReg |
Liste med hyppigheder, der svarer til stat.XReg og stat.YReg |
|
Katalog > |
|
|
LinRegMx X, Y[, [Frekv][ Kategori, Medtag]] Beregner den lineære regression y = m· x + b på listerne X og Y med hyppighed Frekv. En sammenfatning af resultaterne lagres i stat.results variable. (her.) Alle lister skal have ens dimensioner med med undtagelse af undtagelse af Medtag. X og Y er lister med uafhængige og afhængige variable. Frekv er en valgfri liste med hyppigheder. Hvert element i Frekvangiver hyppigheden af hændelse for hver tilsvarende X og Y datapunkt. Standardværdien er 1. Alle elementer skal være heltal | 0. Kategory er en liste, der indeholder Medtag er en liste med en eller flere af kategorikoderne. Kun de dataelementer hvis kategorikode er medtaget i denne liste, er medtaget i beregningen. Oplysninger om effekten af tomme elementer i en liste findes “Tomme (ugyldige) elementer,” her. |
|
|
Output-variabel |
Beskrivelse |
|
stat.RegEqn |
Regressionsligning: m·x + b |
|
stat.m, stat.b |
Regressionskoefficienter |
|
stat.r2 |
Forklaringsgraden |
|
stat.r |
Korrelationskoefficient |
|
stat.Resid |
Residualer fra regressionen |
|
stat.XReg |
Liste af datapunkter i den modificerede X-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, kategoriliste,og Medtag kategorier |
|
stat.YReg |
Liste af datapunkter i den modificerede Y-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, kategoriliste,og Medtag kategorier |
|
stat.FreqReg |
Liste med hyppigheder, der svarer til stat.XReg og stat.YReg |
|
Katalog > |
|
|
LinRegtIntervals X,Y[,F[,0[,CNiveau]]] Til hældning. Beregner et niveau C konfidensinterval for hældningen. LinRegtIntervals X,Y[,F[,1,Xværdi[,CNiveau]]] Åbent svar Beregner en forudset y-værdi, et niveau C forudsigelsesinterval for enkle observationer, og et niveau C konfidensinterval til gennemsnits-responsen. En sammenfatning af resultaterne lagres i stat.results variable. (her) Alle lister skal have samme dimension. X og Y er lister med uafhængige og afhængige variable. F er en valgfri liste med hyppighedsværdier. Hvert element i F angiver hyppigheden af forekomster for hvert tilsvarende datapunkt for X og Y. Standardværdien er 1. Alle elementer skal være heltal | 0. Oplysninger om effekten af tomme elementer i en liste findes “Tomme (ugyldige) elementer,” her. |
|
|
Output-variabel |
Beskrivelse |
|
stat.RegEqn |
Regressionsligning: a+b·x |
|
stat.a, stat.b |
Regressionskoefficienter |
|
stat.fg |
Frihedsgrader |
|
stat.r2 |
Forklaringsgraden |
|
stat.r |
Korrelationskoefficient |
|
stat.Resid |
Residualer fra regressionen |
Kun for hældningstypen
|
Output-variabel |
Beskrivelse |
|
[stat.CLower, stat.CUpper] |
Konfidensinterval for hældningen |
|
stat.ME |
Konfidensinterval, fejlmargen |
|
stat.SESlope |
Standarfejl for hældning |
|
stat.s |
Standardfejl for linjen |
Kun for svartype
|
Output-variabel |
Beskrivelse |
|
[stat.CLower, stat.CUpper] |
Konfidensinterval for en middelværdi |
|
stat.ME |
Konfidensinterval, fejlmargen |
|
stat.SE |
Standardfejl for middelværdi |
|
[stat.LowerPred, stat.UpperPred] |
Prædiktionsinterval for en enkelt observation |
|
stat.MEPred |
Prædiktionsintervalsmargin for fejl |
|
stat.SEPred |
standardfejl for prædiktion |
|
Statistik.y |
a + b·XVærdi |
|
katalog > |
|
|
LinRegtTest X,Y[,Frekv[,Hypot]] Beregner en lineær regression ud fra X og Y listerne og en t test på værdien af hældningen b og korrelationskoefficienten r for ligningen y=a+bx. Den tester nulhypotesen H0:b=0 (ækvivalent, r=0) mod en af tre alternative hypoteser. Alle lister skal have samme dimension. X og Y er lister med uafhængige og afhængige variable. Frekv er en valgfri liste med hyppigheder. Hvert element i Frekvangiver hyppigheden af hændelse for hver tilsvarende X og Y datapunkt. Standardværdien er 1. Alle elementer skal være heltal | 0. Hypot er en valgfri værdi, som angiver en af tre alternative hypoteser, mod hvilken nul-hypotesen (H0:b=r=0) vil blive testet. Til Ha: bƒ0 og rƒ0 (standard), sæt Hypot=0 Til Ha: b<0 og r<0, sæt Hypot<=0 Til Ha: b>0 og r>0, sæt Hypot> 0 En sammenfatning af resultaterne lagres i stat.results variable. (her) Oplysninger om effekten af tomme elementer i en liste findes “Tomme (ugyldige) elementer,” her. |
|
|
Output-variabel |
Beskrivelse |
|
stat.RegEqn |
Regressionsligning: a + b·x |
|
stat.t |
t-Statistik for signifikanstest |
|
stat.PVal |
Mindste signifikansniveau, ved hvilket nul-hypotesen kan forkastes |
|
stat.fg |
Frihedsgrader |
|
stat.a, stat.b |
Regressionskoefficienter |
|
stat.s |
Standardfejl for linjen |
|
stat.SESlope |
Standarfejl for hældning |
|
stat.r2 |
Forklaringsgraden |
|
stat.r |
Korrelationskoefficient |
|
stat.Resid |
Residualer fra regressionen |
|
Katalog > |
|
|
Returnerer en løsning for variablene Var1, Var2, ... Det første argument skal kunne beregnes til et system af lineære ligninger eller en enkelt lineær ligning. Eller opstår der en argumentfejl. For eksempel giver beregningen af |
|

|
Katalog > |
|
|
@list(Liste1)Þliste Bemærk: Du kan indsætte denne funktion fra computerens tastatur ved at skrive deltaList(...). Returnerer en liste med differenserne mellem konsekutive elementer i Liste1. Hvert element i Liste1 er subtraheret fra det næste element i Liste1. Den resulterende liste er altid et element kortere end den oprindelige Liste1. |
|
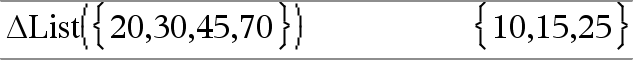
|
Katalog > |
|
|
list4mat(Liste [, elementerPrRække])Þmatrix Returnerer en matrix fyldt rækkevis med elementerne fra Liste. ElementerPrRække angiver antallet af elementer pr. række, hvis den er medtaget. Standard er antallet af elementer i Liste (en række). Hvis Liste ikke udfylder den resulterende matrix, tilføjes nuller. Bemærk: Du kan indsætte denne funktion fra computerens tastatur ved at skrive list@>mat(...). |
|
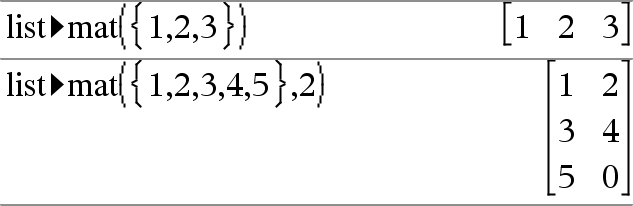
|
/u-taster |
|
|
ln(Værdi1)Þværdi ln(Liste1)Þliste Returnerer den naturlige logaritme til argumentet. Til en liste returneres de naturlige logaritmer af elementerne. |
Hvis kompleks formattilstand er reel:
Hvis kompleks formattilstand er rektangulær:
|
|
ln(kvadratMatrix1)ÞkvadratMatrix Returnerer den naturlige matrixlogaritme af kvadratMatrix1. Dette er ikke det samme som at beregne den naturlige logaritme af hvert element. Oplysninger om beregningsmetoden findes under cos(). KvadratMatrix1 skal være diagonaliserbar. Resultatet indeholder altid tal med flydende decimaler. |
I vinkeltilstanden radian og rektangulært komplekst format:
Du kan se hele resultatet ved at trykke på 5 og derefter bruge 7 og 8 til at bevæge markøren. |


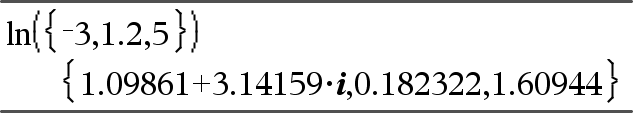

|
Katalog > |
|
|
LnReg X, Y[, [Frekv] [, Kategori, Medtag]] Beregner den lineære regression y = a+b· ln(x)på liste X og Y med hyppighed Frekv. En sammenfatning af resultaterne lagres i stat.results variable. (her.) Alle lister skal have ens dimensioner med undtagelse af Medtag. X og Y er lister med uafhængige og afhængige variable. Frekv er en valgfri liste med hyppigheder. Hvert element i Frekvangiver hyppigheden af hændelse for hver tilsvarende X og Y datapunkt. Standardværdien er 1. Alle elementer skal være heltal | 0. Kategory er en liste, der indeholder Medtag er en liste med en eller flere af kategorikoderne. Kun de dataelementer, hvis kategorikode er medtaget i denne liste, er medtaget i beregningen. Oplysninger om effekten af tomme elementer i en liste findes “Tomme (ugyldige) elementer,” her. |
|
|
Output-variabel |
Beskrivelse |
|
stat.RegEqn |
Regressionsligning: a+b· ln(x) |
|
stat.a, stat.b |
Regressionskoefficienter |
|
stat.r2 |
Koefficient af en lineær forklaringsgrad til transformerede data |
|
stat.r |
Korrelationskoefficient til transformerede data (ln(x), y) |
|
stat.Resid |
Residualer forbundet med eksponentielmodellen |
|
stat.ResidTrans |
Residualer associeret med lineær tilpasning af transformerede data |
|
stat.XReg |
Liste af datapunkter i den modificerede X-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, kategoriliste,og Medtag kategorier |
|
stat.YReg |
Liste af datapunkter i den modificerede Y-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, kategoriliste,og Medtag kategorier |
|
stat.FreqReg |
Liste med hyppigheder, der svarer til stat.XReg og stat.YReg |
|
Katalog > |
|
|
Local Var1[, Var2] [, Var3] ... Erklærer de angivne var som lokale variable. Disse variable eksisterer kun under beregning af en funktion og slettes, når eksekveringen af funktionen afsluttes. Bemærk: Lokale variable sparer hukommelse, fordi kun eksisterer midlertidigt. De forstyrrer heller ikke de eksisterende globale variabelværdier. Lokale variable skal anvendes til For-løkker og midlertidig lagring af variabelværdier i en flerlinjefunktion da modifikationer af globale ikke er tilladt i en funktion. Bemærk indtastning af eksemplet: For instruktioner til at indtaste programmer over flere linjer og definering af funktioner se Beregninger-afsnittet i din produktvejledning. |
|
|
Catalog > |
|
|
Låser de angivne variable eller den angivne variabelgruppe. Låste variable kan ikke redigeres eller slettes. Du kan ikke låse eller oplåse systemvariablen Ans, og du kan ikke låse systemvariabelgrupperne stat. eller tvm. Bemærk: Kommandoen Lås (Lock) rydder Fortryd/Annuller Fortryd-historikken, når den anvendes på ulåste variable. |
|

|
/s-taster |
|
|
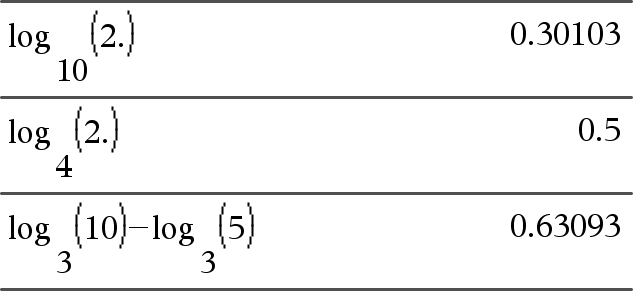
log(Liste1[,Værdi2])Þlist
Returner -Udtr2-talslogaritmen til argumentet. Bemærk: Se også Log-skabelon, her. Ved en liste returneres Udtr2-talslogaritmen til elementerne. Hvis Udtr2 udelades, anvendes 10-talslogaritmen. |
Hvis kompleks formattilstand er reel:
Hvis kompleks formattilstand er rektangulær:
|
|
Returnerer matrix Værdi2-logaritmen til kvadratMatrix1. Dette er ikke det samme som at beregne Værdi2-talslogaritmen til hvert element Oplysninger om beregningsmetoden findes i cos(). KvadratMatrix1 skal være diagonaliserbar. Resultatet indeholder altid tal med flydende decimaler. Hvis tal-argumentet udelades, anvendes 10-talslogaritmen. |
I vinkeltilstanden radian og rektangulært komplekst format:
Du kan se hele resultatet ved at trykke på 5 og derefter bruge 7 og 8 til at bevæge markøren. |



|
Katalog > |
|
|
Logistik X, Y[, [Frekv] [, Kategori, Medtag]] Beregner den logistiske regressiony = (c/(1+a·e-bx))på listerne X og Y med hyppighed Frekv. En sammenfatning af resultaterne lagres i stat.results variable. (her.) Alle lister skal have ens dimensioner med undtagelse af Medtag. X og Y er lister med uafhængige og afhængige variable. Frekv er en valgfri liste med hyppigheder. Hvert element i Frekvangiver hyppigheden af hændelse for hver tilsvarende X og Y datapunkt. Standardværdien er 1. Alle elementer skal være heltal | 0. Kategory er en liste, der indeholder Medtag er en liste med en eller flere af kategorikoderne. Kun de dataelementer hvis kategorikode er medtaget i denne liste, er medtaget i beregningen. Oplysninger om effekten af tomme elementer i en liste findes “Tomme (ugyldige) elementer,” her. |
|
|
Output-variabel |
Beskrivelse |
|
stat.RegEqn |
Regressionsligning: c/(1+a·e-bx) |
|
stat.a, stat.b, stat.c |
Regressionskoefficienter |
|
stat.Resid |
Residualer fra regressionen |
|
stat.XReg |
Liste af datapunkter i den modificerede X-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, kategoriliste,og Medtag kategorier |
|
stat.YReg |
Liste af datapunkter i den modificerede Y-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, kategoriliste,og Medtag kategorier |
|
stat.FreqReg |
Liste med hyppigheder, der svarer til stat.XReg og stat.YReg |
|
Katalog > |
|
|
LogisticD X, Y [, [Iterationer], [Frekv] [, Kategori, Medtag] ] Beregner den logistiske regression y = (c/(1+a·e-bx)+d) på listerne X og Y med hyppighed Frekv, ved brug af et angivet tal fra Iterationer. En sammenfatning af resultaterne lagres i stat.results variable. (her.) Alle lister skal have ens dimensioner med undtagelse af Medtag. X og Y er lister med uafhængige og afhængige variable. Iterationer er en valgfri værdi, som angiver det maksimale antal gange en løsning vil forsøges. Hvis udeladt, anvendes 64. Typisk resulterer større værdier i større nøjagtighed men længere eksekveringstider og omvendt. Frekv er en valgfri liste med hyppigheder. Hvert element i Frekvangiver hyppigheden af hændelse for hver tilsvarende X og Y datapunkt. Standardværdien er 1. Alle elementer skal være heltal | 0. Kategory er en liste, der indeholder Medtag er en liste med en eller flere af kategorikoderne. Kun de dataelementer hvis kategorikode er medtaget i denne liste, er medtaget i beregningen. Oplysninger om effekten af tomme elementer i en liste findes “Tomme (ugyldige) elementer,” her. |
|
|
Output-variabel |
Beskrivelse |
|
stat.RegEqn |
Regressionsligning: c/(1+a·e-bx) +d) |
|
stat.a, stat.b, stat.c, stat.d |
Regressionskoefficienter |
|
stat.Resid |
Residualer fra regressionen |
|
stat.XReg |
Liste af datapunkter i den modificerede X-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, Kategori liste og Medtag Kategorier |
|
stat.YReg |
Liste af datapunkter i den modificerede Y-liste der faktisk bruges i regressionen ud fra begrænsninger i Frekv, Kategori liste og Medtag Kategorier |
|
stat.FreqReg |
Liste med hyppigheder, der svarer til stat.XReg og stat.YReg |
|
Katalog > |
|
|
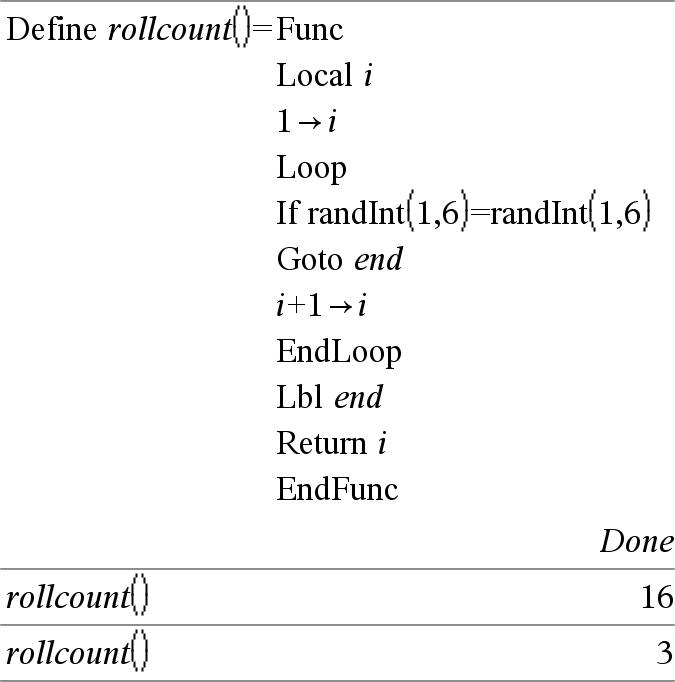
Loop Eksekverer gentagne gange sætningerne i Blok. Bemærk, at løkken eksekveres uendeligt, medmindre en Goto eller Exit-kommando eksekveres i Blok. Blok er en sekvens af sætninger adskilt med kolon. Bemærk indtastning af eksemplet: For instruktioner til at indtaste programmer over flere linjer og definering af funktioner se Beregninger-afsnittet i din produktvejledning. |
|
|
Katalog > |
||||||||||
|
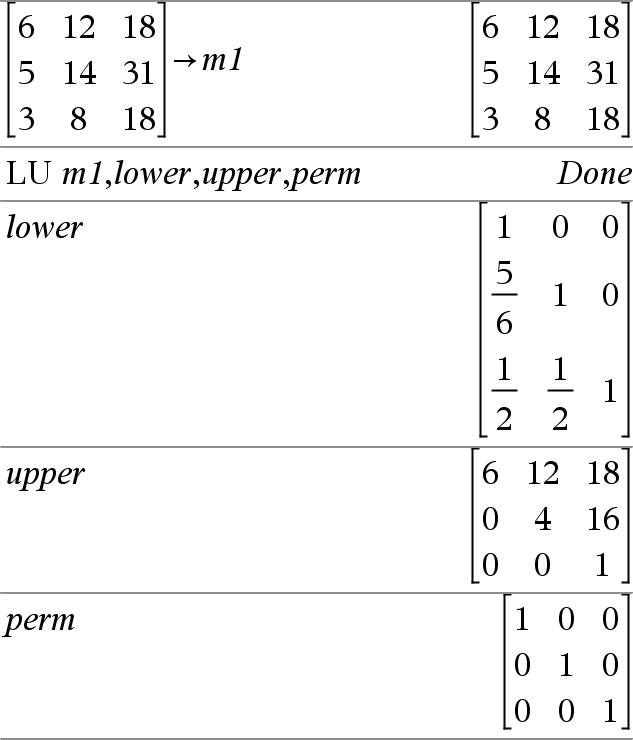
LU Matrix, lMatrix, uMatrix, pMatrix[,Tol] Beregner Doolittle LU (nedre-øvre) opløsningen af en reel eller kompleks matrix. Den nedre triangulære matrix lagres i lMatrix, den øvre triangulære matrix i uMatrix, og permutationsmatricen (der beskriver de foretagne rækkeombytninger under beregningen) i pMatrix. lMatrix · uMatrix = pMatrix · matrix Ethvert matricelement kan valgfrit behandles som nul, hvis dets absolutte værdi er mindre end Tol. Denne tolerance anvendes kun, hvis matricen har elementer med flydende decimaler og ikke indeholder symbolske variable, der ikke er tildelt en værdi. Ellers ignoreres Tol.
LU-algoritmen til faktoropløsning anvender partiel pivotering med rækkeombytninger. |
|