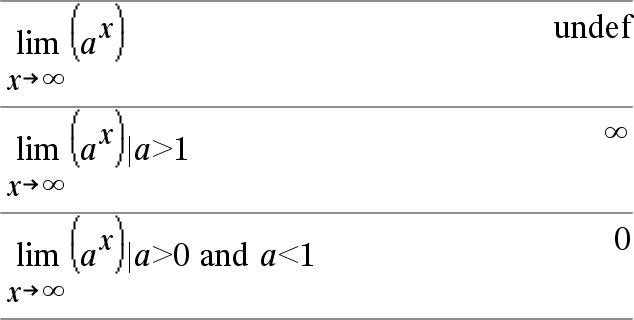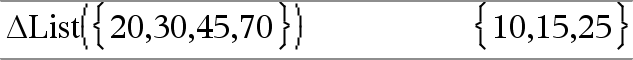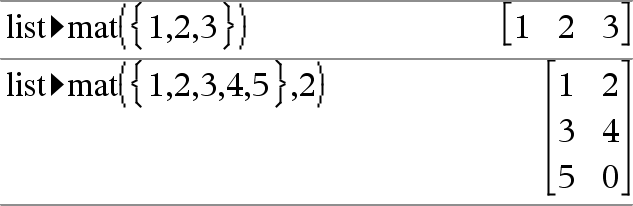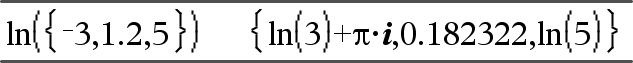Catalog > 
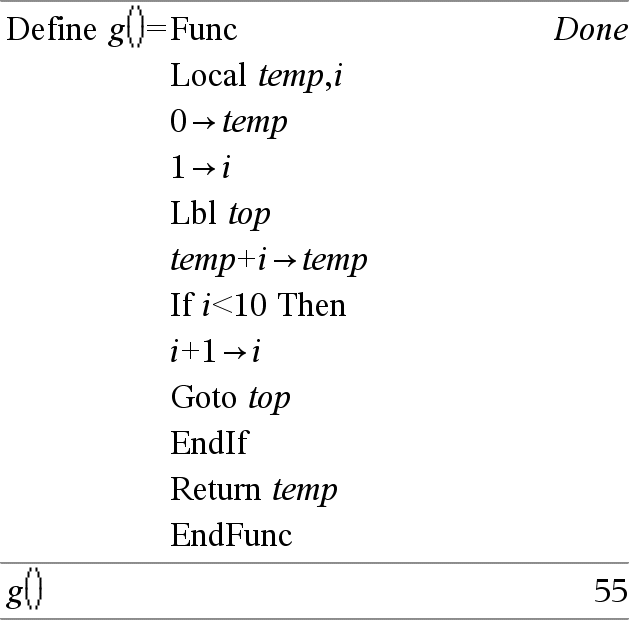
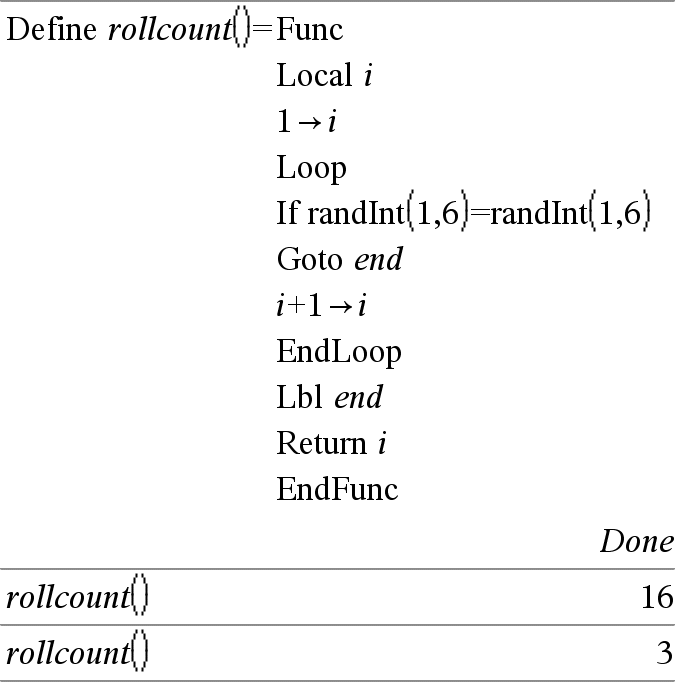
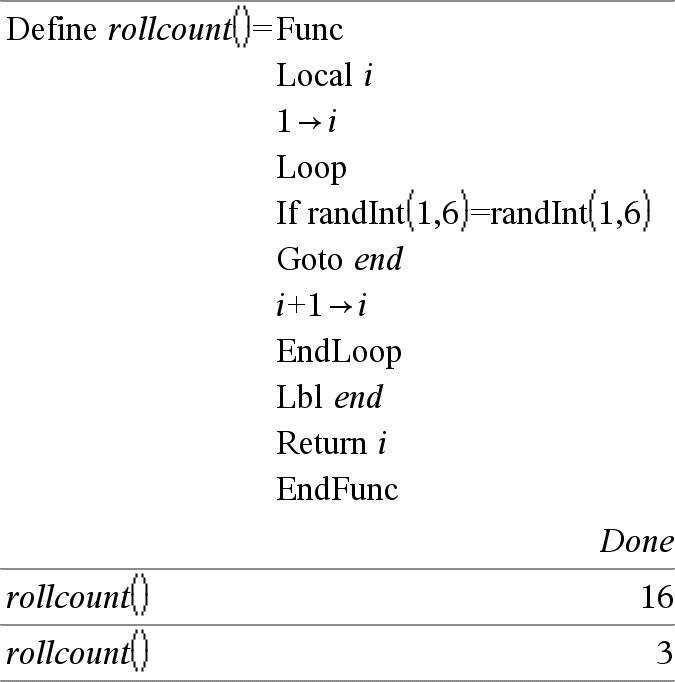
Lbl labelName
Defines a label with the name labelName within a function.
You can use a Goto labelName instruction to transfer control to the instruction immediately following the label.
labelName must meet the same naming requirements as a variable name.
Note for entering the example: For instructions on entering multi-line program and function definitions, refer to the Calculator section of your product guidebook.