|
Katalog > |
|
|
Matrix1TÞmatris Ger den komplexkonjugerade transponeringen av Matrix1. Obs: Du kan infoga denna operator med datorns tangentbord genom att skriva @t. |
|

|
µ tangent |
|
|
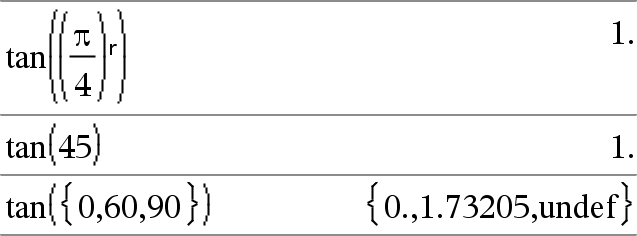
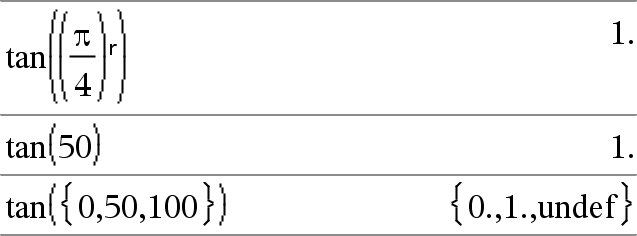
tan(Value1)Þvärde tan(List1)Þlista
tan(List1) ger en lista på tangensen för alla element i List1. Obs: Argumentet tolkas som en vinkel i antingen grader, nygrader eller radianer beroende på det aktuella vinkelläget. Du kan använda ¡, G eller R för att tillfälligt överstyra vinkelläget. |
I vinkelläget Grader:
I vinkelläget Nygrader:
I vinkelläget Radianer:
|
|
tan(squareMatrix1)ÞkvadratMatris Ger matrisen med tangensen för squareMatrix1. Detta är inte detsamma som att beräkna tangensen för varje element. Se cos() för information om beräkningsmetoden. squareMatrix1 måste vara möjlig att diagonalisera. Resultatet visas alltid i flyttalsform. |
I vinkelläget Radianer:
|


|
µ tangent |
|
|
tan/(Value1)Þvärde tan/(List1)Þlista
tan/(List1) ger en lista på den inversa tangensen för varje element i List1. Obs: Resultatet erhålls som en vinkel i grader, nygrader eller radianer beroende på det aktuella vinkelläget. Obs: Du kan infoga denna funktion med datorns tangentbord genom att skriva arctan(...). |
I vinkelläget Grader:
I vinkelläget Nygrader:
I vinkelläget Radianer:
|
|
tan/(squareMatrix1)ÞkvadratMatris Ger matrisen med invers tangens för squareMatrix1. Detta är inte detsamma som att beräkna invers tangens för varje element. Se cos() för information om beräkningsmetoden. squareMatrix1 måste vara möjlig att diagonalisera. Resultatet visas alltid i flyttalsform. |
I vinkelläget Radianer:
|


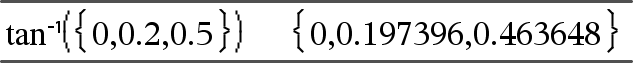

|
Katalog > |
|
|
tanh(Value1)Þvärde tanh(List1)Þlista
tanh(List1) ger en lista på den hyperboliska tangensen för varje element i List1. |
|
|
tanh(squareMatrix1)ÞkvadratMatris Ger matrisen med hyperbolisk tangens för squareMatrix1. Detta är inte detsamma som att beräkna hyperbolisk tangens för varje element. Se cos() för information om beräkningsmetoden. squareMatrix1 måste vara möjlig att diagonalisera. Resultatet visas alltid i flyttalsform. |
I vinkelläget Radianer:
|


|
Katalog > |
|
|
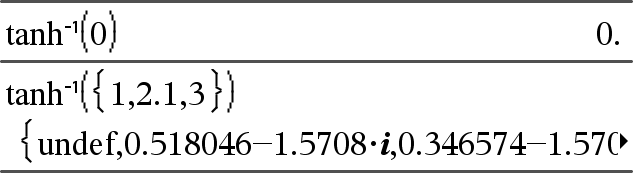
tanh/(Value1)Þvärde tanh/(List1)Þlista
tanh/(List1) ger en lista på invers hyperbolisk tangens för varje element i List1. Obs: Du kan infoga denna funktion med datorns tangentbord genom att skriva arctanh(...). |
I Rektangulärt komplext format:
För att se hela resultatet, tryck på 5 och använd sedan 7 och 8 för att flytta markören. |
|
tanh/(squareMatrix1)ÞkvadratMatris Ger matrisen med invers hyperbolisk tangens för squareMatrix1. Detta är inte detsamma som att beräkna invers hyperbolisk tangens för varje element. Se cos() för information om beräkningsmetoden. squareMatrix1 måste vara möjlig att diagonalisera. Resultatet visas alltid i flyttalsform. |
I vinkelläget Radianer och i Rektangulärt komplext format:
För att se hela resultatet, tryck på 5 och använd sedan 7 och 8 för att flytta markören. |

|
Katalog > |
|
|
tCdf(lowBound,upBound,df)Þtal om lowBound och upBound är tal, lista om lowBound och upBound är listor Beräknar sannolikheten för Student-t-fördelning mellan lowBound och upBound för den specificerade frihetsgraden df.
|
|
|
Katalog > |
|||||||
|
Programmeringskommando: Pausar programmet och visar teckensträngen frågeSträng i en dialogruta. När användaren väljer OK fortsätter exekveringen av programmet. Det valfria argumentet flagga kan vara ett valfritt uttryck.
Om programmet behöver ett svar som skrivs in av användaren, se Obs: Du kan använda detta kommando inom ett användardefinierat program, men inte inom en funktion. |
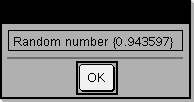
Definiera ett program som pausar för att visa vart och ett av fem slumptal i en dialogruta. Inom mallen Prgm...EndPrgm template, fullborda varje rad genom att trycka på @ i stället för ·. På datorns tangentbord, håll ned Alt och tryck på Enter.
Define text_demo()=Prgm For i,1,5 strinfo:=”Random number “ & string(rand(i)) Text strinfo EndFor EndPrgm
Kör programmet: text_demo()
Exempel på en dialogruta:
|
|
Se If, här. |
|
|
|
|
|
Katalog > |
|
|
tInterval List[,Freq[,CLevel]] (Indatalista) tInterval v,sx,n[,CLevel] (Summary stats indata) Beräknar ett t-konfidensintervall. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.CLower, stat.CUpper |
Konfidensintervall för ett okänt populationsmedelvärde |
|
stat.x |
Urvalsmedelvärde för datasekvensen från den slumpmässiga normalfördelningen |
|
stat.ME |
Felmarginal |
|
stat.df |
Frihetsgrader |
|
stat.sx |
Standardavvikelse för urvalet |
|
stat.n |
Längden på datasekvenser med urvalsmedelvärde |
|
Katalog > |
|
|
tInterval_2Samp List1,List2[,Freq1[,Freq2[,CLevel[,Pooled]]]] (Indatalista) tInterval_2Samp v1,sx1,n1,v2,sx2,n2[,CLevel[,Pooled]] (Summary stats indata) Beräknar ett 2-sampel t-konfidensintervall. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Pooled=1 slår samman varianser, Pooled=0 slår inte samman varianser. För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.CLower, stat.CUpper |
Konfidensintervall innehållande konfidensnivån för fördelningens sannolikhet |
|
stat.x1-x2 |
Urvalsmedelvärden för datasekvenserna från den slumpmässiga normalfördelningen |
|
stat.ME |
Felmarginal |
|
stat.df |
Frihetsgrader |
|
stat.x1, stat.x2 |
Urvalsmedelvärden för datasekvenserna från den slumpmässiga normalfördelningen |
|
stat.sx1, stat.sx2 |
Urvalets standardavvikelser för List 1 och List 2 |
|
stat.n1, stat.n2 |
Antalet samplingar i datasekvenser |
|
stat.sp |
Den sammanslagna standardavvikelsen. Beräknas när Pooled = YES. |
|
Katalog > |
|
|
tPdf(XVal,df)Þtal om XVal är ett tal, lista om XVal är en lista Beräknar värde hos täthetsfunktionen (pdf) för Student-t-fördelningen vid ett specificerat x-värde med den specificerade frihetsgraden df. |
|
|
Katalog > |
|
|
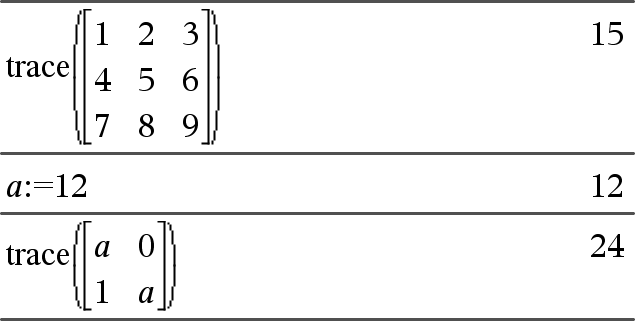
trace(squareMatrix)Þvärde Ger spåret (summan av alla elementen på huvuddiagonalen) av squareMatrix. |
|
|
Katalog > |
|
|
block1 Else block2 Exekverar block1 såvida inte ett fel uppstår. Programexekveringen överförs till block2 om ett fel uppstår i block1. Systemvariabeln errCode innehåller felkoden som låter programmet utföra återhämtning efter fel. För en lista på felkoder, se “Felkoder och meddelanden” (här). block1 och block2 kan vara antingen ett enstaka påstående eller en serie av påståenden separerade med tecknet “:”. Obs för att mata in exemplet: Se avsnittet Räknare i produkthandboken för instruktioner om hur du anger multiline-program och funktionsdefinitioner. |
|
|
För att se kommandona Try, ClrErr och PassErr i arbete, mata in programmet eigenvals() som visas till höger. Kör programmet genom att exekvera vart och ett av följande uttryck.
|
Definiera eigenvals(a,b)=Prgm © Programmet eigenvals(A,B) visar egenvärdena för A·B Try Disp "A= ",a Disp "B= ",b Disp " " Disp "Eigenvalues A·B are:",eigVl(a*b) Else If errCode=230 Then Disp "Error: Product of A·B must be a square matrix" ClrErr Else PassErr EndIf EndTry EndPrgm
|

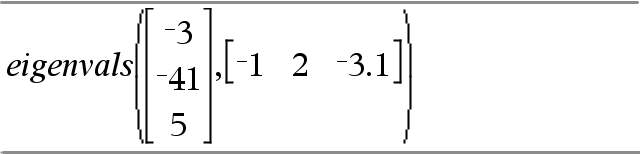
|
Katalog > |
|
|
tTest m0,List[,Freq[,Hypoth]] (Indatalista) tTest m0,x,sx,n,[Hypoth] (Summary stats indata) Utför ett hypotestest för ett okänt populationsmedelvärde, m, när populationens standardavvikelse, s, är okänd. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Testa H0: m = m0, mot en av följande: För Ha: m < m0, ställ Hypoth<0 För Ha: m ƒ m0 (förinställning), ställ Hypoth=0 För Ha: m > m0, ställ Hypoth>0 För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.t |
(x N m0) / (stdev / sqrt(n)) |
|
stat.PVal |
Lägsta signifikansnivå vid vilken nollhypotesen kan förkastas |
|
stat.df |
Frihetsgrader |
|
stat.x |
Urvalsmedelvärde för datasekvensen i List |
|
stat.sx |
Urvalets standardavvikelse för datasekvensen |
|
stat.n |
Urvalets storlek |
|
Katalog > |
|
|
tTest_2Samp List1,List2[,Freq1[,Freq2[,Hypoth[,Pooled]]]] (Indatalista) tTest_2Samp v1,sx1,n1,v2,sx2,n2[,Hypoth[,Pooled]] (Summary stats indata) Beräknar ett 2-sampel t-test. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Testa H0: m1 = m2, mot en av följande: För Ha: m1< m2, ställ Hypoth<0 För Ha: m1ƒ m2 (förinställning), ställ Hypoth=0 För Ha: m1> m2, ställ Hypoth>0 Pooled=1 slår samman varianser, Pooled=0 slår inte samman varianser. För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
Resultatvariabel |
Beskrivning |
|
stat.t |
Standardnormalvärde beräknat för skillnaden mellan medelvärden |
|
stat.PVal |
Lägsta signifikansnivå vid vilken nollhypotesen kan förkastas |
|
stat.df |
Frihetsgrader hos t-statistiken |
|
stat.x1, stat.x2 |
Medelvärden hos urvalet i datasekvenserna i List 1 och List 2 |
|
stat.sx1, stat.sx2 |
Standardavvikelser hos urvalet i datasekvenserna i List 1 och List 2 |
|
stat.n1, stat.n2 |
Storlek på urvalen |
|
stat.sp |
Den sammanslagna standardavvikelsen. Beräknad när Pooled=1. |
|
Katalog > |
|
|
tvmFV(N,I,PV,Pmt,[PpY],[CpY],[PmtAt])Þvärde Finansiell funktion som beräknar det framtida värdet på pengar. Obs: Argumenten som används i TVM-funktionerna beskrivs i tabellen över TVM-argumenten, här. Se även amortTbl(), här. |
|
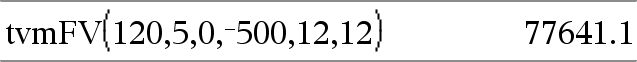
|
Katalog > |
|
|
tvmI(N,PV,Pmt,FV,[PpY],[CpY],[PmtAt])Þvärde Finansiell funktion som beräknar räntesatsen per år. Obs: Argumenten som används i TVM-funktionerna beskrivs i tabellen över TVM-argumenten, här. Se även amortTbl(), här. |
|
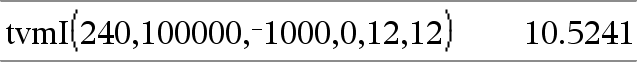
|
Katalog > |
|
|
tvmN(I,PV,Pmt,FV,[PpY],[CpY],[PmtAt])Þvärde Finansiell funktion som beräknar antalet betalningsperioder. Obs: Argumenten som används i TVM-funktionerna beskrivs i tabellen över TVM-argumenten, här. Se även amortTbl(), här. |
|
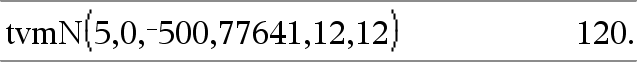
|
Katalog > |
|
|
tvmPmt(N,I,PV,FV,[PpY],[CpY],[PmtAt])Þvärde Finansiell funktion som beräknar beloppet på varje betalning. Obs: Argumenten som används i TVM-funktionerna beskrivs i tabellen över TVM-argumenten, här. Se även amortTbl(), här. |
|
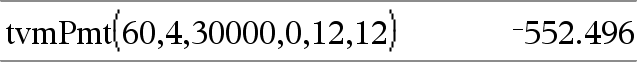
|
Katalog > |
|
|
tvmPV(N,I,Pmt,FV,[PpY],[CpY],[PmtAt])Þvärde Finansiell funktion som beräknar nuvärdet. Obs: Argumenten som används i TVM-funktionerna beskrivs i tabellen över TVM-argumenten, här. Se även amortTbl(), här. |
|
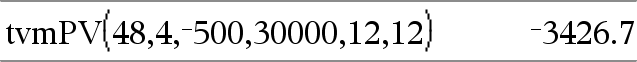
|
Beskrivning |
Datatyp |
|
|
N |
Antal betalningsperioder |
reellt tal |
|
I |
Årlig räntesats |
reellt tal |
|
PV |
Nuvärde |
reellt tal |
|
Pmt |
Betalningsbelopp |
reellt tal |
|
FV |
Framtida värde |
reellt tal |
|
PpY |
Antal betalningar per år, förinställning = 1 |
heltal > 0 |
|
CpY |
Ränteperioder per år, förinställning = 1 |
heltal > 0 |
|
PmtAt |
Betalning som skall betalas i slutet (end) eller i början (beginning) av varje period, förinställning = end |
heltal (0 = end, 1 = beginning) |
* Dessa argumentnamn avseende tidsjusterat pengavärde påminner om namnen på TVM-variablerna (till exempel, tvm.pv och tvm.pmt) som används av Finance Solver i applikationen Calculator. Finansiella funktioner lagrar dock inte sina argumentvärden eller resultat i TVM-variablerna.
|
Katalog > |
|
|
TwoVar X, Y[, [Freq] [, Category, Include]] Utför tvåvariabelstatistik. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Alla listor utom Include måste ha samma dimensioner. X och Y är listor på oberoende och beroende variabler. Freq är en frivillig lista på frekvensvärden. Varje element i Freq specificerar frekvensen för varje motsvarande X- och Y-datapunkt. Det förinställda värdet är 1. Alla element måste vara heltal | 0. Category är en lista på Include är en lista på en eller flera av kategorikoderna. Endast de dataobjekt vars kategorikod är med på listan tas med i beräkningen. Ett tomt element i någon av listorna X, Freq eller Category resulterar i ett tomrum för motsvarande element i dessa listor. Ett tomt element i någon av listorna X1 till och med X20 resulterar i ett tomrum för motsvarande element i dessa listor. För mer information om tomma element, se här. |
|
|
Resultatvariabel |
Beskrivning |
|
stat.v |
Medelvärde av x-värden |
|
stat.Gx |
Summa av x-värden |
|
stat.Gx2 |
Summa av x2-värden |
|
stat.sx |
Standardavvikelse för x (sampling) |
|
stat.sx |
Standardavvikelse för x (population) |
|
stat.n |
Antal datapunkter |
|
stat.w |
Medelvärde av y-värden |
|
stat.Gy |
Summa av y-värden |
|
stat.Gy2 |
Summa av y2-värden |
|
stat.sy |
Standardavvikelse för y (sampling) |
|
stat.sy |
Populationens standardavvikelse för y |
|
stat.Gxy |
Summa av x·y-värden |
|
stat.r |
Korrelationskoefficient |
|
stat.MinX |
Minsta x-värde |
|
stat.Q1X |
Undre kvartil för x |
|
stat.MedianX |
Median för x |
|
stat.Q3X |
Övre kvartil för x |
|
stat.MaxX |
Största x-värde |
|
stat.MinY |
Minsta y-värde |
|
stat.Q1Y |
Undre kvartil för y |
|
stat.MedY |
Median för y |
|
stat.Q3Y |
Övre kvartil för y |
|
stat.MaxY |
Största y-värde |
|
stat.G(x-v)2 |
Kvadratsumma för avvikelser från medelvärdet på x |
|
stat.G(y-w)2 |
Kvadratsumma för avvikelser från medelvärdet på y |