|
Catalogus > |
|
|
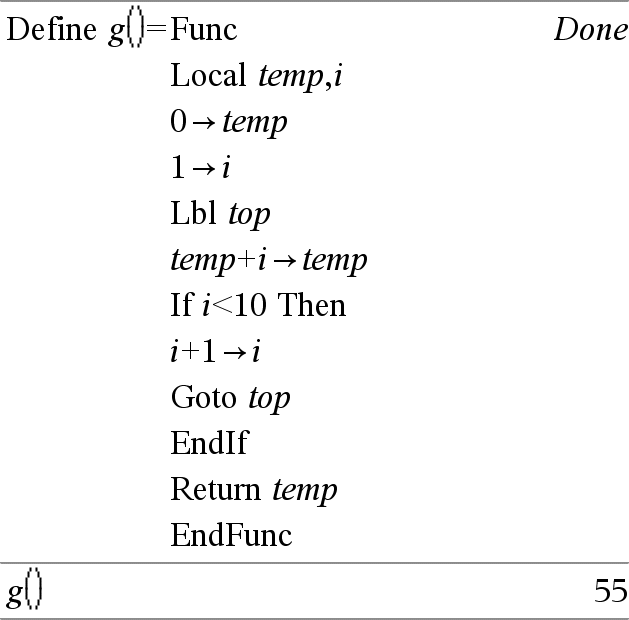
Lbl labelNaam Definieert een label met de naam labelNaam binnen een functie. U kunt een Goto labelNaam-instructie gebruiken om de besturing naar de instructie onmiddellijk na het label te brengen. labelNaam moet aan dezelfde naamgevingsvereisten voldoen als een variabelenaam. Opmerking bij het invoeren van het voorbeeld: Instructies over het invoeren van programma's met meerdere regels en functiedefinities vindt u in het hoofdstuk Rekenmachine van de handleiding van uw product. |
|

|
Catalogus > |
|
|
lcm(Getal1, Getal2)Þuitdrukking lcm(Lijst1, Lijst2)Þlijst lcm(Matrix1, Matrix2)Þmatrix Geeft het kleinste gemene veelvoud van de twee argumenten. De lcm van twee breuken is de lcm van hun tellers gedeeld door de gcd (grootste gemene veelvoud) van hun noemers. De lcm van breukgetallen met een drijvende komma is hun product. Geeft bij twee lijsten of matrices de kleinste gemene veelvouden van de overeenkomstige elementen. |
|
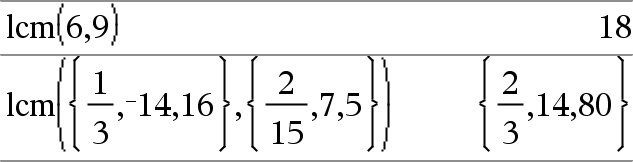
|
Catalogus > |
|
|
left(bronString[, Aantal])Þstring Geeft het meest linkse Aantal tekens in tekenreeks bronString. Als u Aantal weglaat, wordt de hele bronString gegeven. |
|
|
left(Lijst1[, Aantal])Þlijst Geeft het meest linkse Aantal elementen in Lijst1. Als u Aantal weglaat, wordt de hele Lijst1 gegeven. |
|
|
left(Vergelijken)Þuitdrukking Geeft het linkerlid van een vergelijking of ongelijkheid. |


|
Catalogus > |
|
|
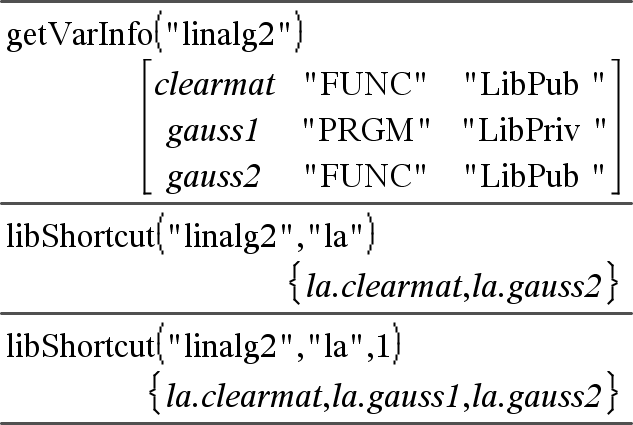
libShortcut(BibliotheekNaamString, SnelNaamString [, LibPrivVlag])Þlijst met variabelen Creëert een variabelegroep in de huidige opgave die verwijzingen naar alle objecten in het gespecificeerde bibliotheekdocument BibliotheekNaamString bevat. Voegt de groepsleden tevens toe aan het Variabelen-menu. U kunt vervolgens naar elk object verwijzen met behulp van zijn SnelNaamString. Stel LibPrivVlag=0 om persoonlijke bibliotheekobjecten uit te sluiten (standaardinstelling) Stel LibPrivVlag=1 om persoonlijke bibliotheekobjecten op te nemen Zie voor het kopiëren van een variabelegroep CopyVar (hier). Zie voor het wissen van een variabelegroep DelVar (hier). |
In dit voorbeeld wordt uitgegaan van een op de juiste manier opgeslagen en vernieuwd bibliotheekdocument met de naam linalg2 dat de gedefinieerde objecten clearmat, gauss1 en gauss2 bevat.
|
|
Catalogus > |
|
|
LinRegBx X,Y[,[Freq][,Categorie,Opnemen]] Berekent de lineaire regressiey = a+b·xop de lijsten X en Y met frequentie Freq. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Alle lijsten moeten gelijke afmetingen hebben, behalve Opnemen. X en Y zijn lijsten met onafhankelijke en afhankelijke variabelen. Freq is een optionele lijst met frequentiewaarden. Elk element in Freq specificeert de frequentie waarmee elk overeenkomstig X- en Y-gegeven voorkomt. De standaardwaarde is 1. Alle elementen moeten gehele getallen | 0 zijn. Categorie is een lijst met Opnemen is een lijst met één of meer van de categoriecodes. Alleen de gegevens waarvan de categoriecode is opgenomen in deze lijst worden opgenomen in de berekening. Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: a+b·x |
|
stat.a, stat.b |
Regressiecoëfficiënten |
|
stat.r2 |
Determinatiecoëfficiënt |
|
stat.r |
Correlatiecoëfficiënt |
|
stat.Resid |
Residuen uit de regressie |
|
stat.XReg |
Lijst van de gegevens in de gemodificeerde XLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.YReg |
Lijst van gegevens in de gemodificeerde YLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.FreqReg |
Lijst van frequenties die corresponderen met stat.XReg en stat.YReg |
|
Catalogus > |
|
|
LinRegMx X,Y[,[Freq][,Categorie,Opnemen]] Berekent de lineaire regressie y = m·x+b op de lijsten X en Y met frequentie Freq. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Alle lijsten moeten gelijke afmetingen hebben, behalve Opnemen. X en Y zijn lijsten met onafhankelijke en afhankelijke variabelen. Freq is een optionele lijst met frequentiewaarden. Elk element in Freq specificeert de frequentie waarmee elk overeenkomstig X- en Y-gegeven voorkomt. De standaardwaarde is 1. Alle elementen moeten gehele getallen | 0 zijn. Categorie is een lijst met Opnemen is een lijst met één of meer van de categoriecodes. Alleen de gegevens waarvan de categoriecode is opgenomen in deze lijst worden opgenomen in de berekening. Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: m·x+b |
|
stat.m, stat.b |
Regressiecoëfficiënten |
|
stat.r2 |
Determinatiecoëfficiënt |
|
stat.r |
Correlatiecoëfficiënt |
|
stat.Resid |
Residuen uit de regressie |
|
stat.XReg |
Lijst van de gegevens in de gemodificeerde XLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.YReg |
Lijst van gegevens in de gemodificeerde YLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.FreqReg |
Lijst van frequenties die corresponderen met stat.XReg en stat.YReg |
|
Catalogus > |
|
|
LinRegtIntervals X,Y[,F[,0[,CNiv]]] Voor helling. Berekent een niveau C betrouwbaarheidsinterval voor de helling. LinRegtIntervals X,Y[,F[,1,Xwaarde[,CNiv]]] Voor respons. Berekent een voorspelde y-waarde, een niveau C voorspellingsinterval voor één observatie en een niveau C betrouwbaarheidsinterval voor de gemiddelde respons. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Alle lijsten moeten gelijke afmetingen hebben. X en Y zijn lijsten met onafhankelijke en afhankelijke variabelen. F is een optionele lijst met frequentiewaarden. Elk element in F specificeert de frequentie waarmee elk overeenkomstig X- en Y-gegeven voorkomt. De standaardwaarde is 1. Alle elementen moeten gehele getallen | 0 zijn. Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: a+b·x |
|
stat.a, stat.b |
Regressiecoëfficiënten |
|
stat.df |
Vrijheidsgraden |
|
stat.r2 |
Determinatiecoëfficiënt |
|
stat.r |
Correlatiecoëfficiënt |
|
stat.Resid |
Residuen uit de regressie |
Alleen voor het type Hellling
|
Uitvoervariabele |
Beschrijving |
|
[stat.CLower, stat.CUpper] |
Betrouwbaarheidsinterval voor de helling |
|
stat.ME |
Foutmarge betrouwbaarheidsinterval |
|
stat.SESlope |
Standaardfout van helling |
|
stat.s |
Standaardfout van de lijn |
Alleen voor het type Respons
|
Uitvoervariabele |
Beschrijving |
|
[stat.CLower, stat.CUpper] |
Betrouwbaarheidsinterval voor de gemiddelde respons |
|
stat.ME |
Foutmarge betrouwbaarheidsinterval |
|
stat.SE |
Standaardfout van de gemiddelde respons |
|
[stat.LowerPred, stat.UpperPred] |
Voorspellingsinterval voor één observatie |
|
stat.MEPred |
Foutmarge voor voorspellingsinterval |
|
stat.SEPred |
Standaardfout voor voorspelling |
|
stat.y |
a + b·XWaarde |
|
Catalogus > |
|
|
LinRegtTest X,Y[,Freq[,Hypoth]] Berekent een lineaire regressie op de X- en Y-lijsten en een t-toets op de waarde van helling b en de correlatiecoëfficiënt r voor de vergelijking y=a+bx. Hij toetst de nulhypothese H0:b=0 (equivalent r=0) tegen één van de drie alternatieve hypothesen. Alle lijsten moeten gelijke afmetingen hebben. X en Y zijn lijsten met onafhankelijke en afhankelijke variabelen. Freq is een optionele lijst met frequentiewaarden. Elk element in Freq specificeert de frequentie waarmee elk overeenkomstig X- en Y-gegeven voorkomt. De standaardwaarde is 1. Alle elementen moeten gehele getallen | 0 zijn. Hypoth is een optionele waarde die één van de drie alternatieve hypothesen specificeert, waartegen de nulhypothese (H0:b=r=0) wordt getoetst. Voor H1: bƒ0 en rƒ0 (standaard) stelt u Hypoth=0 in Voor H1: b<0 en r<0 stelt u Hypoth<0 in Voor H1: b>0 en r>0 stelt u Hypoth>0 in Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: a + b·x |
|
stat.t |
t-statistiek voor significantietoets |
|
stat.PVal |
Kleinste significantieniveau waarbij de nulhypothese verworpen kan worden |
|
stat.df |
Vrijheidsgraden |
|
stat.a, stat.b |
Regressiecoëfficiënten |
|
stat.s |
Standaardfout van de lijn |
|
stat.SESlope |
Standaardfout van helling |
|
stat.r2 |
Determinatiecoëfficiënt |
|
stat.r |
Correlatiecoëfficiënt |
|
stat.Resid |
Residuen uit de regressie |
|
Catalogus > |
|
|
Geeft een lijst met oplossingen voor de variabelen Var1, Var2, ... Het eerste argument moet uitgewerkt worden tot een stelsel lineaire vergelijkingen of tot één lineaire vergelijking. Anders treedt er een argumentfout op. Bijvoorbeeld: het uitwerken van |
|

|
Catalogus > |
|
|
@List(Lijst1)Þlijst Opmerking: u kunt deze operator vanaf het toetsenbord van de computer invoeren door deltaList(...) in te typen. Geeft een lijst met de verschillen tussen opeenvolgende elementen in Lijst1. Ieder element van Lijst1 wordt afgetrokken van het volgende element van Lijst1. De resulterende lijst is altijd één element korter dan de oorspronkelijke Lijst1. |
|
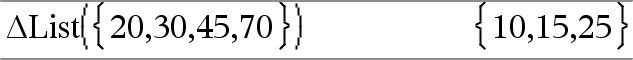
|
Catalogus > |
|
|
list4mat(Lijst [, elementenPerRij])Þmatrix Geeft een matrix die rij voor rij gevuld wordt met de elementen uit Lijst. elementenPerRij specificeert, indien opgenomen, het aantal elementen per rij. De standaardwaarde is het aantal element in Lijst (één rij). Als Lijst de resulterende matrix niet vult, dan worden er nullen toegevoegd. Opmerking: u kunt deze operator vanaf het toetsenbord van de computer invoeren door list@>mat(...) in te typen. |
|
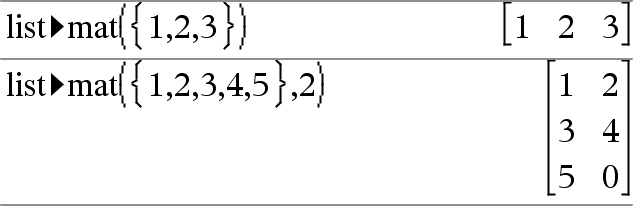
|
/u-toetsen |
|
|
ln(Waarde1)Þwaarde ln(Lijst1)Þlijst Geeft de natuurlijke logaritme van het argument. Geeft bij een lijst de natuurlijke logaritme van de elementen. |
Als de complexe opmaak-modus Reëel is:
Als de complexe opmaak-modus Rechthoekig is:
|
|
ln(vierkanteMatrix1)ÞvierkanteMatrix Geeft de natuurlijke logaritme van vierkanteMatrix1. Dit is niet hetzelfde als het berekenen van de natuurlijke logaritme van elk element. Zie voor informatie over de berekeningsmethode cos(). vierkanteMatrix1 moet diagonaliseerbaar zijn. Het resultaat bevat altijd getallen met een drijvende komma. |
In de hoekmodus Radialen en rechthoekige complexe opmaak:
Om het hele resultaat te zien drukt u op 5 en gebruikt u vervolgens 7 en 8 om de cursor te verplaatsen. |


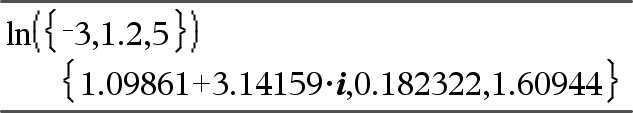

|
Catalogus > |
|
|
LnReg X, Y[, [Freq] [, Categorie, Opnemen]] Berekent de logaritmische regressie y = a+b·ln(x) op de lijsten X en Y met frequentie Freq. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Alle lijsten moeten gelijke afmetingen hebben, behalve Opnemen. X en Y zijn lijsten met onafhankelijke en afhankelijke variabelen. Freq is een optionele lijst met frequentiewaarden. Elk element in Freq specificeert de frequentie waarmee elk overeenkomstig X- en Y-gegeven voorkomt. De standaardwaarde is 1. Alle elementen moeten gehele getallen | 0 zijn. Categorie is een lijst met Opnemen is een lijst met één of meer van de categoriecodes. Alleen de gegevens waarvan de categoriecode is opgenomen in deze lijst worden opgenomen in de berekening. Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: a+b·ln(x) |
|
stat.a, stat.b |
Regressiecoëfficiënten |
|
stat.r2 |
Coëfficiënt van lineaire determinatie voor getransformeerde gegevens |
|
stat.r |
Correlatiecoëfficiënt voor getransformeerde gegevens (ln(x), y) |
|
stat.Resid |
Residuen die geassocieerd zijn met het logaritmische model |
|
stat.ResidTrans |
Residuen die geassocieerd zijn met de lineaire regressie van getransformeerde gegevens |
|
stat.XReg |
Lijst van de gegevens in de gemodificeerde XLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.YReg |
Lijst van gegevens in de gemodificeerde YLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.FreqReg |
Lijst van frequenties die corresponderen met stat.XReg en stat.YReg |
|
Catalogus > |
|
|
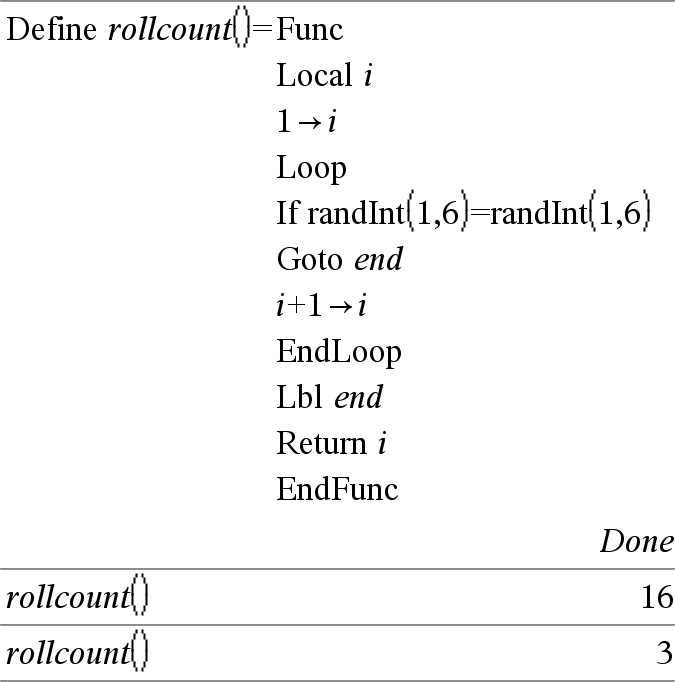
Local Var1[, Var2] [, Var3] ... Maakt de gespecificeerde vars bekend als lokale variabelen. Die variabelen bestaan alleen tijdens de uitwerking van een functie, en worden gewist wanneer de functie uitgevoerd is. Opmerking: lokale variabelen besparen geheugen omdat ze slechts tijdelijk bestaan. Bovendien storen ze eventuele bestaande algemene variabelen niet. Lokale variabelen moeten gebruikt worden voor For-lussen en voor het tijdelijk opslaan van waarden in een functie van meerdere regels, aangezien wijzigingen van algemene variabelen niet zijn toegestaan in een functie. Opmerking bij het invoeren van het voorbeeld: Instructies over het invoeren van programma's met meerdere regels en functiedefinities vindt u in het hoofdstuk Rekenmachine van de handleiding van uw product. |
|
|
Catalogus > |
|
|
Vergrendelt de gespecificeerde variabelen of variabelegroep. Vergrendelde variabelen kunnen niet worden gewijzigd of gewist. U kunt de systeemvariabele Ans niet vergrendelen of ontgrendelen, en u kunt de systeemvariabelegroepen stat. en en tvm. niet vergrendelen. Opmerking: Het commando Vergrendelen (Lock) wist de Ongedaan maken/Overdoen-geschiedenis als het wordt toegepast op niet-vergrendelde variabelen. |
|

|
/s-toetsen |
|
|
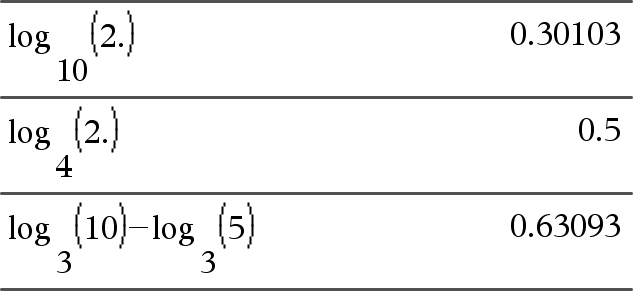
log(Lijst1[,Waarde2])Þlijst
Geeft de logaritme met grondtal-Waarde2- van het eerste argument. Opmerking: zie ook Log-template, hier. Geeft bij een lijst de logaritme met grondtal-Waarde2- van de elementen. Als het tweede argument wordt weggelaten, dan wordt 10 als grondtal gebruikt. |
Als de complexe opmaak-modus Reëel is:
Als de complexe opmaak-modus Rechthoekig is:
|
|
Geeft de logaritme met grondtal-Waarde- van vierkanteMatrix1. Dit is niet hetzelfde als het berekenen van de logaritme met grondtal-Waarde- van elk element. Zie voor informatie over de berekeningsmethode cos(). vierkanteMatrix1 moet diagonaliseerbaar zijn. Het resultaat bevat altijd getallen met een drijvende komma. Als het grondtal-argument wordt weggelaten, dan wordt 10 als grondtal gebruikt. |
In de hoekmodus Radialen en rechthoekige complexe opmaak:
Om het hele resultaat te zien drukt u op 5 en gebruikt u vervolgens 7 en 8 om de cursor te verplaatsen. |



|
Catalogus > |
|
|
Logistic X, Y[, [Freq] [, Categorie, Opnemen]] Berekent de logistische regressiey = (c/(1+a·e-bx))op de lijsten X en Y met frequentie Freq. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Alle lijsten moeten gelijke afmetingen hebben, behalve Opnemen. X en Y zijn lijsten met onafhankelijke en afhankelijke variabelen. Freq is een optionele lijst met frequentiewaarden. Elk element in Freq specificeert de frequentie waarmee elk overeenkomstig X- en Y-gegeven voorkomt. De standaardwaarde is 1. Alle elementen moeten gehele getallen | 0 zijn. Categorie is een lijst met Opnemen is een lijst met één of meer van de categoriecodes. Alleen de gegevens waarvan de categoriecode is opgenomen in deze lijst worden opgenomen in de berekening. Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: c/(1+a·e-bx) |
|
stat.a, stat.b, stat.c |
Regressiecoëfficiënten |
|
stat.Resid |
Residuen uit de regressie |
|
stat.XReg |
Lijst van de gegevens in de gemodificeerde XLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.YReg |
Lijst van gegevens in de gemodificeerde YLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.FreqReg |
Lijst van frequenties die corresponderen met stat.XReg en stat.YReg |
|
Catalogus > |
|
|
LogisticD X, Y [, [Iteraties], [Freq] [, Categorie, Opnemen] ] Berekent de logistische regressie y = (c/(1+a·e-bx)+d) op de lijsten X en Y met frequentie Freq, met behulp van een gespecificeerd aantal Iteraties. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Alle lijsten moeten gelijke afmetingen hebben, behalve Opnemen. X en Y zijn lijsten met onafhankelijke en afhankelijke variabelen. Iteraties is een optionele waarde die het maximaal aantal keer specificeert dat een oplossing wordt geprobeerd. Als deze wordt weggelaten, wordt 64 gebruikt. Doorgaans leiden grotere waarden tot een hogere nauwkeurigheid maar een langere berekeningstijd, en andersom. Freq is een optionele lijst met frequentiewaarden. Elk element in Freq specificeert de frequentie waarmee elk overeenkomstig X- en Y-gegeven voorkomt. De standaardwaarde is 1. Alle elementen moeten gehele getallen | 0 zijn. Categorie is een lijst met Opnemen is een lijst met één of meer van de categoriecodes. Alleen de gegevens waarvan de categoriecode is opgenomen in deze lijst worden opgenomen in de berekening. Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: c/(1+a·e-bx)+d) |
|
stat.a, stat.b, stat.c, stat.d |
Regressiecoëfficiënten |
|
stat.Resid |
Residuen uit de regressie |
|
stat.XReg |
Lijst van gegevens in de gemodificeerde XLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.YReg |
Lijst van gegevens in de gemodificeerde YLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.FreqReg |
Lijst van frequenties die corresponderen met stat.XReg en stat.YReg |
|
Catalogus > |
|
|
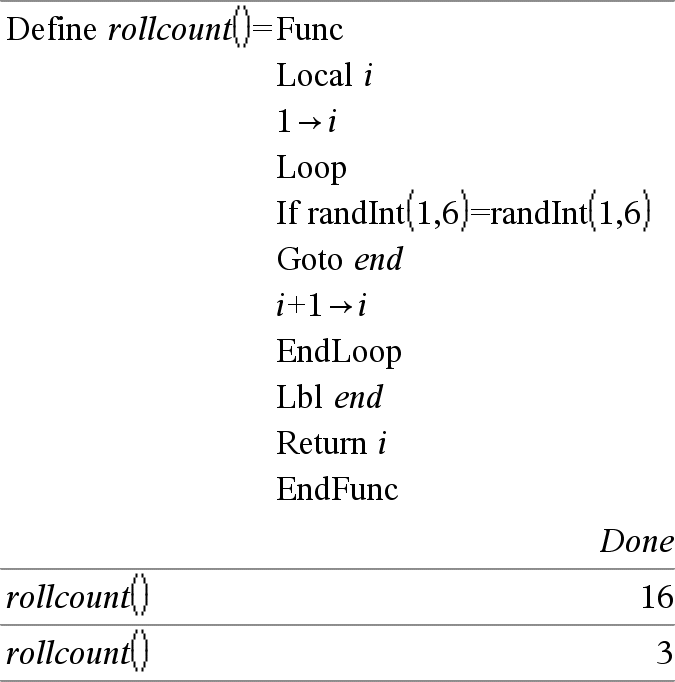
Loop Voert de beweringen in Blok herhaaldelijk uit. Merk op dat de lus eindeloos wordt uitgevoerd, tenzij er een Goto- of Exit-instructie wordt uitgevoerd binnen Blok. Blok is een reeks beweringen die gescheiden worden door het teken “:”. Opmerking bij het invoeren van het voorbeeld: Instructies over het invoeren van programma's met meerdere regels en functiedefinities vindt u in het hoofdstuk Rekenmachine van de handleiding van uw product. |
|
|
Catalogus > |
|||||||
|
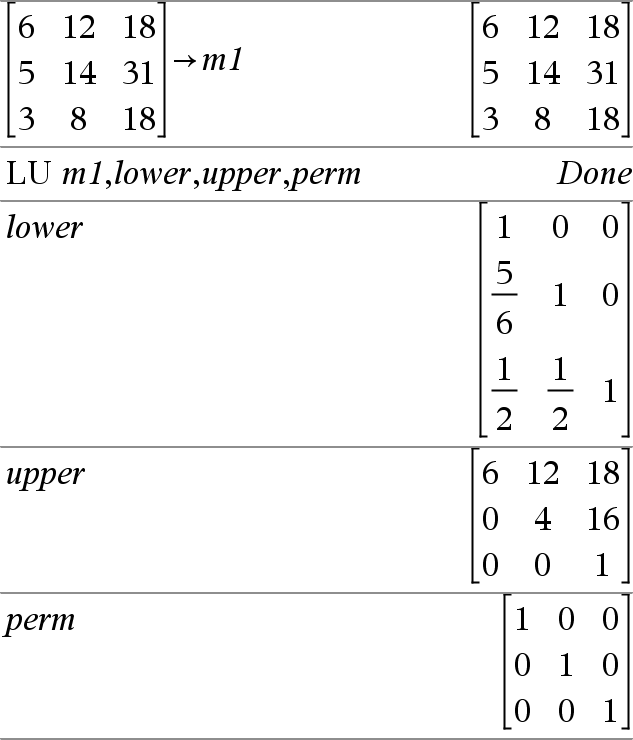
LU Matrix, lMatrix, uMatrix, pMatrix[,Tol] Berekent de Doolittle LU (beneden-boven)-decompositie van een reële of complexe matrix. De benedendriehoeksmatrix wordt opgeslagen in lMatrix, de bovendriehoeksmatrix in uMatrix en de permutatiematrix (die de rijverwisselingen tijdens de berekening beschrijft) in pMatrix. lMatrix · uMatrix = pMatrix · matrix Optioneel wordt elk matrixelement behandeld als nul als de absolute waarde ervan minder dan Tol is. Deze tolerantie wordt alleen gebruikt als de matrix gegevens met een drijvende komma heeft, en geen symbolische variabelen bevat die geen waarde toegekend hebben gekregen. Anders wordt Tol genegeerd.
Het LU ontbindingsalgoritme gebruikt gedeeltelijke pivoting met rijverwisselingen. |
|