|
Catalogo > |
|
|
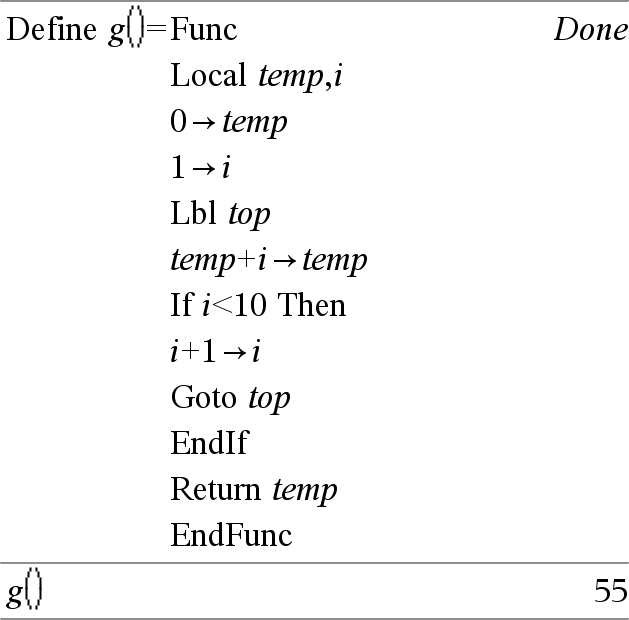
Lbl nomeEtichetta Definisce un’etichetta chiamata nomeEtichetta in una funzione. È possibile utilizzare un’istruzione Goto nomeEtichetta per trasferire il controllo del programma all’istruzione immediatamente successiva all’etichetta. nomeEtichetta deve soddisfare gli stessi requisiti validi per i nomi delle variabili. Nota per l'inserimento dell'esempio: per istruzioni sull'inserimento di definizioni di programmi e funzioni costituite da più righe, consultare la sezione Calcolatrice del manuale del prodotto. |
|

|
Catalogo > |
|
|
lcm(Numero1, Numero2)Þespressione lcm(List1, Lista2)Þlista lcm(Matrice1, Matrice2)Þmatrice Restituisce il minimo comune multiplo (lcm) di due argomenti. Il lcm di due frazioni è il minimo comune multiplo dei loro numeratori diviso per il massimo comune divisore (gcd) dei loro denominatori. Il lcm dei numeri frazionari a virgola mobile è il loro prodotto. Per due liste o matrici, restituisce i minimi comuni multipli dei corrispondenti elementi. |
|
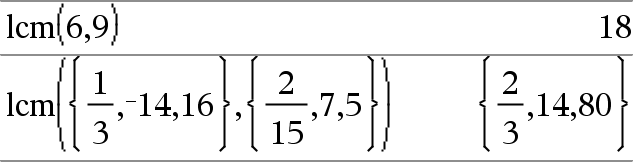
|
Catalogo > |
|
|
left(stringaOrigine[, Num])Þstringa Restituisce i caratteri Num più a sinistra contenuti nella stringa di caratteri stringaOrigine. Se si omette Num, restituisce l’intera stringaOrigine. |
|
|
left(Lista1[, Num])Þlista Restituisce gli elementi Num più a sinistra contenuti in Lista1. Se si omette Num, restituisce l’intera Lista1. |
|
|
left(Confronto)Þespressione Restituisce il primo membro di un’equazione o di una disequazione. |


|
Catalogo > |
|
|
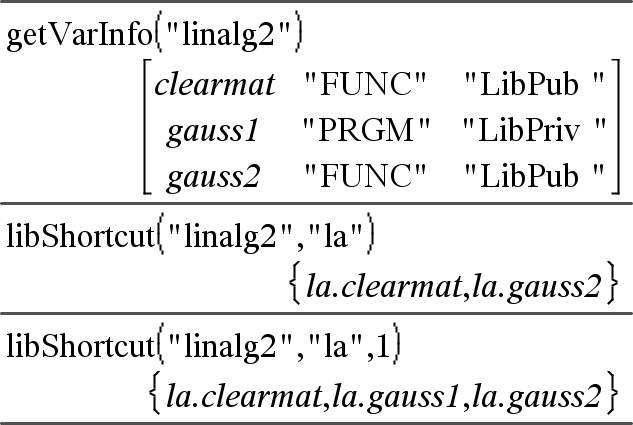
libShortcut(stringaNomeLibr, stringaNomeCollegamento[, LibPrivFlag])Þlista di variabili Crea una gruppo di variabili nell’attività corrente che contiene i riferimenti a tutti gli oggetti nel documento libreria specificato stringaNomeLibr. Aggiunge inoltre i membri del gruppo al menu Variables (Variabili). È quindi possibile fare riferimento a ciascun oggetto utilizzando la relativa stringaNomeCollegamento. Impostare LibPrivFlag=0 per escludere oggetti libreria privata (default) Impostare LibPrivFlag=1 per includere oggetti libreria privata Per copiare un gruppo di variabili, vedere CopyVar, qui. Per eliminare un gruppo di variabili, vedere DelVar, qui. |
Questo esempio presuppone un documento libreria memorizzato e aggiornato, denominato linalg2, che contiene oggetti definiti come clearmat, gauss1 e gauss2.
|
|
Catalogo > |
|
|
LinRegBx X,Y[,Freq[,Categoria,Includi]] Calcola la regressione linearey = a+b·xsulle liste X e Y con frequenza Freq. Il riepilogo dei risultati è memorizzato nella variabile stat.results. (qui). Tutte le liste devono avere le stesse dimensioni, ad eccezione di Includi. X e Y sono liste di variabili indipendenti e dipendenti. Freq è una lista opzionale di valori di frequenza. Ciascun elemento di Freq specifica la frequenza di occorrenza di ogni dato corrispondente di X e Y. Il valore predefinito è 1. Tutti gli elementi devono essere numeri interi | 0. Categoria è una lista Includi è una lista di uno o più codici di categoria. Solo quei dati il cui codice di categoria è inserito in questa lista vengono inclusi nel calcolo. Per informazioni sull'effetto di elementi vuoti in una lista, vedere “Elementi vuoti (nulli)”, qui. |
|
|
Variabile di output |
Descrizione |
|
stat.RegEqn |
Equazione di regressione: a+b·x |
|
stat.a, stat.b |
Coefficienti di regressione |
|
stat.r2 |
coefficiente di determinazione |
|
stat.r |
Coefficiente di correlazione |
|
stat.Resid |
Residui della regressione |
|
stat.XReg |
Lista di punti dati della Lista X modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.YReg |
Lista di punti dati della Lista Y modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.FreqReg |
Lista di frequenze corrispondenti a stat.XReg e stat.YReg |
|
Catalogo > |
|
|
LinRegMx X,Y[,Freq[,Categoria,Includi]] Calcola la regressione lineare y = m·x+b sulle liste X e Y con frequenza Freq. Il riepilogo dei risultati è memorizzato nella variabile stat.results. (qui). Tutte le liste devono avere le stesse dimensioni, ad eccezione di Includi. X e Y sono liste di variabili indipendenti e dipendenti. Freq è una lista opzionale di valori di frequenza. Ciascun elemento di Freq specifica la frequenza di occorrenza di ogni dato corrispondente di X e Y. Il valore predefinito è 1. Tutti gli elementi devono essere numeri interi | 0. Categoria è una lista Includi è una lista di uno o più codici di categoria. Solo quei dati il cui codice di categoria è inserito in questa lista vengono inclusi nel calcolo. Per informazioni sull'effetto di elementi vuoti in una lista, vedere “Elementi vuoti (nulli)”, qui. |
|
|
Variabile di output |
Descrizione |
|
stat.RegEqn |
Equazione di regressione: m·x+b |
|
stat.m, stat.b |
Coefficienti di regressione |
|
stat.r2 |
coefficiente di determinazione |
|
stat.r |
Coefficiente di correlazione |
|
stat.Resid |
Residui della regressione |
|
stat.XReg |
Lista di punti dati della Lista X modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.YReg |
Lista di punti dati della Lista Y modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.FreqReg |
Lista di frequenze corrispondenti a stat.XReg e stat.YReg |
|
Catalogo > |
|
|
LinRegtIntervals X,Y[,F[,0[,livelloConfidenza]]] Per pendenza Calcola un intervallo di confidenza di livello C per la pendenza. LinRegtIntervals X,Y[,F[,1,ValX[,livelloConfidenza]]] Per risposta. Calcola un valore y previsto, un intervallo di previsione del livello C per una singola osservazione e un intervallo di confidenza del livello C per la risposta media. Il riepilogo dei risultati è memorizzato nella variabile stat.results. (qui). Tutte le liste devono avere la stessa dimensione. X e Y sono liste di variabili indipendenti e dipendenti. F è una lista opzionale di valori di frequenza. Ciascun elemento di F specifica la frequenza di occorrenza di ogni dato corrispondente di X e Y. Il valore predefinito è 1. Tutti gli elementi devono essere numeri interi | 0. Per informazioni sull'effetto di elementi vuoti in una lista, vedere “Elementi vuoti (nulli)”, qui. |
|
|
Variabile di output |
Descrizione |
|
stat.RegEqn |
Equazione di regressione: a+b·x |
|
stat.a, stat.b |
Coefficienti di regressione |
|
stat.df |
Gradi di libertà |
|
stat.r2 |
Coefficiente di determinazione |
|
stat.r |
Coefficiente di correlazione |
|
stat.Resid |
Residui della regressione |
Solo tipo per pendenza
|
Variabile di output |
Descrizione |
|
[stat.CLower, stat.CUpper] |
Intervallo di confidenza per la pendenza |
|
stat.ME |
Margine di errore dell’intervallo di confidenza |
|
stat.SESlope |
Errore standard della pendenza |
|
stat.s |
Errore standard sulla linea |
Solo tipo per risposta
|
Variabile di output |
Descrizione |
|
[stat.CLower, stat.CUpper] |
Intervallo di confidenza per la risposta media |
|
stat.ME |
Margine di errore dell’intervallo di confidenza |
|
stat.SE |
Errore standard della risposta media |
|
[stat.LowerPred, stat.UpperPred] |
Intervallo di previsione per una singola osservazione |
|
stat.MEPred |
Margine di errore dell’intervallo di previsione |
|
stat.SEPred |
Errore standard per la previsione |
|
stat.y |
a + b·ValX |
|
Catalogo > |
|
|
LinRegtTest X,Y[,Freq[,Ipotesi]] Calcola una regressione lineare sulle liste X e Y e un t test sul valore della pendenza b e il coefficiente di correlazione r per l’equazione y=a+bx. Viene verificata l’ipotesi nulla H0:b=0 (in modo equivalente, r=0) in relazione a una di tre ipotesi alternative. Tutte le liste devono avere la stessa dimensione. X e Y sono liste di variabili indipendenti e dipendenti. Freq è una lista opzionale di valori di frequenza. Ciascun elemento di Freq specifica la frequenza di occorrenza di ogni dato corrispondente di X e Y. Il valore predefinito è 1. Tutti gli elementi devono essere numeri interi | 0. Ipotesi è un valore opzionale che specifica una di tre ipotesi alternative rispetto alla quale verrà testata l’ipotesi nulla (H0:b=r=0). Per Ha: bƒ0 e rƒ0 (default), impostare Ipotesi=0 Per Ha: b<0 e r<0, impostare Ipotesi<0 Per Ha: b>0 e r>0, impostare Ipotesi>0 Il riepilogo dei risultati è memorizzato nella variabile stat.results. (qui). Per informazioni sull'effetto di elementi vuoti in una lista, vedere “Elementi vuoti (nulli)”, qui. |
|
|
Variabile di output |
Descrizione |
|
stat.RegEqn |
Equazione di regressione: a + b·x |
|
stat.t |
Statistica T per il test di significatività |
|
stat.PVal |
Livello minimo di significatività in corrispondenza del quale l’ipotesi nulla può essere rifiutata |
|
stat.df |
Gradi di libertà |
|
stat.a, stat.b |
Coefficienti di regressione |
|
stat.s |
Errore standard sulla linea |
|
stat.SESlope |
Errore standard della pendenza |
|
stat.r2 |
Coefficiente di determinazione |
|
stat.r |
Coefficiente di correlazione |
|
stat.Resid |
Residui della regressione |
|
Catalogo > |
|
|
Restituisce una lista di soluzioni per le variabili Var1, Var2, ... Il primo argomento deve calcolare un sistema di equazioni lineari o una singola equazione lineare. Diversamente, si ottiene un argomento errato. Ad esempio, calcolando |
|

|
Catalogo > |
|
|
@list(Lista1)Þlista Nota: è possibile inserire questa funzione dalla tastiera del computer digitando deltaList(...). Restituisce una lista contenente le differenze tra elementi consecutivi in Lista1. Ogni elemento di Lista1 viene sottratto dal successivo elemento di Lista1. La lista risultante è sempre composta da un elemento in meno della Lista1 originale. |
|
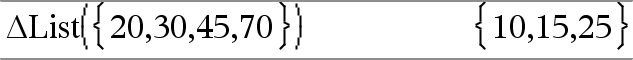
|
Catalogo > |
|
|
list4mat(Lista [, elementiPerRiga])Þmatrice Restituisce una matrice completata riga per riga con gli elementi di Lista. elementiPerRiga, se incluso, specifica il numero di elementi per riga. L’impostazione predefinita corrisponde al numero di elementi di Lista (una riga). Se Lista non completa la matrice risultante, viene aggiunta una serie di zeri. Nota: è possibile inserire questa funzione dalla tastiera del computer digitando list@>mat(...). |
|
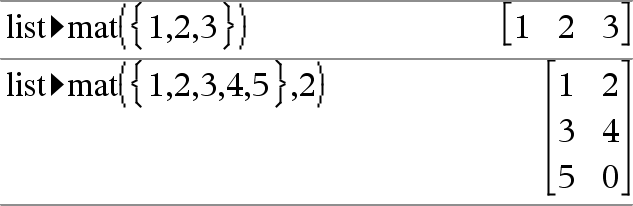
|
Tasti /u |
|
|
ln(Valore1)Þvalore ln(Lista1)Þlista Restituisce il logaritmo naturale dell’argomento. In una lista, restituisce i logaritmi naturali degli elementi. |
Se la modalità del formato complesso è Reale:
Se la modalità del formato complesso è Rettangolare:
|
|
ln(matriceQuadrata1)ÞmatriceQuadrata Restituisce il logaritmo naturale della matrice matriceQuadrata1. Ciò non equivale a calcolare il logaritmo naturale di ogni elemento. Per informazioni sul metodo di calcolo, vedere cos(). matriceQuadrata1 deve essere diagonalizzabile. Il risultato contiene sempre numeri a virgola mobile. |
In modalità angolo in radianti e in modalità formato rettangolare complesso:
Per vedere l'intero risultato, premere 5, quindi utilizzare 7 e 8 per spostare il cursore. |


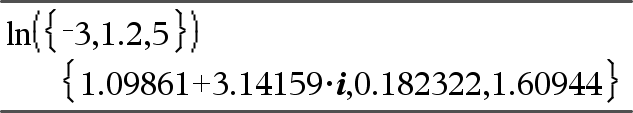

|
Catalogo > |
|
|
LnReg X, Y[, [Freq] [, Categoria, Includi]] Calcola la regressione logaritmica y = a+b·ln(x) sulle liste X e Y con frequenza Freq. Il riepilogo dei risultati è memorizzato nella variabile stat.results. (qui). Tutte le liste devono avere le stesse dimensioni, ad eccezione di Includi. X e Y sono liste di variabili indipendenti e dipendenti. Freq è una lista opzionale di valori di frequenza. Ciascun elemento di Freq specifica la frequenza di occorrenza di ogni dato corrispondente di X e Y. Il valore predefinito è 1. Tutti gli elementi devono essere numeri interi | 0. Categoria è una lista Includi è una lista di uno o più codici di categoria. Solo quei dati il cui codice di categoria è inserito in questa lista vengono inclusi nel calcolo. Per informazioni sull'effetto di elementi vuoti in una lista, vedere “Elementi vuoti (nulli)”, qui. |
|
|
Variabile di output |
Descrizione |
|
stat.RegEqn |
Equazione di regressione: a+b·ln(x) |
|
stat.a, stat.b |
Coefficienti di regressione |
|
stat.r2 |
Coefficiente di determinazione lineare di dati trasformati |
|
stat.r |
Coefficiente di correlazione per dati trasformati (ln(x), y) |
|
stat.Resid |
Residui associati al modello logaritmico |
|
stat.ResidTrans |
Residui associati all’adattamento lineare dei dati trasformati |
|
stat.XReg |
Lista di punti dati della Lista X modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.YReg |
Lista di punti dati della Lista Y modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.FreqReg |
Lista di frequenze corrispondenti a stat.XReg e stat.YReg |
|
Catalogo > |
|
|
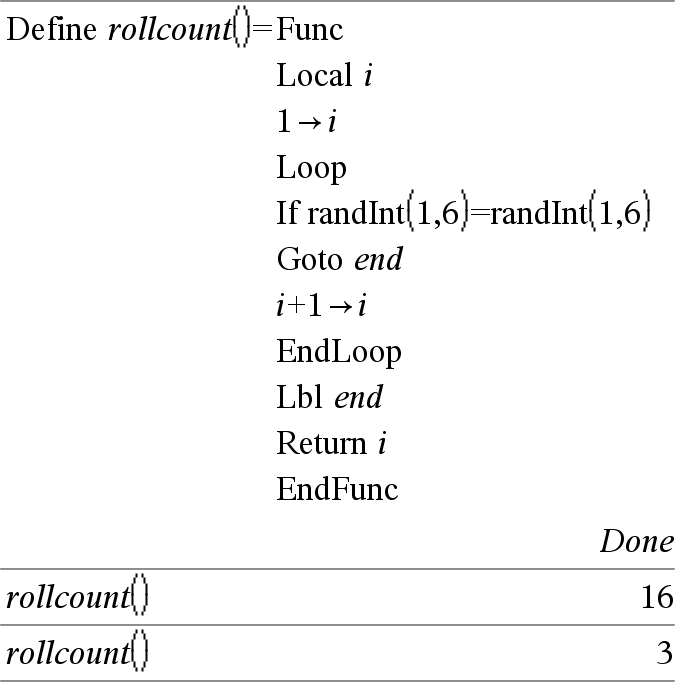
Local Var1[, Var2] [, Var3] ... Definisce le var specificate come variabili locali. Tali variabili esistono solamente durante il calcolo di una funzione e vengono cancellate al termine dell’esecuzione di tale funzione. Nota: le variabili locali permettono di risparmiare memoria in quanto esistono solo temporaneamente. Inoltre, esse non influiscono sui valori delle variabili globali esistenti. Le variabili locali devono essere utilizzate per i cicli For e per salvare in maniera provvisoria i valori in una funzione su diverse righe, poiché le modifiche sulle variabili globali non sono ammesse in una funzione. Nota per l'inserimento dell'esempio: per istruzioni sull'inserimento di definizioni di programmi e funzioni costituite da più righe, consultare la sezione Calcolatrice del manuale del prodotto. |
|
|
Catalogo > |
|
|
Blocca le variabili o il gruppo di variabili specificate. Le variabili bloccate non possono essere modificate o eliminate. Non è possibile bloccare o sbloccare la variabile di sistema Ans, inoltre non è possibile bloccare i gruppi di variabili di sistema stat. o tvm. Nota: Il comando Blocca (Lock) cancella la cronologia di Annulla/Ripeti quando è applicato a variabili sbloccate. |
|

|
Tasti /s |
|
|
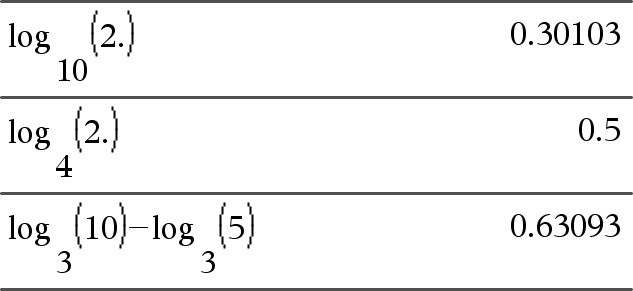
log(Lista1[,Valore2])Þlista
Restituisce il logaritmo in base-Valore2 dell’argomento. Nota: vedere anche Modello di logaritmo, qui. In una lista, restituisce il logaritmo in base-Valore2 degli elementi. Se Espr2 viene omesso, come base viene utilizzato 10. |
Se la modalità del formato complesso è Reale:
Se la modalità del formato complesso è Rettangolare:
|
|
Restituisce il logaritmo in base-Valore2 della matrice di matriceQuadrata1. Ciò non equivale a calcolare il logaritmo in base-Valore2 di ogni elemento. Per informazioni sul metodo di calcolo, vedere cos(). matriceQuadrata1 deve essere diagonalizzabile. Il risultato contiene sempre numeri a virgola mobile. Se l’argomento base viene omesso, come base viene utilizzato 10. |
In modalità angolo in radianti e in modalità formato rettangolare complesso:
Per vedere l'intero risultato, premere 5, quindi utilizzare 7 e 8 per spostare il cursore. |



|
Catalogo > |
|
|
Logistic X, Y[, [Freq] [, Categoria, Includi]] Calcola la regressione logisticay = (c/(1+a·e-bx))sulle liste X e Y con frequenza Freq. Il riepilogo dei risultati è memorizzato nella variabile stat.results. (qui). Tutte le liste devono avere le stesse dimensioni, ad eccezione di Includi. X e Y sono liste di variabili indipendenti e dipendenti. Freq è una lista opzionale di valori di frequenza. Ciascun elemento di Freq specifica la frequenza di occorrenza di ogni dato corrispondente di X e Y. Il valore predefinito è 1. Tutti gli elementi devono essere numeri interi | 0. Categoria è una lista Includi è una lista di uno o più codici di categoria. Solo quei dati il cui codice di categoria è inserito in questa lista vengono inclusi nel calcolo. Per informazioni sull'effetto di elementi vuoti in una lista, vedere “Elementi vuoti (nulli)”, qui. |
|
|
Variabile di output |
Descrizione |
|
stat.RegEqn |
Equazione di regressione: c/(1+a·e-bx) |
|
stat.a, stat.b, stat.c |
Coefficienti di regressione |
|
stat.Resid |
Residui della regressione |
|
stat.XReg |
Lista di punti dati della Lista X modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.YReg |
Lista di punti dati della Lista Y modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.FreqReg |
Lista di frequenze corrispondenti a stat.XReg e stat.YReg |
|
Catalogo > |
|
|
LogisticD X, Y [, [Iterazioni], [Freq] [, Categoria, Includi]] Calcola la regressione logistica y = (c/(1+a·e-bx)+d) sulle liste X e Y con frequenza Freq, utilizzando un numero specificato di Iterazioni. Il riepilogo dei risultati è memorizzato nella variabile stat.results. (qui). Tutte le liste devono avere le stesse dimensioni, ad eccezione di Includi. X e Y sono liste di variabili indipendenti e dipendenti. Iterazioni è un valore opzionale che specifica quante volte al massimo verrà tentata una soluzione. Se omesso, viene utilizzato 64. Di solito valori più alti danno una maggiore accuratezza ma richiedono tempi di esecuzione più lunghi, e viceversa. Freq è una lista opzionale di valori di frequenza. Ciascun elemento di Freq specifica la frequenza di occorrenza di ogni dato corrispondente di X e Y. Il valore predefinito è 1. Tutti gli elementi devono essere numeri interi | 0. Categoria è una lista Includi è una lista di uno o più codici di categoria. Solo quei dati il cui codice di categoria è inserito in questa lista vengono inclusi nel calcolo. Per informazioni sull'effetto di elementi vuoti in una lista, vedere “Elementi vuoti (nulli)”, qui. |
|
|
Variabile di output |
Descrizione |
|
stat.RegEqn |
Equazione di regressione: c/(1+a·e-bx)+d) |
|
stat.a, stat.b, stat.c, stat.d |
Coefficienti di regressione |
|
stat.Resid |
Residui della regressione |
|
stat.XReg |
Lista di punti dati della Lista X modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.YReg |
Lista di punti dati della Lista Y modificata attualmente usata nella regressione secondo le restrizioni di Freq, Lista Categoria e Includi Categorie |
|
stat.FreqReg |
Lista di frequenze corrispondenti a stat.XReg e stat.YReg |
|
Catalogo > |
|
|
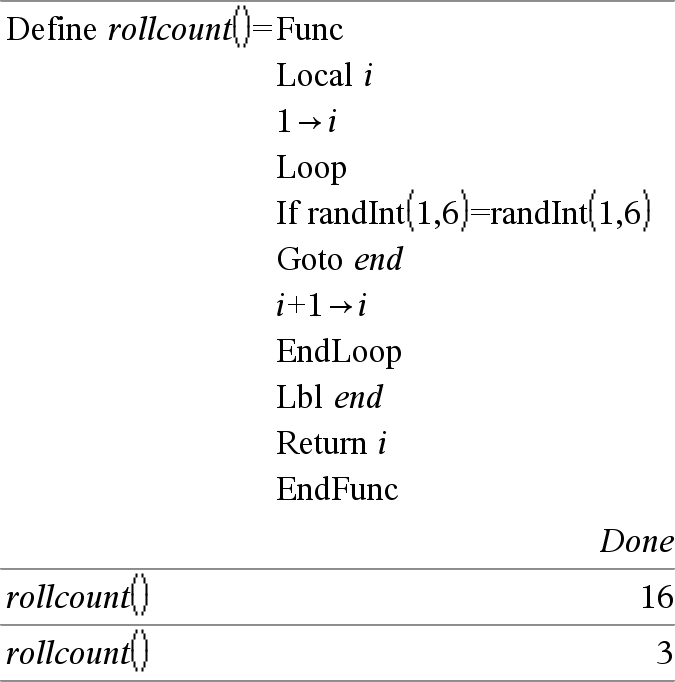
Loop Esegue ciclicamente le istruzioni di Blocco. Si noti che un ciclo viene eseguito infinite volte, se non si trovano istruzioni Goto o Exit all’interno di Blocco. Blocco è una sequenza di istruzioni separate dal carattere. Nota per l'inserimento dell'esempio: per istruzioni sull'inserimento di definizioni di programmi e funzioni costituite da più righe, consultare la sezione Calcolatrice del manuale del prodotto. |
|
|
Catalogo > |
|||||||
|
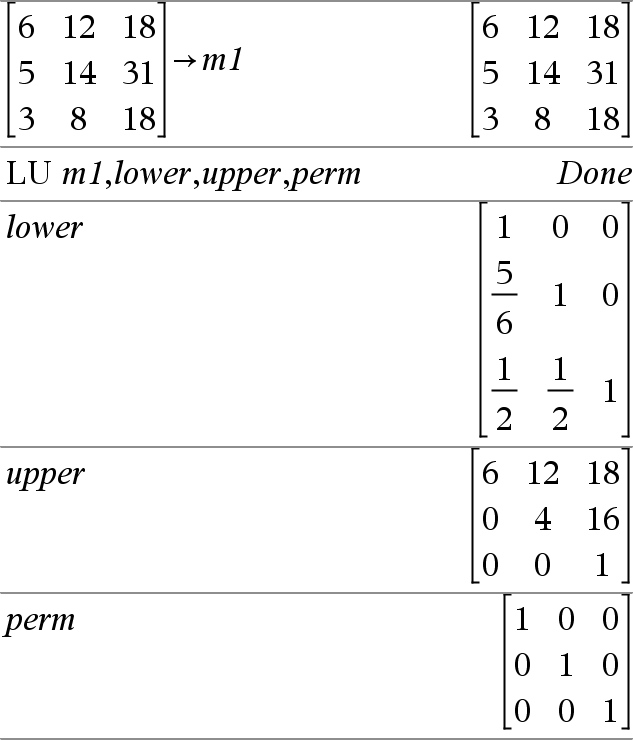
LU Matrice, MatriceL, MatriceU, MatriceP[,Tol] Calcola la scomposizione LU (lower-upper, inferiore-superiore) di una matrice reale o complessa. La matrice triangolare inferiore è memorizzata in MatriceL, quella superiore in MatriceU e la matrice di permutazione (che descrive gli scambi di riga eseguiti durante i calcoli) in MatriceP. MatriceL · MatriceU = MatriceP · matrice In alternativa, un elemento qualsiasi della matrice viene considerato zero se il suo valore assoluto è minore di Toll. Tale tolleranza viene utilizzata solo se la matrice contiene elementi a virgola mobile e non contiene variabili simboliche alle quali non sia stato assegnato un valore. In caso contrario, Toll viene ignorato.
L’algoritmo di scomposizione in fattori LU usa il pivoting parziale per lo scambio di righe. |
|