|
Catalogue > |
|
|
Lbl nomÉtiquette Définit une étiquette en lui attribuant le nom nomÉtiquette dans une fonction. Vous pouvez utiliser l'instruction Goto nomÉtiquette pour transférer le contrôle du programme à l'instruction suivant immédiatement l'étiquette. nomÉtiquette doit être conforme aux mêmes règles de dénomination que celles applicables aux noms de variables. Remarque pour la saisie des données de l’exemple : Pour obtenir des instructions sur la saisie des définitions de fonction ou de programme sur plusieurs lignes, consultez la section relative à la calculatrice dans votre guide de produit. |
|


|
Catalogue > |
|
|
lcm(Nombre1, Nombre2)Þexpression lcm(Liste1, Liste2)Þliste lcm(Matrice1, Matrice2)Þmatrice Donne le plus petit commun multiple des deux arguments. Le lcm de deux fractions correspond au lcm de leur numérateur divisé par le gcd de leur dénominateur. Le lcm de nombres fractionnaires en virgule flottante correspond à leur produit. Pour deux listes ou matrices, donne les plus petits communs multiples des éléments correspondants. |
|
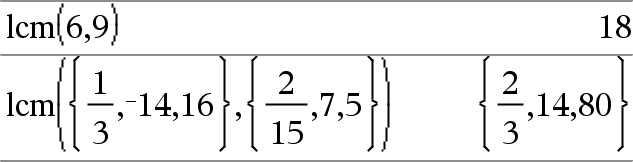
|
Catalogue > |
|
|
left(chaîneSrce[, Nomb])Þchaîne Donne la chaîne formée par les Nomb premiers caractères de la chaîne chaîneSrce. Si Nomb est absent, on obtient chaîneSrce. |
|
|
left(Liste1[, Nomb])Þliste Donne la liste formée par les Nomb premiers éléments de Liste1. Si Nomb est absent, on obtient Liste1. |
|
|
left(Comparaison)Þexpression Donne le membre de gauche d'une équation ou d'une inéquation. |
|



|
Catalogue > |
|
|
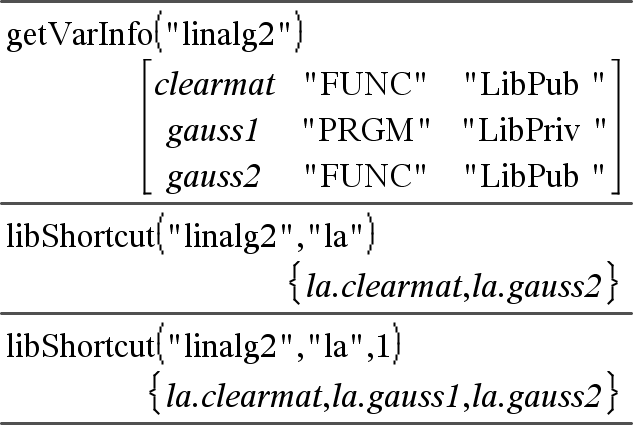
libShortcut(chaîneNomBibliothèque, chaîneNomRaccourci[, LibPrivFlag])Þliste de variables Crée un groupe de variables dans l'activité courante qui contient des références à tous les objets du classeur de bibliothèque spécifié chaîneNomBibliothèque. Ajoute également les membres du groupe au menu Variables. Vous pouvez ensuite faire référence à chaque objet en utilisant la chaîneNomRaccourci correspondante. Définissez LibPrivFlag=0 pour exclure des objets de la bibliothèque privée (par défaut) et LibPrivFlag=1 pour inclure des objets de bibliothèque privée. Pour copier un groupe de variables, reportez-vous à CopyVar, ici. Pour supprimer un groupe de variables, reportez-vous à DelVar, ici. |
Cet exemple utilise un classeur de bibliothèque enregistré et rafraîchi linalg2 qui contient les objets définis comme clearmat, gauss1 et gauss2.
|
|
Catalogue > |
|
|
limit(Expr1, Var, Point [,Direction])Þexpression limit(Liste1, Var, Point [, Direction])Þliste limit(Matrice1, Var, Point [, Direction])Þmatrice Donne la limite recherchée. Remarque : voir aussi Modèle Limite, ici. Direction : négative=limite à gauche, positive=limite à droite, sinon=gauche et droite. (Si Direction est absent, la valeur par défaut est gauche et droite.) |
|
|
Les limites en +ˆ et en -ˆ sont toujours converties en limites unilatérales. |
|
|
Dans certains cas, limit() retourne lui-même ou undef (non défini) si aucune limite ne peut être déterminée. Cela ne signifie pas pour autant qu'aucune limite n'existe. undef signifie que le résultat est soit un nombre inconnu fini ou infini soit l'ensemble complet de ces nombres. |
|
|
limit() utilisant des méthodes comme la règle de L’Hôpital, il existe des limites uniques que cette fonction ne permet pas de déterminer. Si Expr1 contient des variables non définies autres que Var, il peut s'avérer nécessaire de les contraindre pour obtenir un résultat plus précis. Les limites peuvent être affectées par les erreurs d'arrondi. Dans la mesure du possible, n'utilisez pas le réglage Approché (Approximate) du mode Auto ou Approché (Approximate) ni des nombres approchés lors du calcul de limites. Sinon, les limites normalement nulles ou infinies risquent de ne pas l'être. |
|
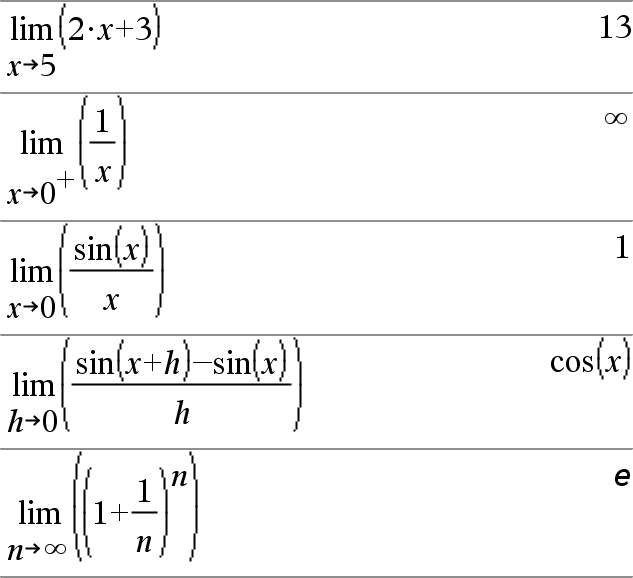
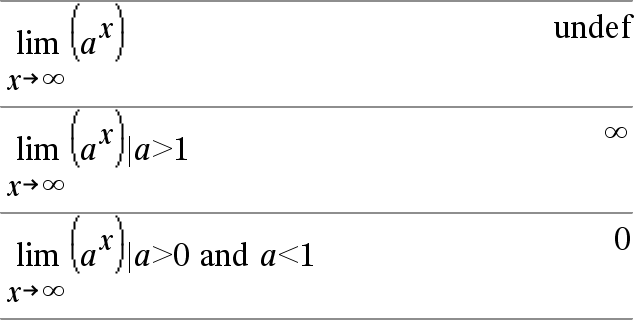
|
Catalogue > |
|
|
LinRegBx X,Y[,[Fréq][,Catégorie,Inclure]] Effectue l'ajustement linéairey = a+b·xsur les listes X et Y en utilisant la fréquence Fréq. Un récapitulatif du résultat est stocké dans la variable stat.results. (Voir ici.) Toutes les listes doivent comporter le même nombre de lignes, à l'exception de Inclure. X et Y sont des listes de variables indépendantes et dépendantes. Fréq est une liste facultative de valeurs qui indiquent la fréquence. Chaque élément dans Fréq correspond à une fréquence d'occurrence pour chaque couple X et Y. Par défaut, cette valeur est égale à 1. Tous les éléments doivent être des entiers | 0. Catégorie est une liste de codes de catégories pour les couples X et Y correspondants. Inclure est une liste d'un ou plusieurs codes de catégories. Seuls les éléments dont le code de catégorie figure dans cette liste sont inclus dans le calcul. Pour plus d'informations concernant les éléments vides dans une liste, reportez-vous à “Éléments vides”, ici. |
|
|
Variable de sortie |
Description |
|
stat.RegEqn |
Équation d'ajustement : a+b·x |
|
stat.a, stat.b |
Coefficients d'ajustement |
|
stat.r2 |
Coefficient de détermination |
|
stat.r |
Coefficient de corrélation |
|
stat.Resid |
Valeurs résiduelles de l'ajustement |
|
stat.XReg |
Liste des points de données de la liste Liste X modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.YReg |
Liste des points de données de la liste Liste Y modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.FreqReg |
Liste des fréquences correspondant à stat.XReg et stat.YReg |
|
Catalogue > |
|
|
LinRegMx X,Y[,[Fréq][,Catégorie,Inclure]] Effectue l'ajustement linéaire y = m·x+b sur les listes X et Y en utilisant la fréquence Fréq. Un récapitulatif du résultat est stocké dans la variable stat.results. (Voir ici.) Toutes les listes doivent comporter le même nombre de lignes, à l'exception de Inclure. X et Y sont des listes de variables indépendantes et dépendantes. Fréq est une liste facultative de valeurs qui indiquent la fréquence. Chaque élément dans Fréq correspond à une fréquence d'occurrence pour chaque couple X et Y. Par défaut, cette valeur est égale à 1. Tous les éléments doivent être des entiers | 0. Catégorie est une liste de codes de catégories pour les couples X et Y correspondants. Inclure est une liste d'un ou plusieurs codes de catégories. Seuls les éléments dont le code de catégorie figure dans cette liste sont inclus dans le calcul. Pour plus d'informations concernant les éléments vides dans une liste, reportez-vous à “Éléments vides”, ici. |
|
|
Variable de sortie |
Description |
|
stat.RegEqn |
Équation d'ajustement : m·x+b |
|
stat.m, stat.b |
Coefficients d'ajustement |
|
stat.r2 |
Coefficient de détermination |
|
stat.r |
Coefficient de corrélation |
|
stat.Resid |
Valeurs résiduelles de l'ajustement |
|
stat.XReg |
Liste des points de données de la liste Liste X modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.YReg |
Liste des points de données de la liste Liste Y modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.FreqReg |
Liste des fréquences correspondant à stat.XReg et stat.YReg |
|
Catalogue > |
|
|
LinRegtIntervals X,Y[,F[,0[,NivC]]] Pente. Calcule un intervalle de confiance de niveau C pour la pente. LinRegtIntervals X,Y[,F[,1,Xval[,NivC]]] Réponse. Calcule une valeur y prévue, un intervalle de prévision de niveau C pour une seule observation et un intervalle de confiance de niveau C pour la réponse moyenne. Un récapitulatif du résultat est stocké dans la variable stat.results. (Voir ici.) Toutes les listes doivent comporter le même nombre de lignes. X et Y sont des listes de variables indépendantes et dépendantes. F est une liste facultative de valeurs qui indiquent la fréquence. Chaque élément dans F spécifie la fréquence d'occurrence pour chaque couple X et Y. Par défaut, cette valeur est égale à 1. Tous les éléments doivent être des entiers | 0. Pour plus d'informations concernant les éléments vides dans une liste, reportez-vous à “Éléments vides”, ici. |
|
|
Variable de sortie |
Description |
|
stat.RegEqn |
Équation d'ajustement : a+b·x |
|
stat.a, stat.b |
Coefficients d'ajustement |
|
stat.df |
Degrés de liberté |
|
stat.r2 |
Coefficient de détermination |
|
stat.r |
Coefficient de corrélation |
|
stat.Resid |
Valeurs résiduelles de l'ajustement |
Pour les intervalles de type Slope uniquement
|
Variable de sortie |
Description |
|
[stat.CLower, stat.CUpper] |
Intervalle de confiance de pente |
|
stat.ME |
Marge d'erreur de l'intervalle de confiance |
|
stat.SESlope |
Erreur type de pente |
|
stat.s |
Erreur type de ligne |
Pour les intervalles de type Response uniquement
|
Variable de sortie |
Description |
|
[stat.CLower, stat.CUpper] |
Intervalle de confiance pour une réponse moyenne |
|
stat.ME |
Marge d'erreur de l'intervalle de confiance |
|
stat.SE |
Erreur type de réponse moyenne |
|
[stat.LowerPred, stat.UpperPred] |
Intervalle de prévision pour une observation simple |
|
stat.MEPred |
Marge d'erreur de l'intervalle de prévision |
|
stat.SEPred |
Erreur type de prévision |
|
stat.y |
a + b·ValX |
|
Catalogue > |
|
|
LinRegtTest X,Y[,Fréq[,Hypoth]] Effectue l'ajustement linéaire sur les listes X et Y et un t-test sur la valeur de la pente b et le coefficient de corrélation r pour l'équation y=a+bx. Il teste l'hypothèse nulle H0 :b=0 (équivalent, r=0) par rapport à l'une des trois hypothèses. Toutes les listes doivent comporter le même nombre de lignes. X et Y sont des listes de variables indépendantes et dépendantes. Fréq est une liste facultative de valeurs qui indiquent la fréquence. Chaque élément dans Fréq correspond à une fréquence d'occurrence pour chaque couple X et Y. Par défaut, cette valeur est égale à 1. Tous les éléments doivent être des entiers | 0. Hypoth est une valeur facultative qui spécifie une des trois hypothèses par rapport à laquelle l'hypothèse nulle (H0 :b=r=0) est testée. Pour Ha : bƒ0 et rƒ0 (par défaut), définissez Hypoth=0 Pour Ha : b<0 et r<0, définissez Hypoth<0 Pour Ha : b>0 et r>0, définissez Hypoth>0 Un récapitulatif du résultat est stocké dans la variable stat.results. (Voir ici.) Pour plus d'informations concernant les éléments vides dans une liste, reportez-vous à “Éléments vides”, ici. |
|
|
Variable de sortie |
Description |
|
stat.RegEqn |
Équation d'ajustement : a + b·x |
|
stat.t |
t-Statistique pour le test de signification |
|
stat.PVal |
Plus petit seuil de signification permettant de rejeter l'hypothèse nulle |
|
stat.df |
Degrés de liberté |
|
stat.a, stat.b |
Coefficients d'ajustement |
|
stat.s |
Erreur type de ligne |
|
stat.SESlope |
Erreur type de pente |
|
stat.r2 |
Coefficient de détermination |
|
stat.r |
Coefficient de corrélation |
|
stat.Resid |
Valeurs résiduelles de l'ajustement |
|
Catalogue > |
|
|
Affiche une liste de solutions pour les variables Var1, Var2, etc. Le premier argument doit être évalué à un système d'équations linéaires ou à une seule équation linéaire. Si tel n'est pas le cas, une erreur d'argument se produit. Par exemple, le calcul de |
|

|
Catalogue > |
|
|
@list(Liste1)Þliste Remarque : vous pouvez insérer cette fonction à partir du clavier en entrant deltaList(...). Donne la liste des différences entre les éléments consécutifs de Liste1. Chaque élément de Liste1 est soustrait de l'élément suivant de Liste1. Le résultat comporte toujours un élément de moins que la liste Liste1 initiale. |
|
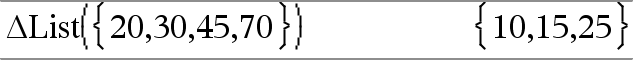
|
Catalogue > |
|
|
list4mat(Liste [, élémentsParLigne])Þmatrice Donne une matrice construite ligne par ligne à partir des éléments de Liste. Si élémentsParLigne est spécifié, donne le nombre d'éléments par ligne. La valeur par défaut correspond au nombre d'éléments de Liste (une ligne). Si Liste ne comporte pas assez d'éléments pour la matrice, on complète par zéros. Remarque : vous pouvez insérer cette fonction à partir du clavier de l'ordinateur en entrant list@>mat(...). |
|

|
Catalogue > |
|
|
Expr 4lnÞexpression Convertit Expr en une expression contenant uniquement des logarithmes népériens (ln). Remarque : vous pouvez insérer cet opérateur à partir du clavier de l'ordinateur en entrant @>ln. |
|

|
Touches /u |
|
|
ln(Expr1)Þexpression ln(Liste1)Þliste Donne le logarithme népérien de l'argument. Dans le cas d'une liste, donne les logarithmes népériens de tous les éléments de celle-ci. |
En mode Format complexe Réel :
En mode Format complexe Rectangulaire :
|
|
ln(matriceCarrée1)ÞmatriceCarrée Donne le logarithme népérien de la matrice matriceCarrée1. Ce calcul est différent du calcul du logarithme népérien de chaque élément. Pour plus d'informations sur la méthode de calcul, reportezvous à cos(). matriceCarrée1 doit être diagonalisable. Le résultat contient toujours des chiffres en virgule flottante. |
En mode Angle en radians et en mode Format complexe Rectangulaire :
Pour afficher le résultat entier, appuyez sur 5, puis utilisez les touches 7 et 8 pour déplacer le curseur. |


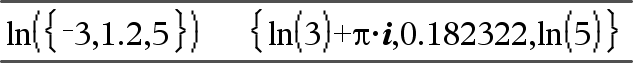

|
Catalogue > |
|
|
LnReg X, Y[, [Fréq] [, Catégorie, Inclure]] Effectue l'ajustement logarithmique y = a+b·ln(x) sur les listes X et Y en utilisant la fréquence Fréq. Un récapitulatif du résultat est stocké dans la variable stat.results. (Voir ici.) Toutes les listes doivent comporter le même nombre de lignes, à l'exception de Inclure. X et Y sont des listes de variables indépendantes et dépendantes. Fréq est une liste facultative de valeurs qui indiquent la fréquence. Chaque élément dans Fréq correspond à une fréquence d'occurrence pour chaque couple X et Y. Par défaut, cette valeur est égale à 1. Tous les éléments doivent être des entiers | 0. Catégorie est une liste de codes de catégories pour les couples X et Y correspondants. Inclure est une liste d'un ou plusieurs codes de catégories. Seuls les éléments dont le code de catégorie figure dans cette liste sont inclus dans le calcul. Pour plus d'informations concernant les éléments vides dans une liste, reportez-vous à “Éléments vides”, ici. |
|
|
Variable de sortie |
Description |
|
stat.RegEqn |
Équation d'ajustement : a+b·ln(x) |
|
stat.a, stat.b |
Coefficients d'ajustement |
|
stat.r2 |
Coefficient de détermination linéaire pour les données transformées |
|
stat.r |
Coefficient de corrélation pour les données transformées (ln(x), y) |
|
stat.Resid |
Valeurs résiduelles associées au modèle logarithmique |
|
stat.ResidTrans |
Valeurs résiduelles associées à l'ajustement linéaire des données transformées |
|
stat.XReg |
Liste des points de données de la liste Liste X modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.YReg |
Liste des points de données de la liste Liste Y modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.FreqReg |
Liste des fréquences correspondant à stat.XReg et stat.YReg |
|
Catalogue > |
|
|
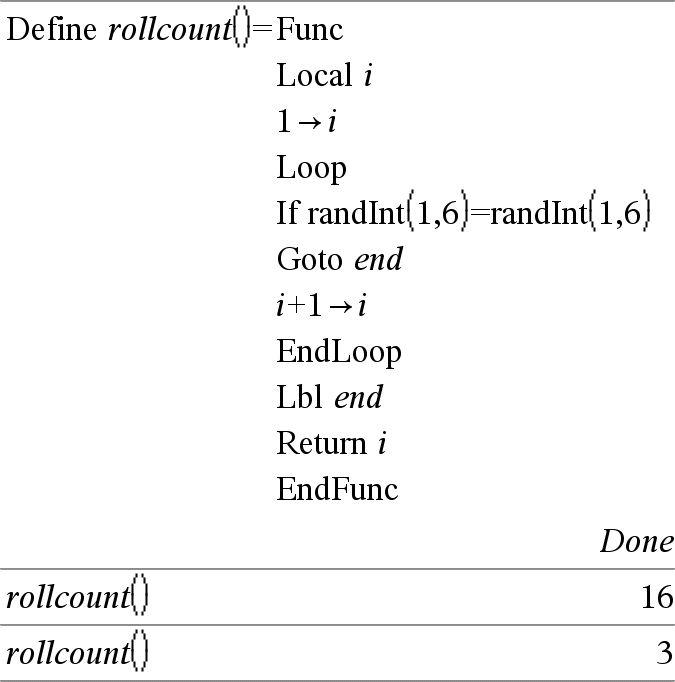
Local Var1[, Var2] [, Var3] ... Déclare les variables vars spécifiées comme variables locales. Ces variables existent seulement lors du calcul d'une fonction et sont supprimées une fois l'exécution de la fonction terminée. Remarque : les variables locales contribuent à libérer de la mémoire dans la mesure où leur existence est temporaire. De même, elle n'interfère en rien avec les valeurs des variables globales existantes. Les variables locales s'utilisent dans les boucles For et pour enregistrer temporairement des valeurs dans les fonctions de plusieurs lignes dans la mesure où les modifications sur les variables globales ne sont pas autorisées dans une fonction. Remarque pour la saisie des données de l’exemple : Pour obtenir des instructions sur la saisie des définitions de fonction ou de programme sur plusieurs lignes, consultez la section relative à la calculatrice dans votre guide de produit. |
|
|
Catalogue > |
|
|
Verrouille les variables ou les groupes de variables spécifiés. Les variables verrouillées ne peuvent être ni modifiées ni supprimées. Vous ne pouvez pas verrouiller ou déverrouiller la variable système Ans, de même que vous ne pouvez pas verrouiller les groupes de variables système stat. ou tvm. Remarque : La commande Verrouiller (Lock) efface le contenu de l'historique Annuler/Rétablir lorsqu'elle est appliquée à des variables non verrouillées. |
|

|
Touches /s |
|
|
log(Liste1[,Expr2])Þliste
Donne le logarithme de base Expr2 de l'argument. Remarque : voir aussi Modèle Logarithme, ici. Dans le cas d'une liste, donne le logarithme de base Expr2 des éléments. Si Expr2 est omis, la valeur de base 10 par défaut est utilisée. |
En mode Format complexe Réel :
En mode Format complexe Rectangulaire :
|
|
Donne le logarithme de base Expr de matriceCarrée1. Ce calcul est différent du calcul du logarithme de base Expr de chaque élément. Pour plus d'informations sur la méthode de calcul, reportez-vous à cos(). matriceCarrée1 doit être diagonalisable. Le résultat contient toujours des chiffres en virgule flottante. Si l'argument de base est omis, la valeur de base 10 par défaut est utilisée. |
En mode Angle en radians et en mode Format complexe Rectangulaire :
Pour afficher le résultat entier, appuyez sur 5, puis utilisez les touches 7 et 8 pour déplacer le curseur. |




|
Catalogue > |
|
|
Expr1 4logbase(Expr2)Þexpression Provoque la simplification de l'expression entrée en une expression utilisant uniquement des logarithmes de base Expr2. Remarque : vous pouvez insérer cet opérateur à partir du clavier de l'ordinateur en entrant @>logbase(...). |
|

|
Catalogue > |
|
|
Logistic X, Y[, [Fréq] [, Catégorie, Inclure]] Effectue l'ajustement logistiquey = (c/(1+a·e-bx))sur les listes X et Y en utilisant la fréquence Fréq. Un récapitulatif du résultat est stocké dans la variable stat.results. (Voir ici.) Toutes les listes doivent comporter le même nombre de lignes, à l'exception de Inclure. X et Y sont des listes de variables indépendantes et dépendantes. Fréq est une liste facultative de valeurs qui indiquent la fréquence. Chaque élément dans Fréq correspond à une fréquence d'occurrence pour chaque couple X et Y. Par défaut, cette valeur est égale à 1. Tous les éléments doivent être des entiers | 0. Catégorie est une liste de codes de catégories pour les couples X et Y correspondants. Inclure est une liste d'un ou plusieurs codes de catégories. Seuls les éléments dont le code de catégorie figure dans cette liste sont inclus dans le calcul. Pour plus d'informations concernant les éléments vides dans une liste, reportez-vous à “Éléments vides”, ici. |
|
|
Variable de sortie |
Description |
|
stat.RegEqn |
Équation d'ajustement : c/(1+a·e-bx) |
|
stat.a, stat.b, stat.c |
Coefficients d'ajustement |
|
stat.Resid |
Valeurs résiduelles de l'ajustement |
|
stat.XReg |
Liste des points de données de la liste Liste X modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.YReg |
Liste des points de données de la liste Liste Y modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.FreqReg |
Liste des fréquences correspondant à stat.XReg et stat.YReg |
|
Catalogue > |
|
|
LogisticD X, Y [, [Itérations], [Fréq] [, Catégorie, Inclure] ] Effectue l'ajustement logistique y = (c/(1+a·e-bx)+d) sur les listes X et Y en utilisant la fréquence Fréq et un nombre spécifique d'Itérations. Un récapitulatif du résultat est stocké dans la variable stat.results. (Voir ici.) Toutes les listes doivent comporter le même nombre de lignes, à l'exception de Inclure. X et Y sont des listes de variables indépendantes et dépendantes. L'argument facultatif Itérations spécifie le nombre maximum d'itérations utilisées lors de ce calcul. Si Itérations est omis, la valeur par défaut 64 est utilisée. On obtient généralement une meilleure précision en choisissant une valeur élevée, mais cela augmente également le temps de calcul, et vice versa. Fréq est une liste facultative de valeurs qui indiquent la fréquence. Chaque élément dans Fréq correspond à une fréquence d'occurrence pour chaque couple X et Y. Par défaut, cette valeur est égale à 1. Tous les éléments doivent être des entiers | 0. Catégorie est une liste de codes de catégories pour les couples X et Y correspondants. Inclure est une liste d'un ou plusieurs codes de catégories. Seuls les éléments dont le code de catégorie figure dans cette liste sont inclus dans le calcul. Pour plus d'informations concernant les éléments vides dans une liste, reportez-vous à “Éléments vides”, ici. |
|
|
Variable de sortie |
Description |
|
stat.RegEqn |
Équation d'ajustement : c/(1+a·e-bx)+d) |
|
stat.a, stat.b, stat.c, stat.d |
Coefficients d'ajustement |
|
stat.Resid |
Valeurs résiduelles de l'ajustement |
|
stat.XReg |
Liste des points de données de la liste Liste X modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.YReg |
Liste des points de données de la liste Liste Y modifiée, actuellement utilisée dans l'ajustement basé sur les restrictions de Fréq, Liste de catégories et Inclure les catégories |
|
stat.FreqReg |
Liste des fréquences correspondant à stat.XReg et stat.YReg |
|
Catalogue > |
|
|
Loop Exécute de façon itérative les instructions de Bloc. Notez que la boucle se répète indéfiniment, jusqu'à l'exécution d'une instruction Goto ou Exit à l'intérieur du Bloc. Bloc correspond à une série d'instructions, séparées par un « : ». Remarque pour la saisie des données de l’exemple : Pour obtenir des instructions sur la saisie des définitions de fonction ou de programme sur plusieurs lignes, consultez la section relative à la calculatrice dans votre guide de produit. |
|
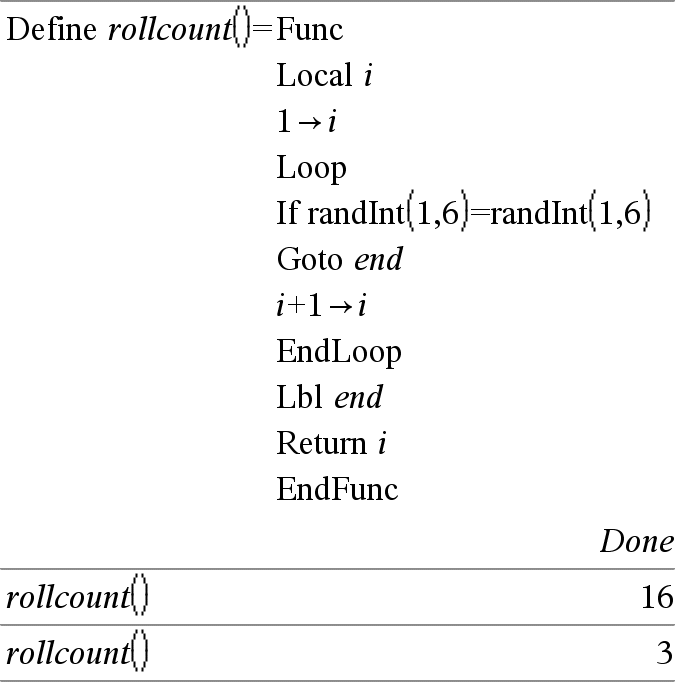
|
Catalogue > |
|||||||
|
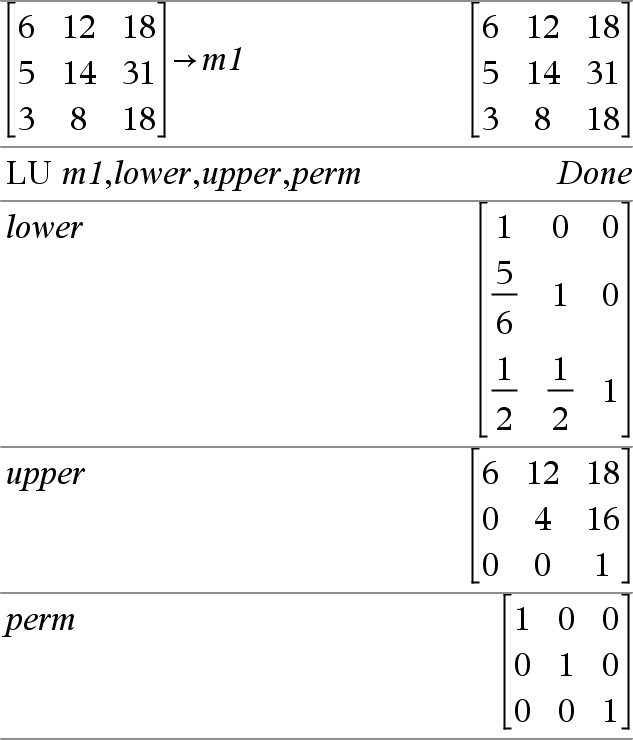
LU Matrice, lMatrice, uMatrice, pMatrice[,Tol] Calcule la décomposition LU (lower-upper) de Doolittle d'une matrice réelle ou complexe. La matrice triangulaire inférieure est stockée dans IMatrice, la matrice triangulaire supérieure dans uMatrice et la matrice de permutation (qui décrit les échange de lignes exécutés pendant le calcul) dans pMatrice. lMatrice · uMatrice = pMatrice · matrice L'argument facultatif Tol permet de considérer comme nul tout élément de la matrice dont la valeur absolue est inférieure à Tol. Cet argument n'est utilisé que si la matrice contient des nombres en virgule flottante et ne contient pas de variables symbolique sans valeur affectée. Dans le cas contraire, Tol est ignoré.
L'algorithme de factorisation LU utilise la méthode du Pivot partiel avec échanges de lignes. |
|