|
Katalog > |
|
|
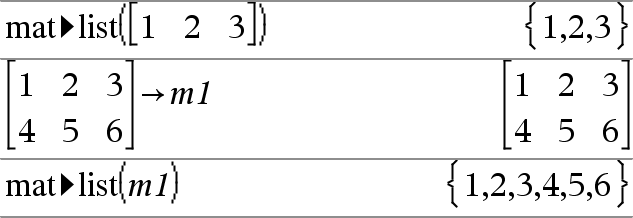
mat4list(Matrix)ÞListe Gibt eine Liste zurück, die mit den Elementen aus Matrix gefüllt wurde. Die Elemente werden Zeile für Zeile aus Matrix kopiert. Hinweis: Sie können diese Funktion über die Tastatur Ihres Computers eingeben, indem Sie mat@>list(...) eintippen. |
|

|
Katalog > |
|
|
max(Wert1, Wert2)ÞAusdruck max(Liste1, Liste2)ÞListe max(Matrix1, Matrix2)ÞMatrix Gibt das Maximum der beiden Argumente zurück. Wenn die Argumente zwei Listen oder Matrizen sind, wird eine Liste bzw. Matrix zurückgegeben, die den Maximalwert für jedes entsprechende Elementpaar enthält. |
|
|
max(Liste)ÞAusdruck Gibt das größte Element von Liste zurück. |
|
|
max(Matrix1)ÞMatrix Gibt einen Zeilenvektor zurück, der das größte Element jeder Spalte von Matrix1 enthält. Leere (ungültige) Elemente werden ignoriert. Weitere Informationen zu leeren Elementen finden Sie (hier). Hinweis: Siehe auch min(). |
|

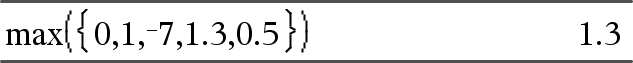

|
Katalog > |
|
|
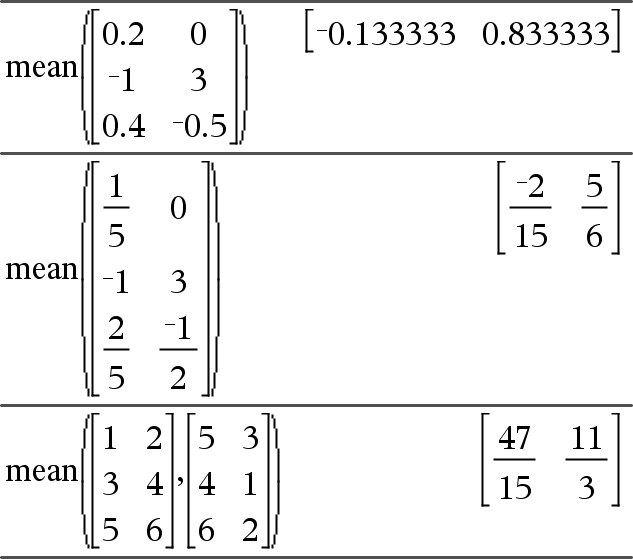
mean(Liste[, Häufigkeitsliste])ÞAusdruck Gibt den Mittelwert der Elemente in Liste zurück. Jedes Häufigkeitsliste-Element gewichtet die Elemente von Liste in der gegebenen Reihenfolge entsprechend. |
|
|
mean(Matrix1[, Häufigkeitsmatrix]) ÞMatrix Ergibt einen Zeilenvektor aus den Mittelwerten aller Spalten in Matrix1. Jedes Häufigkeitsmatrix-Element gewichtet die Elemente von Matrix1 in der gegebenen Reihenfolge entsprechend. Leere (ungültige) Elemente werden ignoriert. Weitere Informationen zu leeren Elementen finden Sie (hier). |
Im Vektorformat kartesisch:
|

|
Katalog > |
|||||||
|
median(Liste[, freqList])ÞAusdruck Gibt den Medianwert der Elemente in Liste zurück. Jedes freqList-Element gewichtet die Elemente von Liste in der gegebenen Reihenfolge entsprechend. |
|
||||||
|
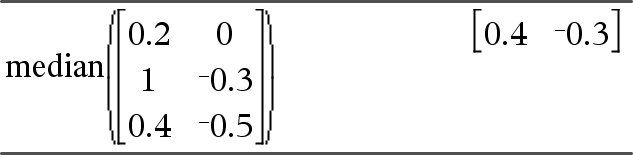
median(Matrix1[, freqMatrix])ÞMatrix Gibt einen Zeilenvektor zurück, der die Medianwerte der einzelnen Spalten von Matrix1enthält. Jedes freqMatrix-Element gewichtet die Elemente von Matrix1 in der gegebenen Reihenfolge entsprechend. Hinweise:
|
|
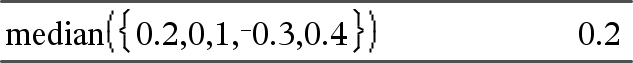
|
Katalog > |
|
|
MedMed X,Y [, Häuf] [, Kategorie, Mit]] Berechnet die Median-Median-Liniey = (m·x+b)auf Listen X und Y mit der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Alle Listen außer Mit müssen die gleiche Dimension besitzen. X und Y sind Listen von unabhängigen und abhängigen Variablen. Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein. Kategorie ist eine Liste von Kategoriecodes Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur solche Datenelemente, deren Kategoriecode in dieser Liste enthalten ist, sind in der Berechnung enthalten. Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Median-Median-Linien-Gleichung: m·x+b |
|
stat.m, stat.b |
Modellkoeffizienten |
|
stat.Resid |
Residuen von der Median-Median-Linie |
|
stat.XReg |
Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.YReg |
Liste der Datenpunkte in der modifizierten Y-Liste, die schließlich in der Regression mit den Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde |
|
stat.FreqReg |
Liste der Häufigkeiten für stat.XReg und stat.YReg |
|
Katalog > |
|
|
mid(Quellstring, Start[, Anzahl])ÞString Gibt Anzahl Zeichen aus der Zeichenkette Quellstring ab dem Zeichen mit der Nummer Start zurück. Wird Anzahl weggelassen oder ist sie größer als die Länge von Quellstring, werden alle Zeichen vonQuellstring ab dem Zeichen mit der Nummer Start zurückgegeben. Anzahl muss | 0 sein. Bei Anzahl = 0 wird eine leere Zeichenkette zurückgegeben. |
|
|
mid(Quellliste, Start [, Anzahl])ÞListe Gibt Anzahl Elemente aus Quellliste ab dem Element mit der Nummer Start zurück. Wird Anzahl weggelassen oder ist sie größer als die Dimension von Quellliste, werden alle Elemente von Quellliste ab dem Element mit der Nummer Start zurückgegeben. Anzahl muss | 0 sein. Bei Anzahl = 0 wird eine leere Liste zurückgegeben. |
|
|
mid(QuellstringListe, Start[, Anzahl])ÞListe Gibt Anzahl Strings aus der Stringliste QuellstringListe ab dem Element mit der Nummer Start zurück. |
|


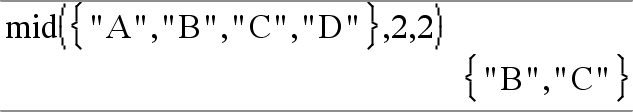
|
Katalog > |
|
|
min(Wert1, Wert2)ÞAusdruck min(Liste1, Liste2)ÞListe min(Matrix1, Matrix2)ÞMatrix Gibt das Minimum der beiden Argumente zurück. Wenn die Argumente zwei Listen oder Matrizen sind, wird eine Liste bzw. Matrix zurückgegeben, die den Minimalwert für jedes entsprechende Elementpaar enthält. |
|
|
min(Liste)ÞAusdruck Gibt das kleinste Element von Liste zurück. |
|
|
min(Matrix1)ÞMatrix Gibt einen Zeilenvektor zurück, der das kleinste Element jeder Spalte von Matrix1 enthält. Hinweis: Siehe auch max(). |
|

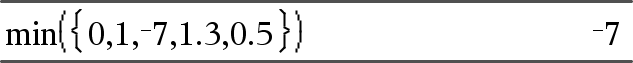

|
Katalog > |
|
|
mirr(Finanzierungsrate,Reinvestitionsrate,CF0,CFListe[,CFFreq]) Finanzfunktion, die den modifizierten internen Zinsfluss einer Investition zurückgibt. Finanzierungsrate ist der Zinssatz, den Sie für die Cash-Flow-Beträge zahlen. Reinvestitionsrate ist der Zinssatz, zu dem die Cash-Flows reinvestiert werden. CF0 ist der Anfangs-Cash-Flow zum Zeitpunkt 0; dies muss eine reelle Zahl sein. CFListe ist eine Liste von Cash-Flow-Beträgen nach dem Anfangs-Cash-Flow CF0. CFFreq ist eine optionale Liste, in der jedes Element die Häufigkeit des Auftretens für einen gruppierten (fortlaufenden) Cash-Flow-Betrag angibt, der das entsprechende Element von CFListe ist. Der Standardwert ist 1; wenn Sie Werte eingeben, müssen diese positive Ganzzahlen < 10.000 sein. Hinweis: Siehe auch irr(), hier. |
|

|
Katalog > |
|
|
mod(Wert1, Wert2)ÞAusdruck mod(Liste1, Liste2)ÞListe mod(Matrix1, Matrix2)ÞMatrix Gibt das erste Argument modulo das zweite Argument gemäß der folgenden Identitäten zurück: mod(x,0) = x mod(x,y) = x - y floor(x/y) Ist das zweite Argument ungleich Null, ist das Ergebnis in diesem Argument periodisch. Das Ergebnis ist entweder Null oder besitzt das gleiche Vorzeichen wie das zweite Argument. Sind die Argumente zwei Listen bzw. zwei Matrizen, wird eine Liste bzw. Matrix zurückgegeben, die den Modulus jedes Elementpaars enthält. Hinweis: Siehe auch remain(), hier |
|

|
Katalog > |
|
|
mRow(Zahl, Matrix1, Index)ÞMatrix
|
|
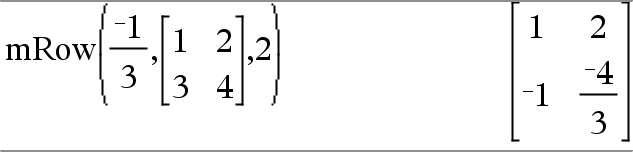
|
Katalog > |
|
|
mRowAdd(Zahl, Matrix1, Index1, Index2) ÞMatrix Gibt eine Kopie von Matrix1 zurück, wobei jedes Element in Zeile Index2 von Matrix1 ersetzt wird durch:
|
|
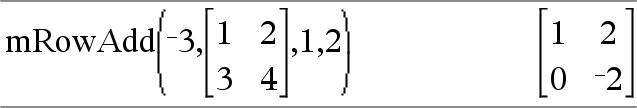
|
Katalog > |
|
|
MultReg Y, X1[,X2[,X3,…[,X10]]] Berechnet die lineare Mehrfachregression der Liste Y für die Listen X1, X2, …, X10. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Alle Listen müssen die gleiche Dimension besitzen. Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: b0+b1·x1+b2·x2+ ... |
|
stat.b0, stat.b1, ... |
Regressionskoeffizienten |
|
stat.R2 |
Multiples Bestimmtheitsmaß |
|
stat.yList |
yList = b0+b1·x1+ ... |
|
stat.Resid |
Residuen von der Regression |
|
Katalog > |
|
|
MultRegIntervals Y, X1[,X2[,X3,…[,X10]]],XWertListe[,KNiveau] Berechnet einen vorhergesagten y-Wert, ein Niveau-K-Vorhersageintervall für eine einzelne Beobachtung und ein Niveau-K-Konfidenzintervall für die mittlere Antwort. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Alle Listen müssen die gleiche Dimension besitzen. Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: b0+b1·x1+b2·x2+ ... |
|
stat.y |
Eine Punktschätzung: y = b0 + b1 · xl + ... für XWertListe |
|
stat.dfError |
Fehler-Freiheitsgrade |
|
stat.CLower, stat.CUpper |
Konfidenzintervall für eine mittlere Antwort |
|
stat.ME |
Konfidenzintervall-Fehlertoleranz |
|
stat.SE |
Standardfehler der mittleren Antwort |
|
stat.LowerPred, stat.UpperrPred |
Vorhersageintervall für eine einzelne Beobachtung |
|
stat.MEPred |
Vorhersageintervall-Fehlertoleranz |
|
stat.SEPred |
Standardfehler für Vorhersage |
|
stat.bList |
Liste der Regressionskoeffizienten, {b0,b1,b2,...} |
|
stat.Resid |
Residuen von der Regression |
|
Katalog > |
|
|
MultRegTests Y, X1[,X2[,X3,…[,X10]]] Der lineare Mehrfachregressionstest berechnet eine lineare Mehrfachregression für die gegebenen Daten sowie die globale F-Teststatistik und t-Teststatistik für die Koeffizienten. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
Ausgaben
|
Ausgabevariable |
Beschreibung |
|
stat.RegEqn |
Regressionsgleichung: b0+b1·x1+b2·x2+ ... |
|
stat.F |
Globale F-Testgröße |
|
stat.PVal |
Mit globaler F-Statistik verknüpfter P-Wert |
|
stat.R2 |
Multiples Bestimmtheitsmaß |
|
stat.AdjR2 |
Angepasster Koeffizient des multiplen Bestimmtheitsmaßes |
|
stat.s |
Standardabweichung des Fehlers |
|
stat.DW |
Durbin-Watson-Statistik; bestimmt, ob in dem Modell eine Autokorrelation erster Ordnung vorhanden ist |
|
stat.dfReg |
Regressions-Freiheitsgrade |
|
stat.SSReg |
Summe der Regressionsquadrate |
|
stat.MSReg |
Mittlere Regressionsstreuung |
|
stat.dfError |
Fehler-Freiheitsgrade |
|
stat.SSError |
Summe der Fehlerquadrate |
|
stat.MSError |
Mittleres Fehlerquadrat |
|
stat.bList |
{b0,b1,...} Liste der Koeffizienten |
|
stat.tList |
Liste der t-Testgrößen, eine für jeden Koeffizienten in b-Liste |
|
stat.PList |
Liste der P-Werte für jede t-Testgröße |
|
stat.SEList |
Liste der Standardfehler für Koeffizienten in b-Liste |
|
stat.yList |
yList = b0+b1·x1+ . . . |
|
stat.Resid |
Residuen von der Regression |
|
stat.sResid |
Standardisierte Residuen; wird durch Division eines Residuums durch die Standardabweichung ermittelt |
|
stat.CookDist |
Cookscher Abstand; Maß für den Einfluss einer Beobachtung auf der Basis von Residuum und Hebelwert |
|
stat.Leverage |
Maß für den Abstand der Werte der unabhängigen Variable von den Mittelwerten (Hebelwerte) |