|
Catalogus > |
|
|
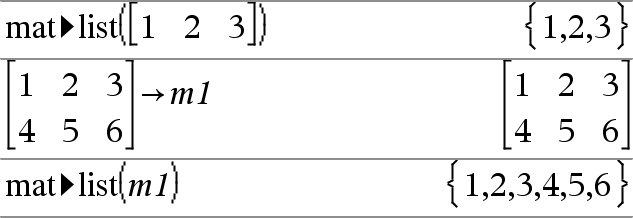
mat4list(Matrix)Þlijst Geeft een lijst die gevuld is met de elementen in Matrix. De elementen worden rij voor rij gekopieerd uit Matrix. Opmerking: u kunt deze operator vanaf het toetsenbord van de computer invoeren door mat@>list(...) in te typen. |
|

|
Catalogus > |
|
|
max(Waarde1, Waarde2)Þuitdrukking max(Lijst1, Lijst2)Þlijst max(Matrix1, Matrix2)Þmatrix Geeft het maximum van de twee argumenten. Als de argumenten twee lijsten of matrices zijn, dan wordt een lijst of matrix met de maximumwaarde van elk paar corresponderende gegevens gegeven. |
|
|
max(Lijst)Þuitdrukking Geeft het maximumelement in lijst. |
|
|
max(Matrix1)Þmatrix Geeft een rijvector met het maximumelement van elke kolom in Matrix1. Lege elementen worden genegeerd. Voor meer informatie over lege elementen, zie hier. Opmerking: zie ook min(). |
|

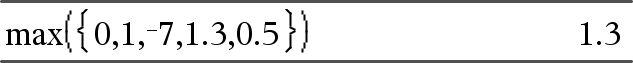

|
Catalogus > |
|
|
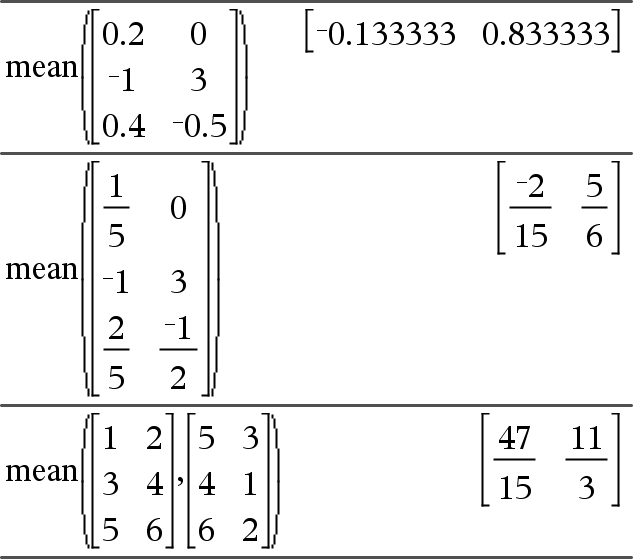
mean(Lijst[, freqLijst])Þuitdrukking Geeft het gemiddelde van de elementen in Lijst. Elk element uit freqLijst telt het aantal malen dat het overeenkomstige element in Lijst achter elkaar voorkomt. |
|
|
mean(Matrix1[, freqMatrix])Þmatrix Geeft een rijvector van de gemiddelden van alle kolommen in Matrix1. Elk element uit freqMatrix telt het aantal malen dat het overeenkomstige element in Matrix1 achter elkaar voorkomt. Lege elementen worden genegeerd. Voor meer informatie over lege elementen, zie hier. |
In de rechthoekige vectoropmaak:
|

|
Catalogus > |
|||||||
|
median(Lijst[, freqLijst])Þuitdrukking Geeft de mediaan van de elementen in Lijst. Elk element uit freqLijst telt het aantal malen dat het overeenkomstige element in Lijst voorkomt. |
|
||||||
|
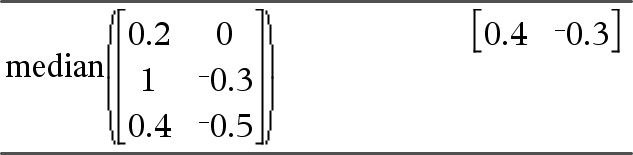
median(Matrix1[, freqMatrix])Þmatrix Geeft een rijvector met de medianen van de kolommen in Matrix1. Elk element uit freqMatrix telt het aantal malen dat het overeenkomstige element in Matrix1 achter elkaar voorkomt. Opmerkingen:
|
|
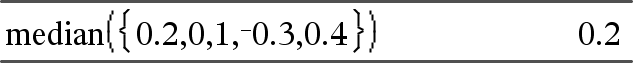
|
Catalogus > |
|
|
MedMed X,Y [, Freq] [, Categorie, Opnemen]] Berekent de mediaan-mediaan-lijny = (m·x+b)op de lijsten X en Y met frequentie Freq. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Alle lijsten moeten gelijke afmetingen hebben, behalve Opnemen. X en Y zijn lijsten met onafhankelijke en afhankelijke variabelen. Freq is een optionele lijst met frequentiewaarden. Elk element in Freq specificeert de frequentie waarmee elk overeenkomstig X- en Y-gegeven voorkomt. De standaardwaarde is 1. Alle elementen moeten gehele getallen | 0 zijn. Categorie is een lijst met Opnemen is een lijst met één of meer van de categoriecodes. Alleen de gegevens waarvan de categoriecode is opgenomen in deze lijst worden opgenomen in de berekening. Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Mediaan-mediaan-lijnvergelijking: m·x+b |
|
stat.m, stat.b |
Modelcoëfficiënten |
|
stat.Resid |
Residuen uit de mediaan-mediaan-lijn |
|
stat.XReg |
Lijst van de gegevens in de gemodificeerde XLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.YReg |
Lijst van gegevens in de gemodificeerde YLijst die feitelijk gebruikt worden in de regressie op basis van beperkingen van Freq, Categorielijst en Categorieën opnemen |
|
stat.FreqReg |
Lijst van frequenties die corresponderen met stat.XReg en stat.YReg |
|
Catalogus > |
|
|
mid(bronString, Start[, Aantal])Þstring Geeft Aantal tekens uit de tekenreeks bronString, beginnend met teken nummer Start. Als Aantal wordt weggelaten of groter is dan de afmeting van bronString, dan worden alle tekens van bronString gegeven, beginnend met het teken nummer Start. Aantal moet | 0 zijn. Als Aantal = 0, dan wordt een lege string gegeven. |
|
|
mid(bronLijst, Start [, Aantal])Þlijst Geeft Aantal elementen uit bronLijst, beginnend met element nummer Start. Als Aantal wordt weggelaten of groter is dan de afmeting van bronLijst, dan worden alle elementen uit bronLijst gegeven, beginnend met element nummer Start. Aantal moet | 0 zijn. Als Aantal = 0, dan wordt er een lege lijst gegeven. |
|
|
mid(bronStringLijst, Start[, Aantal])Þlijst Geeft Aantal strings uit de lijst met strings bronStringLijst, beginnend met element nummer Start. |
|


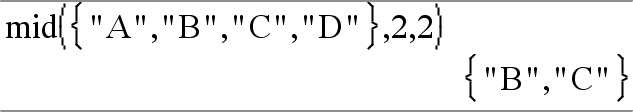
|
Catalogus > |
|
|
min(Waarde1, Waarde2)Þuitdrukking min(Lijst1, Lijst2)Þlijst min(Matrix1, Matrix2)Þmatrix Geeft het minimum van de twee argumenten. Als de argumenten twee lijsten of matrices zijn, dan wordt een lijst of matrix met de minimumwaarde van elk paar corresponderende gegevens gegeven. |
|
|
min(Lijst)Þuitdrukking Geeft het minimumelement van Lijst. |
|
|
min(Matrix1)Þmatrix Geeft een rijvector met het minimumelement van elke kolom in Matrix1. Opmerking: zie ook max(). |
|

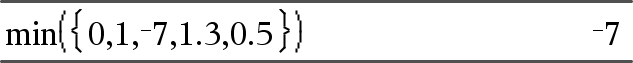

|
Catalogus > |
|
|
mirr(financPercentage,herinvestPercentage,CF0,CFLijst[,CFFreq]) Financiële functie die de gewijzigde interne rentabiliteit van een investering geeft. financPercentage is het rentepercentage dat u betaalt over de cashflow-bedragen. herinvestPercentage is het rentepercentage waarop de cashflows opnieuw geïnvesteerd worden. CF0 is de begin-cashflow op tijdstip 0; dit moet een reëel getal zijn. CFLijst is een lijst met cashflow-bedragen na de begin-cashflow CF0. CFFreq is een optionele lijst waarin elk element de frequentie waarmee een gegroepeerde (opeenvolgend) cashflow-bedrag voorkomt specificeert; dit is het overeenkomstige element van CFLijst. De standaardwaarde is 1; als u waarden invoert, dan moeten dit positieve gehele getallen < 10.000 zijn. Opmerking: zie ook irr(), hier. |
|

|
Catalogus > |
|
|
mod(Waarde1, Waarde2)Þuitdrukking mod(Lijst1, Lijst2)Þlijst mod(Matrix1, Matrix2)Þmatrix Geeft het eerste argument modulus het tweede argument zoals gedefinieerd wordt door de identiteiten: mod(x,0) = x mod(x,y) = x - y floor(x/y) Wanneer het tweede argument niet-nul is, dan is het resultaat periodiek in dat argument. Het resultaat is nul of heeft hetzelfde teken als het tweede argument. Als de argumenten twee lijsten of twee matrices zijn, dan wordt een lijst of matrix met de modulus van elk paar corresponderende elementen gegeven. Opmerking: zie ook remain(), hier |
|

|
Catalogus > |
|
|
mRow(Waarde, Matrix1, Index)Þmatrix
|
|
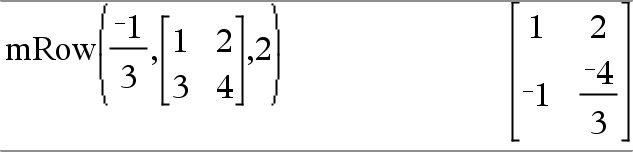
|
Catalogus > |
|
|
mRowAdd(Waarde, Matrix1, Index1, Index2) Þmatrix Geeft een kopie van Matrix1 met elk element in rij Index2 van Matrix1 vervangen door: |
|
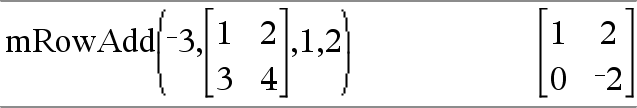
|
Catalogus > |
|
|
MultReg Y, X1[,X2[,X3,…[,X10]]] Berekent een meervoudige lineaire regressie van lijst Y op de lijsten X1, X2, …, X10. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Alle lijsten moeten gelijke afmetingen hebben. Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: b0+b1·x1+b2·x2+ ... |
|
stat.b0, stat.b1, ... |
Regressiecoëfficiënten |
|
stat.R2 |
Coëfficiënt van meervoudige determinatie |
|
stat.yLijst |
yLijst = b0+b1·x1+ ... |
|
stat.Resid |
Residuen uit de regressie |
|
Catalogus > |
|
|
MultRegIntervals Y, X1[,X2[,X3,…[,X10]]],XWaardeLijst[,CNiveau] Berekent een voorspelde y-waarde, een niveau C voorspellingsinterval voor één observatie en een niveau C betrouwbaarheidsinterval voor de gemiddelde respons. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Alle lijsten moeten gelijke afmetingen hebben. Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: b0+b1·x1+b2·x2+ ... |
|
stat.y |
Een puntschatting: y = b0 + b1 · xl + ... voor XWaardeLijst |
|
stat.dfError |
Vrijheidsgraden van de fouten |
|
stat.CLower, stat.CUpper |
Betrouwbaarheidsinterval voor een gemiddelde respons |
|
stat.ME |
Foutmarge betrouwbaarheidsinterval |
|
stat.SE |
Standaardfout van de gemiddelde respons |
|
stat.LowerPred, stat.UpperPred |
Voorspellingsinterval voor één observatie |
|
stat.MEPred |
Foutmarge voor voorspellingsinterval |
|
stat.SEPred |
Standaardfout voor voorspelling |
|
stat.bList |
Lijst van regressiecoëfficiënten, {b0,b1,b2,...} |
|
stat.Resid |
Residuen uit de regressie |
|
Catalogus > |
|
|
MultRegTests Y, X1[,X2[,X3,…[,X10]]] Meervoudige lineaire regressietoets berekent een meervoudige lineaire regressie op de gegevens, en biedt de globale F-toets-statistiek en t-toets-statistieken voor de coëfficiënten. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
Uitvoer
|
Uitvoervariabele |
Beschrijving |
|
stat.RegEqn |
Regressievergelijking: b0+b1·x1+b2·x2+ ... |
|
stat.F |
Globale F-toets-statistiek |
|
stat.PVal |
P-waarde geassocieerd met de globale F-statistiek |
|
stat.R2 |
Coëfficiënt van meervoudige determinatie |
|
stat.AdjR2 |
Aangepaste coëfficiënt van meervoudige determinatie |
|
stat.s |
Standaarddeviatie van de fout |
|
stat.DW |
Durbin-Watson-statistiek; wordt gebruikt om te bepalen of er automatische correlatie van de eerste orde aanwezig is in het model |
|
stat.dfReg |
Vrijheidsgraden van de regressie |
|
stat.SSReg |
Som van de kwadraten van de regressies |
|
stat.MSReg |
Gemiddelde kwadraat van de regressies |
|
stat.dfError |
Vrijheidsgraden van de fouten |
|
stat.SSError |
Som van de kwadraten van de fouten |
|
stat.MSError |
Gemiddelde kwadraat van de fouten |
|
stat.bList |
{b0,b1,...} Lijst van coëfficiënten |
|
stat.tList |
Lijst van t-statistieken, één voor elke coëfficiënt in de bLijst |
|
stat.PList |
Lijst van P-waarden voor elke t-statistiek |
|
stat.SEList |
Lijst van standaardfouten voor coëfficiënten in bLijst |
|
stat.yLijst |
yLijst = b0+b1·x1+ . . . |
|
stat.Resid |
Residuen uit de regressie |
|
stat.sResid |
Gestandaardiseerde residuen; verkregen door een residu te delen door zijn standaarddeviatie |
|
stat.CookDist |
Afstand van Cook; maat voor de invloed van een observatie op basis van het residue en de invloed |
|
stat.Leverage |
Maat voor hoever de waarden van de onafhankelijke variabelen van hun gemiddelde waarden af liggen |