|
Catalogus > |
|||||||||||||
|
factor(rationaalGetal) geeft het rationale getal ontbonden in priemfactoren. Bij samengestelde getallen neemt de berekeningstijd exponentieel toe met het aantal cijfers in de op één na grootste factor. Het ontbinden van een geheel getal van 30 cijfers kan bijvoorbeeld langer dan een dag duren, en het ontbinden van een geheel getal van 100 cijfers kan meer dan een eeuw duren. Een berekening handmatig stoppen:
Als u alleen wilt bepalen of een getal een priemgetal is, gebruik dan liever isPrime(). Dat is veel sneller, vooral als rationaalGetal geen priemgetal is en als de op één na grootste factor meer dan vijf cijfers heeft. |
|


|
Catalogus > |
|
|
FCdf(ondergrens,bovengrens,dfTeller,dfNoemer)Þgetal als ondergrens en bovengrens getallen zijn, lijst als ondergrens en bovengrens lijsten zijn FCdf(ondergrens,bovengrens,dfTeller,dfNoemer)Þgetal als ondergrens en bovengrens getallen zijn, lijst als ondergrens en bovengrens lijsten zijn Berekent de F-kansverdeling tussen ondergrens en bovengrens voor de gespecificeerde dfTeller (aantal vrijheidsgraden) en dfNoemer. Bij P(X { bovengrens) is de ingestelde ondergrens =0. |
|
|
Catalogus > |
|
|
Fill Waarde, matrixVarÞmatrix Vervangt ieder element in variabele matrixVar door Waarde. matrixVar moet al bestaan. |
|
|
Fill Waarde, lijstVarÞlijst Vervang ieder element in variabele lijstVar door Waarde. lijstVar moet al bestaan. |
|


|
Catalogus > |
|
|
FiveNumSummary X[,[Freq][,Categorie,Opnemen]] Levert een verkorte versie van de statistieken voor 1 variabele van lijst X. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.resultaten (hier). X representeert een lijst met de gegevens. Freq is een optionele lijst met frequentiewaarden. Elk element in Freq specificeert de frequentie waarmee elke overeenkomstige X-waarde voorkomt. De standaardwaarde is 1. Alle elementen moeten gehele getallen | 0 zijn. Categorie is een lijst met numerieke categoriecodes voor de overeenkomstige X-waarden. Opnemen is een lijst met één of meer van de categoriecodes. Alleen de gegevens waarvan de categoriecode is opgenomen in deze lijst worden opgenomen in de berekening. Een leeg element in een van de lijsten X, Freq of Categorie resulteert in een lege plaats voor het overeenkomstige element in al deze lijsten. Voor meer informatie over lege elementen, zie hier. |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.MinX |
Minimum van de x-waarden |
|
stat.Q1X |
1ste kwartiel van x |
|
stat.MedianX |
Mediaan van x |
|
stat.Q3X |
3de kwartiel van x |
|
stat.MaxX |
Maximum van de x-waarden |
|
Catalogus > |
|
|
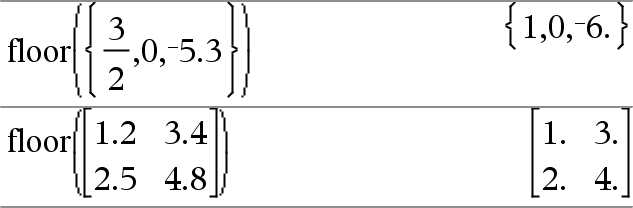
floor(Waarde1)Þgeheel getal Geeft het grootste gehele getal dat { dan het argument. Deze functie is hetzelfde als int(). Het argument kan een reëel of complex getal zijn. |
|
|
floor(Lijst1)Þlijst floor(Matrix1)Þmatrix Geeft een lijst of matrix van de floor-waarde van elk element. Opmerking: zie ook ceiling() en int(). |
|

|
Catalogus > |
|
|
For Var, Laag, Hoog [, Stap] Voert de beweringen in Blok iteratief uit voor elke waarde van Var, van Laag naar Hoog, in stappen van Stap. Var mag geen systeemvariabele zijn. Stap kan positief of negatief zijn. De standaardwaarde is 1. Blok kan een enkele bewering of een serie beweringen zijn die gescheiden worden door het teken “:”. Opmerking bij het invoeren van het voorbeeld: Instructies over het invoeren van programma's met meerdere regels en functiedefinities vindt u in het hoofdstuk Rekenmachine van de handleiding van uw product. |
|

|
Catalogus > |
|
|
format(Waarde[, opmaakString])Þstring Geeft Waarde als een tekenreeks op basis van de opmaaktemplate. opmaakString is een string die de volgende vorm moet hebben: “F[n]”, “S[n]”, “E[n]”, “G[n][c]”, waarbij [ ] optionele gedeeltes aangeeft. F[n]: Vaste opmaak. n is het aantal cijfers dat weergegeven moet worden achter de decimale punt. S[n]: Wetenschappelijke opmaak. n is het aantal cijfers dat weergegeven moet worden achter de decimale punt. E[n]: Ingenieursopmaak. n is het aantal cijfers na het eerste significante cijfer. De exponent wordt aangepast naar een veelvoud van drie, en de decimale punt wordt met nul, één of twee cijfers naar rechts verplaatst. G[n][c]: Zelfde als de vaste opmaak, maar scheidt de cijfers links van de radix (decimale scheidingsteken) tevens in groepen van drie. c specificeert het groep-scheidingsteken; de standaardinstelling is een komma. Als c een punt is, wordt de radix weergegeven als een komma. [Rc]: Elk van bovengenoemde specificatietekens kan als suffix de Rc radix-vlag krijgen, waarbij c een enkel teken is dat specificeert wat er gesubstitueerd moet worden voor het radixpunt. |
|

|
Catalogus > |
|
|
fPart(Uitdr1)Þuitdrukking fPart(Lijst1)Þlijst fPart(Matrix1)Þmatrix Geeft de breuk van het argument. Geeft bij een lijst of matrix de breuk van de elementen. Het argument kan een reëel of complex getal zijn. |
|

|
Catalogus > |
|
|
FPdf(XWaarde,dfTeller,dfNoemer)Þgetal als XWaarde een getal is, lijst als XWaarde een lijst is Berekent de kans voor de F-verdeling bij XWaarde voor de gespecificeerde dfTeller (vrijheidsgraden) en dfNoemer. |
|
|
Catalogus > |
|
|
freqTable4list(Lijst1,freqGeheelGetalLijst)Þlijst Geeft een lijst met de elementen uit Lijst1 uitgebreid volgens de frequenties in freqGeheelGetalLijst. Deze functie kan gebruikt worden om een frequentietabel voor de Gegevensverwerking & Statistiek-toepassing samen te stellen. Lijst1 kan elke geldige lijst zijn. freqGeheelGetalLijst moet dezelfde afmeting als Lijst1 hebben en mag alleen niet-negatieve gehele getallen bevatten. Elk element specificeert het aantal keer dat het overeenkomstige element uit Lijst1 wordt herhaald in de resulterende lijst. Een waarde van nul sluit het overeenkomstige Lijst1-element uit. Opmerking: u kunt deze operator vanaf het toetsenbord van de computer invoeren door freqTable@>list(...) in te typen. Lege elementen worden genegeerd. Voor meer informatie over lege elementen, zie hier. |
|

|
Catalogus > |
|
|
frequency(Lijst1,klassenLijst)Þlijst Geeft een lijst met de aantallen elementen in Lijst1. De aantallen zijn gebaseerd op klassen die u definieert in klassenLijst. Als klassenLijst {b(1), b(2), …, b(n)} is, dan zijn de gespecificeerde klassen {?{b(1), b(1)<?{b(2),…,b(n-1)<?{b(n), b(n)>?}. De resulterende lijst is één element langer dan klassenLijst. Elk element van het resultaat komt overeen met het aantal elementen in Lijst1 die binnen die klasse liggen. Uitgedrukt in termen van de countIf()-functie is het resultaat { countIf(list, ?{b(1)), countIf(list, b(1)<?{b(2)), …, countIf(list, b(n-1)<?{b(n)), countIf(list, b(n)>?)}. Elementen van Lijst1 die niet “in een klasse geplaatst kunnen worden” worden genegeerd. Lege elementen worden eveneens genegeerd. Voor meer informatie over lege elementen, zie hier. In de toepassing Lijsten & Spreadsheet kunt u een reeks cellen op de plaats van beide argumenten gebruiken. Opmerking: zie ook countIf(), hier. |
Uitleg van het resultaat: 2 elementen van Datalist zijn {2,5 4 elementen van Datalist zijn >2,5 en {4,5 3 elementen van Datalist zijn >4,5 Het element “hello” is een string en kan niet in een van de gedefinieerde klassen geplaatst worden. |

|
Catalogus > |
|
|
FTest_2Samp Lijst1,Lijst2[,Freq1[,Freq2[,Hypoth]]] FTest_2Samp Lijst1,Lijst2[,Freq1[,Freq2[,Hypoth]]] (Invoer van een gegevenslijst) FTest_2Samp sx1,n1,sx2,n2[,Hypoth] FTest_2Samp sx1,n1,sx2,n2[,Hypoth] (Invoer van samenvattingsstatistieken) Voert een F -toets met twee steekproeven uit. Een samenvatting van de resultaten wordt opgeslagen in de variabele stat.results (hier). Voor H1: s1 > s2 stelt u Hypoth>0 in Voor H1: s1 ƒ s2 (standaardinstelling) stelt u Hypoth = 0 in Voor H1: s1 < s2 stelt u Hypoth<0 in Zie voor informatie over het effect van lege elementen in een lijst “Lege elementen” (hier). |
|
|
Uitvoervariabele |
Beschrijving |
|
stat.F |
Berekende Û-statistiek voor de gegevensverzameling |
|
stat.PVal |
Kleinste significantieniveau waarbij de nulhypothese verworpen kan worden |
|
stat.dfNumer |
teller vrijheidsgraden = n1-1 |
|
stat.dfDenom |
noemer vrijheidsgraden = n2-1 |
|
stat.sx1, stat.sx2 |
Steekproefstandaarddeviatie van de gegevensverzamelingen in Lijst 1 en Lijst 2 |
|
stat.x1_bar stat.x2_bar |
Steekproefgemiddelde van de gegevensverzamelingen in Lijst 1 en Lijst 2 |
|
stat.n1, stat.n2 |
Grootte van de steekproeven |
|
Catalogus > |
|
|
Func Template voor het creëren van een door de gebruiker gedefinieerde functie. Blok kan een enkele bewering of een serie beweringen zijn die gescheiden worden door het teken “:”, of een serie beweringen op aparte regels. De functie kan de instructie Return gebruiken om een specifiek resultaat te retourneren. Opmerking bij het invoeren van het voorbeeld: Instructies over het invoeren van programma's met meerdere regels en functiedefinities vindt u in het hoofdstuk Rekenmachine van de handleiding van uw product. |
Een stuksgewijs gedefinieerde functie definiëren:
Resultaat grafiek g(x)
|