|
Katalog > |
|||||||||||||
|
factor(RationaleZahl) ergibt die rationale Zahl in Primfaktoren zerlegt. Bei zusammengesetzten Zahlen nimmt die Berechnungsdauer exponentiell mit der Anzahl an Stellen im zweitgrößten Faktor zu. Das Faktorisieren einer 30-stelligen ganzen Zahl kann beispielsweise länger als einen Tag dauern und das Faktorisieren einer 100-stelligen Zahl mehr als ein Jahrhundert. So halten Sie eine Berechnung manuell an:
Möchten Sie hingegen lediglich feststellen, ob es sich bei einer Zahl um eine Primzahl handelt, verwenden Sie isPrime(). Dieser Vorgang ist wesentlich schneller, insbesondere dann, wenn RationaleZahl keine Primzahl ist und der zweitgrößte Faktor mehr als fünf Stellen aufweist. |
|


|
Katalog > |
|
|
FCdf(UntGrenze,ObGrenze,FreiGradZähler,FreiGradNenner)ÞZahl, wenn UntGrenze und ObGrenze Zahlen sind, Liste, wenn UntGrenze und ObGrenze Listen sind FCdf(UntGrenze,ObGrenze,FreiGradZähler,FreiGradNenner)ÞZahl, wenn UntGrenze und ObGrenze Zahlen sind, Liste, wenn UntGrenze und ObGrenze Listen sind Berechnet die F Verteilungswahrscheinlichkeit zwischen UntereGrenze und ObereGrenze für die angegebenen FreiGradZähler (Freiheitsgrade) und FreiGradNenner. Für P(X { ObereGrenze), UntGrenze =0 setzen. |
|
|
Katalog > |
|
|
Fill Zahl, MatrixVarÞMatrix Ersetzt jedes Element in der Variablen MatrixVar durch Zahl. MatrixVar muss bereits vorhanden sein. |
|
|
Fill Zahl, ListeVarÞListe Ersetzt jedes Element in der Variablen ListeVar durch Zahl. ListeVar muss bereits vorhanden sein. |
|


|
Katalog > |
|
|
FiveNumSummary X[,[Häuf][,Kategorie,Mit]] Bietet eine gekürzte Version der Statistik mit 1 Variablen auf Liste X. Eine Zusammenfassung der Ergebnisse wird in der Variablen stat.results gespeichert. (hier.) X stellt eine Liste mit den Daten dar. Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in Häuf gibt die Häufigkeit für jeden entsprechenden X-Wert an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein. Kategorie ist eine Liste von Kategoriecodes Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur solche Datenelemente, deren Kategoriecode in dieser Liste enthalten ist, sind in der Berechnung enthalten. Ein leeres (ungültiges) Element in einer der Listen X, Freq oder Kategorie führt zu einem Fehler im entsprechenden Element aller dieser Listen. Weitere Informationen zu leeren Elementen finden Sie (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
stat.MinX |
Minimum der x-Werte |
|
stat.Q1X |
1. Quartil von x |
|
stat.MedianX |
Median von x |
|
stat.Q3X |
3. Quartil von x |
|
stat.MaxX |
Maximum der x-Werte |
|
Katalog > |
|
|
floor(Wert1)ÞGanzzahl Gibt die größte ganze Zahl zurück, die { dem Argument ist. Diese Funktion ist identisch mit int(). Das Argument kann eine reelle oder eine komplexe Zahl sein. |
|
|
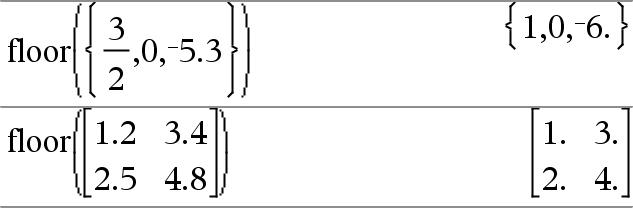
floor(Liste1)ÞListe floor(Matrix1)ÞMatrix Für jedes Element einer Liste oder Matrix wird die größte ganze Zahl, die kleiner oder gleich dem Element ist, zurückgegeben. Hinweis: Siehe auch ceiling() und int(). |
|

|
Katalog > |
|
|
For Var, Von, Bis [, Schritt] Führt die in Block befindlichen Anweisungen für jeden Wert von Var zwischen Von und Bis aus, wobei der Wert bei jedem Durchlauf um Schritt inkrementiert wird. Var darf keine Systemvariable sein. Schritt kann positiv oder negativ sein. Der Standardwert ist 1. Block kann eine einzelne Anweisung oder eine Serie von Anweisungen sein, die durch “:” getrennt sind. Hinweis zum Eingeben des Beispiels: Anweisungen für die Eingabe von mehrzeiligen Programm- und Funktionsdefinitionen finden Sie im Abschnitt „Calculator“ des Produkthandbuchs. |
|

|
Katalog > |
|
|
format(Wert[, FormatString])ÞString Gibt Wert als Zeichenkette im Format der Formatvorlage zurück. FormatString ist eine Zeichenkette und muss diese Form besitzen: “F[n]”, “S[n]”, “E[n]”, “G[n][c]”, wobei [ ] optionale Teile bedeutet. F[n]: Festes Format. n ist die Anzahl der angezeigten Nachkommastellen (nach dem Dezimalpunkt). S[n]: Wissenschaftliches Format. n ist die Anzahl der angezeigten Nachkommastellen (nach dem Dezimalpunkt). E[n]: Technisches Format. n ist die Anzahl der Stellen, die auf die erste signifikante Ziffer folgen. Der Exponent wird auf ein Vielfaches von 3 gesetzt, und der Dezimalpunkt wird um null, eine oder zwei Stellen nach rechts verschoben. G[n][c]: Wie Festes Format, unterteilt jedoch auch die Stellen links des Dezimaltrennzeichens in Dreiergruppen. c ist das Gruppentrennzeichen und ist auf “Komma” voreingestellt. Wenn c auf “Punkt” gesetzt wird, wird das Dezimaltrennzeichen zum Komma. [Rc]: Jeder der vorstehenden Formateinstellungen kann als Suffix das Flag Rc nachgestellt werden, wobei c ein einzelnes Zeichen ist, das den Dezimalpunkt ersetzt. |
|

|
Katalog > |
|
|
fPart(Ausdr1)ÞAusdruck fPart(Liste1)ÞListe fPart(Matrix1)ÞMatrix Gibt den Bruchanteil des Arguments zurück. Bei einer Liste bzw. Matrix werden die Bruchanteile aller Elemente zurückgegeben. Das Argument kann eine reelle oder eine komplexe Zahl sein. |
|

|
Katalog > |
|
|
FPdf(XWert,FreiGradZähler,FreiGradNenner)ÞZahl, wenn XWert eine Zahl ist, Liste, wenn XWert eine Liste ist FPdf(XWert,FreiGradZähler,FreiGradNenner)ÞZahl, wenn XWert eine Zahl ist, Liste, wenn XWert eine Liste ist Berechnet die F Verteilungswahrscheinlichkeit bei XWert für die angegebenen FreiGradZähler (Freiheitsgrade) und FreiGradNenner. |
|
|
Katalog > |
|
|
freqTable4list(Liste1,HäufGanzzahlListe)ÞListe Gibt eine Liste zurück, die die Elemente von Liste1 erweitert gemäß den Häufigkeiten in HäufGanzzahlListe enthält. Diese Funktion kann zum Erstellen einer Häufigkeitstabelle für die Applikation 'Data & Statistics' verwendet werden. Liste1 kann eine beliebige gültige Liste sein. HäufGanzzahlListe muss die gleiche Dimension wie Liste1 haben und darf nur nicht-negative Ganzzahlelemente enthalten. Jedes Element gibt an, wie oft das entsprechende Liste1-Element in der Ergebnisliste wiederholt wird. Der Wert 0 schließt das entsprechende Liste1-Element aus. Hinweis: Sie können diese Funktion über die Tastatur Ihres Computers eingeben, indem Sie freqTable@>list(...) eintippen Leere (ungültige) Elemente werden ignoriert. Weitere Informationen zu leeren Elementen finden Sie (hier). |
|

|
Katalog > |
|
|
frequency(Liste1,binsListe)ÞListe Gibt eine Liste zurück, die die Zähler der Elemente in Liste1 enthält. Die Zähler basieren auf Bereichen (bins), die Sie in binsListe definieren. Wenn binsListe {b(1), b(2), …, b(n)} ist, sind die festgelegten Bereiche {?{b(1), b(1)<?{b(2),…,b(n-1)<?{b(n), b(n)>?}. Die Ergebnisliste enthält ein Element mehr als die binsListe. Jedes Element des Ergebnisses entspricht der Anzahl der Elemente aus Liste1, die im Bereich dieser bins liegen. Ausgedrückt in Form der countIf() Funktion ist das Ergebnis { countIf(Liste, ?{b(1)), countIf(Liste, b(1)<?{b(2)), …, countIf(Liste, b(n-1)<?{b(n)), countIf(Liste, b(n)>?)}. Elemente von Liste1, die nicht “in einem bin platziert” werden können, werden ignoriert. Leere (ungültige) Elemente werden ebenfalls ignoriert. Weitere Informationen zu leeren Elementen finden Sie (hier). Innerhalb der Lists & Spreadsheet Applikation können Sie für beide Argumente Zellenbereiche verwenden. Hinweis: Siehe auch countIf(), hier. |
Erklärung des Ergebnisses: 2 Elemente aus Datenliste (Datalist) sind {2.5 4 Elemente aus Datenliste sind >2.5 und {4.5 3 Elemente aus Datenliste sind >4.5 Das Element “Hallo” ist eine Zeichenfolge und kann nicht in einem der definierten bins platziert werden. |

|
Katalog > |
|
|
FTest_2Samp Liste1,Liste2[,Häufigkeit1[,Häufigkeit2[,Hypoth]]] FTest_2Samp Liste1,Liste2[,Häufigkeit1[,Häufigkeit2[,Hypoth]]] (Datenlisteneingabe) FTest_2Samp sx1,n1,sx2,n2[,Hypoth] FTest_2Samp sx1,n1,sx2,n2[,Hypoth] (Zusammenfassende statistische Eingabe) Führt einen F -Test mit zwei Stichproben durch. Eine Zusammenfassung der Ergebnisse wird in der Variable stat.results gespeichert. (hier.) Für Ha: s1 > s2 setzen Sie Hypoth>0 Für Ha: s1 ƒ s2 (Standard) setzen Sie Hypoth =0 Für Ha: s1 < s2 setzen Sie Hypoth<0 Informationen zu den Auswirkungen leerer Elemente in einer Liste finden Sie unter “Leere (ungültige) Elemente” (hier). |
|
|
Ausgabevariable |
Beschreibung |
|
Statistik.F |
Berechnete Û Statistik für die Datenfolge |
|
stat.PVal |
Kleinste Signifikanzebene, bei der die Nullhypothese verworfen werden kann |
|
stat.dfNumer |
Freiheitsgrade des Zählers = n1-1 |
|
stat.dfDenom |
Freiheitsgrade des Nenners = n2-1 |
|
stat.sx1, stat.sx2 |
Stichproben-Standardabweichungen der Datenfolgen in Liste 1 und Liste 2 |
|
stat.x1_bar stat.x2_bar |
Stichprobenmittelwerte der Datenfolgen in Liste 1 und Liste 2 |
|
stat.n1, stat.n2 |
Stichprobenumfang |
|
Katalog > |
|
|
Func Vorlage zur Erstellung einer benutzerdefinierten Funktion. Block kann eine einzelne Anweisung, eine Reihe von durch das Zeichen “:” voneinander getrennten Anweisungen oder eine Reihe von Anweisungen in separaten Zeilen sein. Die Funktion kann die Anweisung Zurückgeben (Return) verwenden, um ein bestimmtes Ergebnis zurückzugeben. Hinweis zum Eingeben des Beispiels: Anweisungen für die Eingabe von mehrzeiligen Programm- und Funktionsdefinitionen finden Sie im Abschnitt „Calculator“ des Produkthandbuchs. |
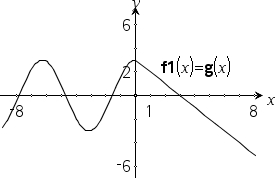
Definieren Sie eine stückweise definierte Funktion:
Ergebnis der graphischen Darstellung g(x)
|