|
Katalog > |
|
|
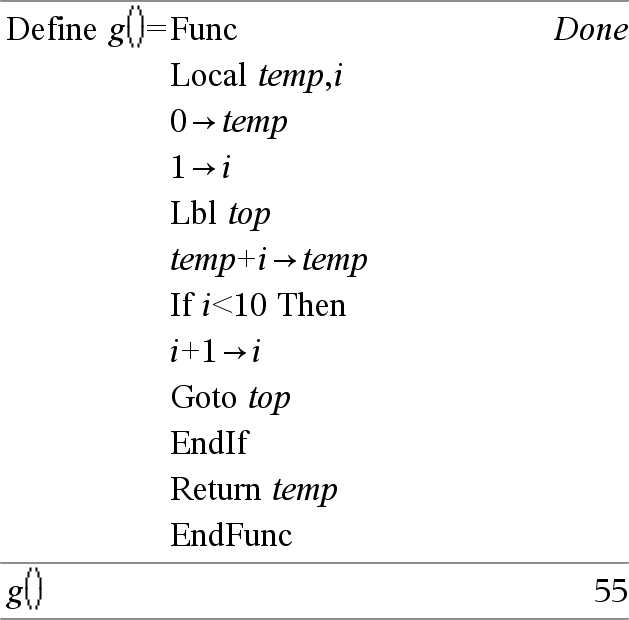
Lbl labelName Definierar en etikett med namnet labelName inom en funktion. Du kan använda en Goto labelName-instruktion för att överföra kontroll till instruktionen direkt efter etiketten. labelName måste uppfylla samma krav på namngivning som ett variabelnamn. Obs för att mata in exemplet: Se avsnittet Räknare i produkthandboken för instruktioner om hur du anger multiline-program och funktionsdefinitioner. |
|

|
Katalog > |
|
|
lcm(Number1, Number2)Þuttryck lcm(List1, List2)Þlista lcm(Matrix1, Matrix2)Þmatris Ger den minsta gemensamma multipeln för de två argumenten. lcm för två bråk är lcm för deras täljare dividerat med gcd för deras nämnare. lcm för tal i flyttalsform är deras produkt. Ger, för två listor eller matriser, den minsta gemensamma multipeln för de motsvarande elementen. |
|
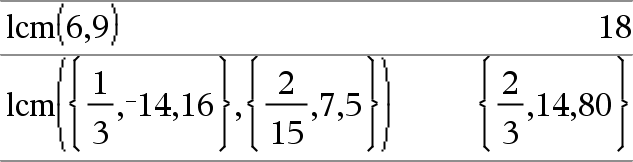
|
Katalog > |
|
|
left(sourceString[, Num])Þsträng Ger Num-tecknen längst till vänster i teckensträngen sourceString. Om du utelämnar Num erhålls alla i sourceString. |
|
|
left(List1[, Num])Þlista Ger Num-elementen längst till vänster i List1. Om du utelämnar Num erhålls alla i List1. |
|
|
left(Comparison)Þuttryck Ger den vänstra sidan av en ekvation eller olikhet. |


|
Katalog > |
|
|
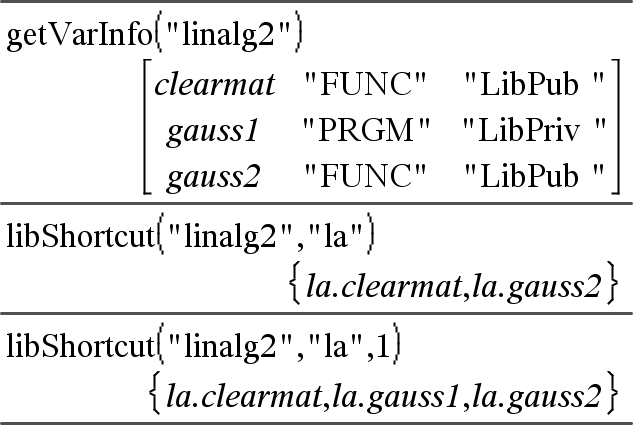
libShortcut(LibNameString, ShortcutNameString [, LibPrivFlag])Þlista på variabler Skapar en variabelgrupp i det aktuella problemet som innehåller referenser till alla objekt i det specificerade biblioteksdokumentet libNameString. Lägger också till gruppmedlemmarna på menyn Variables. Du kan sedan referera till varje objekt med hjälp av dess ShortcutNameString. Ställ LibPrivFlag=0 för att utesluta privata biblioteksobjekt (förinställning) Ställ LibPrivFlag=1 för att inkludera privata biblioteksobjekt För att kopiera en variabelgrupp, se CopyVar, här. För att ta bort en variabelgrupp, se DelVar, här. |
Detta exempel förutsätter ett korrekt lagrat och uppdaterat biblioteksdokument med namnet linalg2 och som innehåller objekt definierade som clearmat, gauss1 och gauss2.
|
|
Katalog > |
|
|
LinRegBx X,Y[,[Freq][,Category,Include]] Utför den linjära regressionsanalysen y = a+b·xpå listorna X och Y med frekvensen Freq. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Alla listor utom Include måste ha samma dimensioner. X och Y är listor på oberoende och beroende variabler. Freq är en frivillig lista på frekvensvärden. Varje element i Freq specificerar frekvensen för varje motsvarande X- och Y-datapunkt. Det förinställda värdet är 1. Alla element måste vara heltal | 0. Category är en lista på Include är en lista på en eller flera av kategorikoderna. Endast de dataobjekt vars kategorikod är med på listan tas med i beräkningen. För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.RegEqn |
Regressionsekvation: a+b·x |
|
stat.a, stat.b |
Regressionskoefficienter |
|
stat.r2 |
Determinationskoefficient |
|
stat.r |
Korrelationskoefficient |
|
stat.Resid |
Residualer från regressionen |
|
stat.XReg |
Lista på datapunkter i den modifierade X List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.YReg |
Lista på datapunkter i den modifierade Y List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.FreqReg |
Lista på frekvenser som motsvarar stat.XReg och stat.YReg |
|
Katalog > |
|
|
LinRegMx X,Y[,[Freq][,Category,Include]] Beräknar den linjära regressionen y = m·x+b på listorna X och Y med frekvensen Freq. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Alla listor utom Include måste ha samma dimensioner. X och Y är listor på oberoende och beroende variabler. Freq är en frivillig lista på frekvensvärden. Varje element i Freq specificerar frekvensen för varje motsvarande X- och Y-datapunkt. Det förinställda värdet är 1. Alla element måste vara heltal | 0. Category är en lista på Include är en lista på en eller flera av kategorikoderna. Endast de dataobjekt vars kategorikod är med på listan tas med i beräkningen. För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.RegEqn |
Regressionsekvation: m·x+b |
|
stat.m, stat.b |
Regressionskoefficienter |
|
stat.r2 |
Determinationskoefficient |
|
stat.r |
Korrelationskoefficient |
|
stat.Resid |
Residualer från regressionen |
|
stat.XReg |
Lista på datapunkter i den modifierade X List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.YReg |
Lista på datapunkter i den modifierade Y List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.FreqReg |
Lista på frekvenser som motsvarar stat.XReg och stat.YReg |
|
Katalog > |
|
|
LinRegtIntervals X,Y[,F[,0[,CLev]]] För Slope (Lutning). Beräknar ett nivå-C-konfidensintervall för lutningen. LinRegtIntervals X,Y[,F[,1,Xval[,CLev]]] För Response (Svar). Beräknar ett prognostiserat y-värde, ett nivå-C-prediktionsintervall för en enstaka observation och ett nivå-C-konfidensintervall för medelvärdet på svaret. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Alla listor måste ha samma dimensioner. X och Y är listor på oberoende och beroende variabler. F är en frivillig lista på frekvensvärden. Varje element i F specificerar förekomsten av varje motsvarande X- och Y-datapunkt. Det förinställda värdet är 1. Alla element måste vara heltal | 0. För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.RegEqn |
Regressionsekvation: a+b·x |
|
stat.a, stat.b |
Regressionskoefficienter |
|
stat.df |
Frihetsgrader |
|
stat.r2 |
Determinationskoefficient |
|
stat.r |
Korrelationskoefficient |
|
stat.Resid |
Residualer från regressionen |
Endast för typen Slope
|
Resultatvariabel |
Beskrivning |
|
[stat.CLower, stat.CUpper] |
Konfidensintervall för lutningen |
|
stat.ME |
Konfidensintervall - felmarginal |
|
stat.SESlope |
Standardfel hos lutning |
|
stat.s |
Standardfel hos linjen |
Endast för typen Response
|
Resultatvariabel |
Beskrivning |
|
[stat.CLower, stat.CUpper] |
Konfidensintervall för medelvärdet på svaret |
|
stat.ME |
Konfidensintervall - felmarginal |
|
stat.SE |
Standardfel hos medelsvar |
|
[stat.LowerPred, stat.UpperPred] |
Prediktionsintervall för en enstaka observation |
|
stat.MEPred |
Prognostiseringsintervall - felmarginal |
|
stat.SEPred |
Standardfel för prognostisering |
|
stat.y |
a + b·XVal |
|
Katalog > |
|
|
LinRegtTest X,Y[,Freq[,Hypoth]] Utför en linjär regressionsanalys på listorna X och Y och ett t-test på lutningens värde b samt korrelationskoefficienten r för ekvationen y=a+bx. Det testar nollhypotesen H0:b=0 (equivalently, r=0) mot en av tre alternativa hypoteser. Alla listor måste ha samma dimensioner. X och Y är listor på oberoende och beroende variabler. Freq är en frivillig lista på frekvensvärden. Varje element i Freq specificerar frekvensen för varje motsvarande X- och Y-datapunkt. Det förinställda värdet är 1. Alla element måste vara heltal | 0. Hypoth är ett valfritt värde som specificerar en av tre alternativa hypoteser mot vilka nollhypotesen (H0:b=r=0) kommer att testas. För Ha: bƒ0 och rƒ0 (förinställning), ställ Hypoth=0 För Ha: b<0 och r<0, ställ Hypoth<0 För Ha: b>0 och r>0, ställ Hypoth>0 En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.RegEqn |
Regressionsekvation: a + b·x |
|
stat.t |
t-Statistik för signifikanstest |
|
stat.PVal |
Lägsta signifikansnivå vid vilken nollhypotesen kan förkastas |
|
stat.df |
Frihetsgrader |
|
stat.a, stat.b |
Regressionskoefficienter |
|
stat.s |
Standardfel hos linjen |
|
stat.SESlope |
Standardfel hos lutning |
|
stat.r2 |
Determinationskoefficient |
|
stat.r |
Korrelationskoefficient |
|
stat.Resid |
Residualer från regressionen |
|
Katalog > |
|
|
Ger en lista på lösningar för variablerna Var1, Var2, ... Det första argumentet måste beräknas till ett system av linjära ekvationer eller en enda linjär ekvation. Annars inträffar ett argumentfel. Som exempel leder beräkningen linSolve(x=1 och x=2,x) till ett "Argumentfel"-resultat. |
|

|
Katalog > |
|
|
@List(List1)Þlista Obs: Du kan infoga denna funktion med datorns tangentbord genom att skriva deltaList(...). Ger en lista på skillnaderna mellan konsekutiva element i List1. Varje element i List1 subtraheras från nästa element i List1. Den resulterande listan är alltid ett element kortare än den ursprungliga List1. |
|
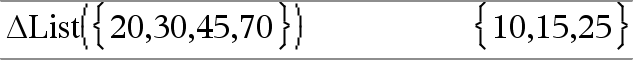
|
Katalog > |
|
|
list4mat(List [, elementsPerRow])Þmatris Ger en matris fylld rad efter rad med elementen från List. elementsPerRow, om inkluderad, specificerar antalet element per rad. Förinställningen är antalet element i List (en rad). Om List inte fyller den resulterande listan läggs nollor till. Obs: Du kan infoga denna funktion med datorns tangentbord genom att skriva list@>mat(...). |
|
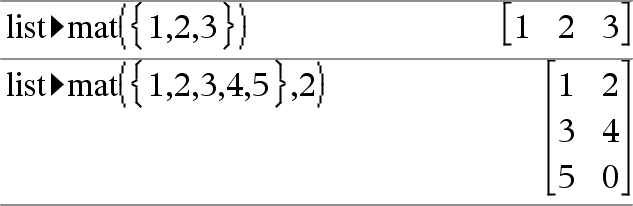
|
/u tangenter |
|
|
ln(Value1)Þvärde ln(List1)Þlista Ger argumentets naturliga logaritm. Ger, för en lista, elementens naturliga logaritmer. |
Om det komplexa formatläget är Real:
Om det komplexa formatläget är Rectangular:
|
|
ln(squareMatrix1)ÞkvadratMatris Ger matrisen med naturlig logaritm för squareMatrix1. Detta är inte detsamma som att beräkna den naturliga logaritmen för varje element. För information om beräkningsmetoden, se cos(). squareMatrix1 måste vara möjlig att diagonalisera. Resultatet visas alltid i flyttalsform. |
I vinkelläget Radianer och i Rektangulärt komplext format:
För att se hela resultatet, tryck på 5 och använd sedan 7 och 8 för att flytta markören. |


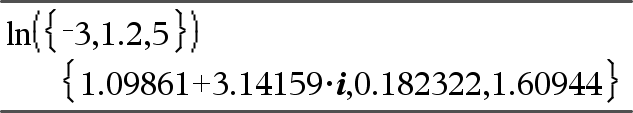

|
Katalog > |
|
|
LnReg X, Y[, [Freq] [, Category, Include]] Utför en en logaritmisk regressionsanalys y = a+b·ln(x) på listorna X och Y med frekvensen Freq. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Alla listor utom Include måste ha samma dimensioner. X och Y är listor på oberoende och beroende variabler. Freq är en frivillig lista på frekvensvärden. Varje element i Freq specificerar frekvensen för varje motsvarande X- och Y-datapunkt. Det förinställda värdet är 1. Alla element måste vara heltal | 0. Category är en lista på Include är en lista på en eller flera av kategorikoderna. Endast de dataobjekt vars kategorikod är med på listan tas med i beräkningen. För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.RegEqn |
Regressionsekvation: a+b·ln(x) |
|
stat.a, stat.b |
Regressionskoefficienter |
|
stat.r2 |
Koefficient för linjär bestämning av transformerade data |
|
stat.r |
Korrelationskoefficient för transformerade data (ln(x), y) |
|
stat.Resid |
Residualer associerade med den logaritmiska modellen |
|
stat.ResidTrans |
Residualer associerade med linjär anpassning av transformerade data |
|
stat.XReg |
Lista på datapunkter i den modifierade X List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.YReg |
Lista på datapunkter i den modifierade Y List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.FreqReg |
Lista på frekvenser som motsvarar stat.XReg och stat.YReg |
|
Katalog > |
|
|
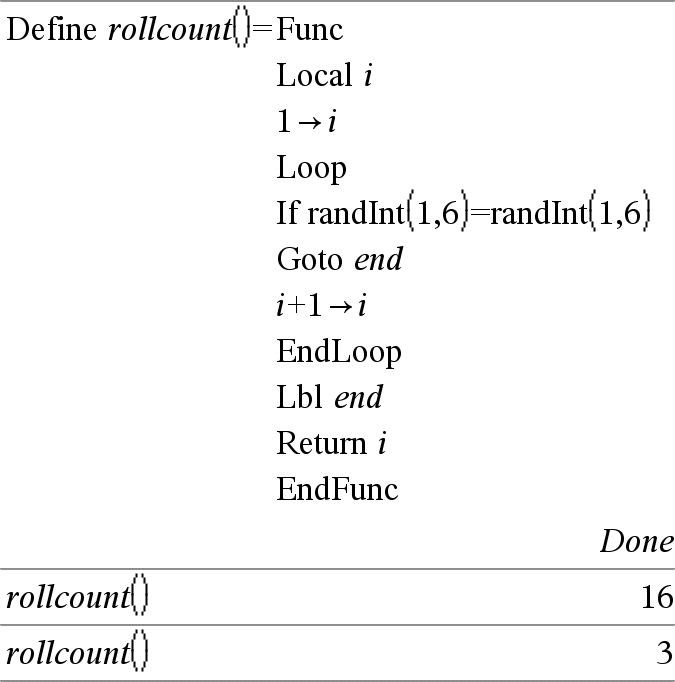
Local Var1[, Var2] [, Var3] ... Betecknar specificerade vars som lokala variabler. Dessa variabler existerar endast under utvärderingen av ett uttryck och tas bort när exekveringen av uttrycket är klar. Obs: Lokala variabler sparar minne eftersom de endast existerar tillfälligt. De stör heller inga befintliga globala variabelvärden. Lokala variabler måste användas för For-slingor och för att temporärt spara värden i en flerradig funktion eftersom modifieringar av globala värden inte är tillåtna i en funktion. Obs för att mata in exemplet: Se avsnittet Räknare i produkthandboken för instruktioner om hur du anger multiline-program och funktionsdefinitioner. |
|
|
Katalog > |
|
|
Låser den specificerade variabeln eller variabelgruppen. Låsta variabler kan inte modifieras eller tas bort. Du kan inte låsa eller låsa upp systemvariabeln Ans och du kan inte låsa systemvariabelgrupperna stat. och tvm. Obs: Kommandot Lås (Lock) rensar Ångra/Upprepa-historiken när det används på olåsta variabler. |
|

|
/s tangenter |
|
|
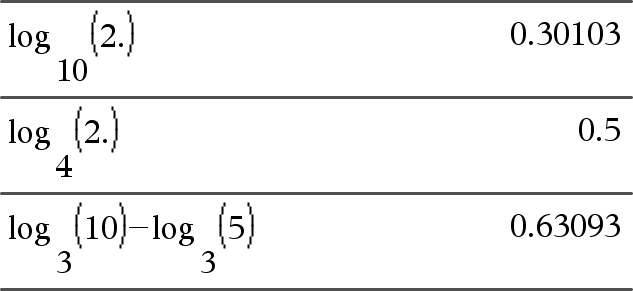
log(List1[,Value2])Þlista
Ger bas-Value2-logaritmen för det första argumentet. Obs: Se även Log template, här. Ger, för en lista, bas-Value2-logaritmen för elementen. Om det andra argumentet utelämnas används 10 som bas. |
Om det komplexa formatläget är Real:
Om det komplexa formatläget är Rectangular:
|
|
Ger matrisen med bas-Value-logaritm för squareMatrix1. Detta är inte detsamma som att beräkna bas-Value-logaritmen för varje element. Se cos() för information om beräkningsmetoden. squareMatrix1 måste vara möjlig att diagonalisera. Resultatet visas alltid i flyttalsform. Om basargumentet utelämnas används 10 som bas. |
I vinkelläget Radianer och i Rektangulärt komplext format:
För att se hela resultatet, tryck på 5 och använd sedan 7 och 8 för att flytta markören. |



|
Katalog > |
|
|
Logistic X, Y[, [Freq] [, Category, Include]] Utför den logistiska regressionsanalyseny = (c/(1+a·e-bx))på listorna X och Y med frekvensen Freq. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Alla listor utom Include måste ha samma dimensioner. X och Y är listor på oberoende och beroende variabler. Freq är en frivillig lista på frekvensvärden. Varje element i Freq specificerar frekvensen för varje motsvarande X- och Y-datapunkt. Det förinställda värdet är 1. Alla element måste vara heltal | 0. Category är en lista på Include är en lista på en eller flera av kategorikoderna. Endast de dataobjekt vars kategorikod är med på listan tas med i beräkningen. För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.RegEqn |
Regressionsekvation: c/(1+a·e-bx) |
|
stat.a, stat.b, stat.c |
Regressionskoefficienter |
|
stat.Resid |
Residualer från regressionen |
|
stat.XReg |
Lista på datapunkter i den modifierade X List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.YReg |
Lista på datapunkter i den modifierade Y List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.FreqReg |
Lista på frekvenser som motsvarar stat.XReg och stat.YReg |
|
Katalog > |
|
|
LogisticD X, Y [, [Iterations], [Freq] [, Category, Include] ] Utför den logistiska regressionsanalysen y = (c/(1+a·e-bx)+d) på listorna X och Y med frekvensen Freq, med ett specificerat antal Iterationer. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) Alla listor utom Include måste ha samma dimensioner. X och Y är listor på oberoende och beroende variabler. Iterations är ett valfritt värde som specificerar det maximala antalet gånger en lösning kommer att provas. Om denna utelämnas används 64. Normalt ger större värden bättre noggrannhet, men längre exekveringstider, och vice versa. Freq är en frivillig lista på frekvensvärden. Varje element i Freq specificerar frekvensen för varje motsvarande X- och Y-datapunkt. Det förinställda värdet är 1. Alla element måste vara heltal | 0. Category är en lista på Include är en lista på en eller flera av kategorikoderna. Endast de dataobjekt vars kategorikod är med på listan tas med i beräkningen. För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.RegEqn |
Regressionsekvation: c/(1+a·e-bx)+d) |
|
stat.a, stat.b, stat.c, stat.d |
Regressionskoefficienter |
|
stat.Resid |
Residualer från regressionen |
|
stat.XReg |
Lista på datapunkter i den modifierade X List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.YReg |
Lista på datapunkter i den modifierade Y List som används i regressionen baserat på begränsningar i Freq, Category List och Include Categories |
|
stat.FreqReg |
Lista på frekvenser som motsvarar stat.XReg och stat.YReg |
|
Katalog > |
|
|
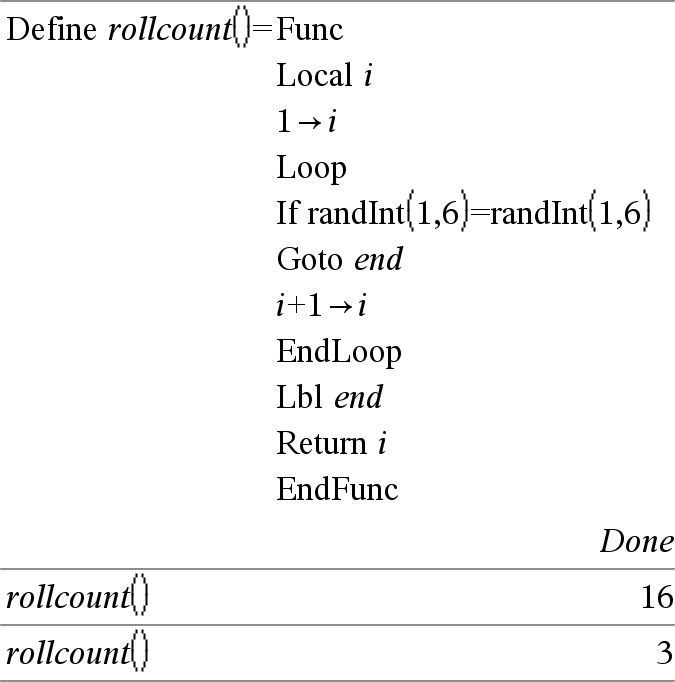
Loop Block EndLoop Exekverar påståendena i Block upprepade gånger. Observera att slingan upprepas i all oändlighet såvida inte en Goto- eller Exit-instruktion exekveras inom Block. Block är en serie av påståenden separerade med tecknet “:”. Obs för att mata in exemplet: Se avsnittet Räknare i produkthandboken för instruktioner om hur du anger multiline-program och funktionsdefinitioner. |
|
|
Katalog > |
|||||||
|
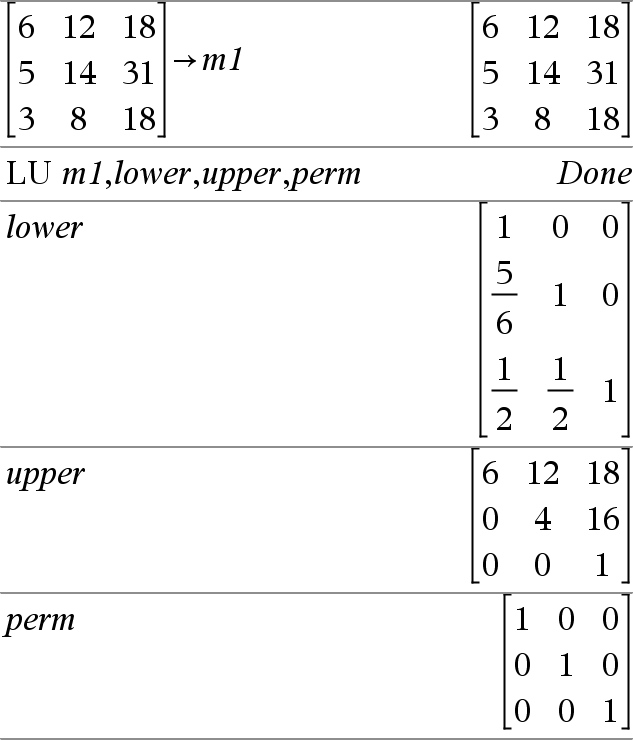
LU Matris, lMatris, uMatris, pMatris[,Tol] Beräknar uppdelningen Doolittle LU (undre-övre) av en reell eller komplex matris. Den undertriangulära matrisen lagras i lMatris, den övertriangulära matrisen lagras i uMatris och permutationsmatrisen (som beskriver radväxlingarna som har gjorts under beräkningen) lagras i pMatris. lMatris · uMatris = pMatris · matris Alternativt behandlas varje matriselement som noll om dess absolutvärde är mindre än Tol. Denna tolerans används endast om matrisen har inmatning med tal i flyttalsform och inte innehåller några symboliska variabler som inte har tilldelats ett värde. Annars ignoreras Tol.
Faktoriseringsalgoritmen LU använder partiell pivotering med radutbyten. |
|