|
Katalog > |
|||||||||||||
|
factor(rationalNumber) ger det rationella talet faktoriserat i primtal. För sammansatta tal ökar beräkningstiden exponentiellt med antalet siffror i den näst största faktorn. Som exempel kan faktorisering av ett 30-siffrigt heltal ta mer än en dag och faktorisering av ett 100-siffrigt tal kan ta mer än 100 år. För att stoppa en beräkning manuellt,
Om du endast vill bestämma om ett tal är ett primtal, använd isPrime() i stället. Detta går mycket fortare, särskilt om rationalNumber inte är ett primtal och om den näst största faktorn har mer än fem siffror. |
|


|
Katalog > |
|
|
FCdf(lowBound,upBound,dfNumer,dfDenom)Þnumber om lowBound och upBound är tal, lista om lowBound och upBound är listor FCdf(lowBound,upBound,dfNumer,dfDenom)Þtal om lowBound och upBound är tal, lista om lowBound och upBound är listor Beräknar sannolikheten för F -fördelningen mellan undre gräns och övre gräns för det specificerade dfNämn (frihetsgrader) och dfTälj. För P(X { övrGräns), ange undrGräns = 0. |
|
|
Katalog > |
|
|
Fill Value, matrixVarÞmatris Ersätter varje element i variabeln matrixVar med Value. matrixVar måste redan existera. |
|
|
Fill Value, listVarÞlista Ersätter varje element i variabeln listVar med Value. listVar måste redan existera. |
|


|
Katalog > |
|
|
FiveNumSummary X[,[Freq][,Category,Include]] Ger en förkortad version av envariabelstatistiken för listan X. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) X representerar en lista på aktuella data. Freq är en frivillig lista på frekvensvärden. Varje element i Freq specificerar frekvensen för varje motsvarande X-värde. Det förinställda värdet är 1. Alla element måste vara heltal | 0. Category är en lista på Include är en lista på en eller flera av kategorikoderna. Endast de dataobjekt vars kategorikod är med på listan tas med i beräkningen. Ett tomt element i någon av listorna X, Freq eller Category resulterar i ett tomrum för motsvarande element i dessa listor. För mer information om tomma element, se här. |
|
|
Resultatvariabel |
Beskrivning |
|
stat.MinX |
Minsta x-värde |
|
stat.Q1X |
Undre kvartil för x |
|
stat.MedianX |
Median för x |
|
stat.Q3X |
Övre kvartil för x |
|
stat.MaxX |
Största x-värde |
|
Katalog > |
|
|
floor(Value1)Þheltal Ger det största heltal som är { argumentet. Denna funktion är identisk med int(). Argumentet kan vara ett reellt eller ett komplext tal. |
|
|
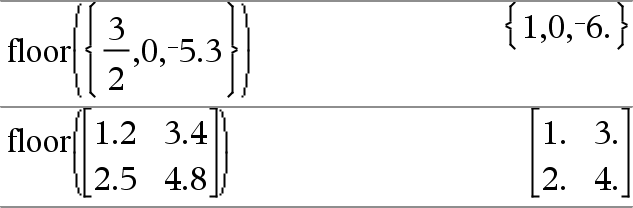
floor(List1)Þlista floor(Matrix1)Þmatris Ger en lista eller matris med golvvärden för varje element. Obs: Se även ceiling() och int(). |
|

|
Katalog > |
|
|
For Var, Low, High [, Step] Block EndFor Exekverar iterativt påståendena i Block för varje värde på Var, från Low till High, i steg enligt Step. Var får inte vara en systemvariabel. Step kan vara positivt eller negativt. Det förinställda värdet är 1. Block kan vara antingen ett enstaka påstående eller en serie av påståenden separerade med tecknet “:”. Obs för att mata in exemplet: Se avsnittet Räknare i produkthandboken för instruktioner om hur du anger multiline-program och funktionsdefinitioner. |
|

|
Katalog > |
|
|
format(Value[, formatString])Þsträng Ger Value som en teckensträng baserad på formatmallen. formatString är en sträng och måste ha formen: “F[n]”, “S[n]”, “E[n]”, “G[n][c]”, där [ ] indikerar frivilliga delar. F[n]: Fast format. n är antalet siffror som skall visas efter decimalpunkten. S[n]: Scientific format (Grundpotensform). n är antalet siffror som skall visas efter decimalpunkten. E[n]: Engineering format. n är antalet siffror efter den första signifikanta siffran. Exponenten justeras till en multipel av tre och decimalpunkten flyttas åt höger med noll, en eller två siffror. G[n][c]: Samma som fast format, men separerar också siffor till vänster om basen i grupper om tre. c specificerar det gruppseparerande tecknet och är förinställt på kommatecken. Om c är en punkt visas basen som ett kommatecken. [Rc]: Samtliga ovanstående specifikationssymboler kan förses med suffix med Rc-basflaggan, där c är ett enstaka tecken som specificerar vad som skall ersättas för baspunkten. |
|

|
Katalog > |
|
|
fPart(Expr1)Þuttryck fPart(List1)Þlista fPart(Matrix1)Þmatris Ger argumentets bråkdel. Ger, för en lista eller matris, elementens bråkdelar. Argumentet kan vara ett reellt eller ett komplext tal. |
|

|
Katalog > |
|
|
FPdf(XVal,dfNumer,dfDenom)Þtal om XVal är ett tal, lista om XVal är en lista Beräknar sannolikheten för F-fördelning vid XVal för specificerad dfNumer (frihetsgrader) och dfDenom. |
|
|
Katalog > |
|
|
freqTable4list(List1,freqIntegerList)Þlista Ger en lista som innehåller elementen från List1 expanderad enligt frekvenserna i freqIntegerList. Denna funktion kan användas för att skapa en frekvenstabell för applikationen Data & Statistik. List1 kan vara vilken giltig lista som helst. freqIntegerList måste ha samma dimensioner som List1 och får endast innehålla icke-negativa heltalselement. Varje element specificerar antalet gånger motsvarande List1-element kommer att upprepas i resultatlistan. Ett värde på noll utesluter motsvarande List1-element. Obs: Du kan infoga denna funktion med datorns tangentbord genom att skriva freqTable@>list(...). Tomma element ignoreras. För mer information om tomma element, se här. |
|

|
Katalog > |
|
|
frequency(List1,binsList)Þlista Ger en lista med antalet element i List1. Talen baseras på områden (bins = staplar) som du definierar i binsList. Om binsList är {b(1), b(2), …, b(n)} är de specificerade områdena {?{b(1), b(1)<?{b(2),…,b(n-1)<?{b(n), b(n)>?}. Den resulterande listan är ett element längre än binsList. Varje element i resultatet motsvarar antalet element från List1 som är i området för denna stapel. Uttryckt enligt funktionen countIf() är resultatet { countIf(list, ?{b(1)), countIf(list, b(1)<?{b(2)), …, countIf(list, b(n-1)<?{b(n)), countIf(list, b(n)>?)}. Element i List1 som inte kan “placeras i en stapel” ignoreras. Även tomma element ignoreras. För mer information om tomma element, se här. I applikationen Listor och kalkylblad kan du använda ett område av celler i stället för båda argumenten. Obs: Se även countIf(), här. |
Förklaring av resultat: 2 element från Datalist är {2.5 4 element från Datalist är >2.5 och {4.5 3 element från Datalist är >4.5 Elementet “hello” är en sträng och kan inte placeras i någon av de definierade staplarna. |

|
Katalog > |
|
|
FTest_2Samp List1,List2[,Freq1[,Freq2[,Hypoth]]] FTest_2Samp List1,List2[,Freq1[,Freq2[,Hypoth]]] (Indatalista) FTest_2Samp sx1,n1,sx2,n2[,Hypoth] FTest_2Samp sx1,n1,sx2,n2[,Hypoth] (Summary stats indata) Utför ett 2-sampel F test. En sammanfattning av resultaten visas i variabeln stat.results. (Se här.) eller Ha: s1 > s2, sätt Hypoth>0 För Ha: s1 ƒ s2 (förinställning), sätt Hypoth =0 För Ha: s1 < s2, sätt Hypoth<0 För information om effekten av tomma element i en lista, se “Tomma element” (här). |
|
|
Resultatvariabel |
Beskrivning |
|
stat.F |
Beräknad Û-statistik för datasekvensen |
|
stat.PVal |
Lägsta signifikansnivå vid vilken nollhypotesen kan förkastas |
|
stat.dfNumer |
täljare, frihetsgrader = n1-1 |
|
stat.dfDenom |
nämnare, frihetsgrader = n2-1 |
|
stat.sx1, stat.sx2 |
Standardavvikelser hos urvalet i datasekvenserna i List 1 och List 2 |
|
stat.x1_bar stat.x2_bar |
Medelvärden hos urvalet i datasekvenserna i List 1 och List 2 |
|
stat.n1, stat.n2 |
Storlek på urvalen |
|
Katalog > |
|
|
Func Block EndFunc Mall för att skapa en användardefinierad funktion. Block kan vara ett enstaka påstående, en serie av påståenden separerade med tecknet “:” eller en serie av påståenden på separata rader. Funktionen kan använda instruktionen Return för att ge ett specifikt resultat. Obs för att mata in exemplet: Se avsnittet Räknare i produkthandboken för instruktioner om hur du anger multiline-program och funktionsdefinitioner. |
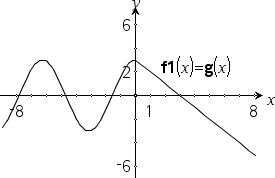
Definiera en stegvis funktion:
Resultat från plottning av g(x)
|