

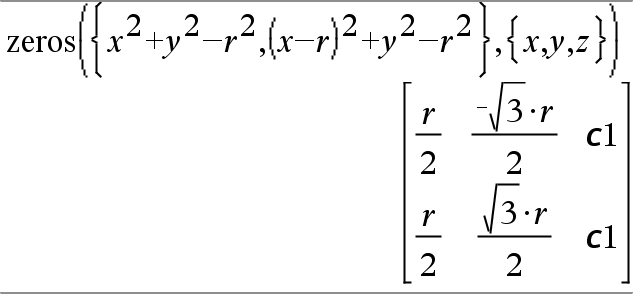
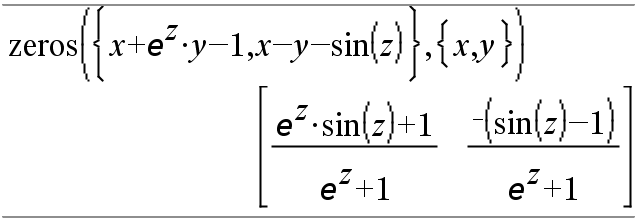
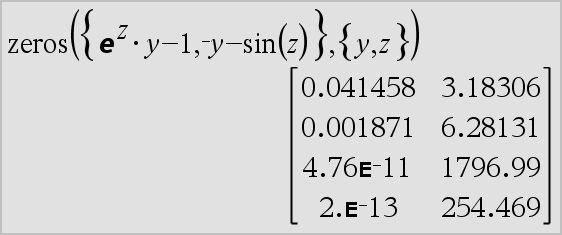
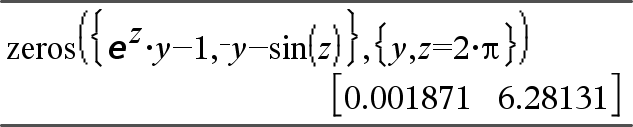
|
Catálogo > |
|
|
zInterval s,Lista[,Frec[,nivelC]] (Entrada de lista de datos) zInterval s,v,n [,nivelC] (Entrada de estadísticas de resumen) Resuelve un intervalo de confianza Z . Un resumen de resultados se almacena en la variable stat.results (aquí). Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.CBajo, stat.CAlto |
Intervalo de confianza para una media de población desconocida |
|
stat.x |
Media muestra de la secuencia de datos de la distribución aleatoria normal |
|
stat.ME |
Margen de error |
|
stat.ex |
Desviación estándar muestra |
|
stat.n |
Longitud de la secuencia de datos con media muestra |
|
stat.s |
Desviación estándar de población conocida para la secuencia de datos Lista |
|
Catálogo > |
|
|
zInterval_1Prop x,n [,nivelC] Resuelve un intervalo de confianza Z de una proporción. Un resumen de resultados se almacena en la variable stat.results (aquí). x es un entero no negativo. Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.CBajo, stat.CAlto |
Intervalo de confianza que contiene la probabilidad de distribución del nivel de confianza |
|
stat.Ç |
La proporción de éxitos calculada |
|
stat.ME |
Margen de error |
|
stat.n |
Número de muestras en la secuencia de datos |
|
Catálogo > |
|
|
zInterval_2Prop x1,n1,x2,n2[,nivelC] Resuelve un intervalo de confianza Z de dos proporciones. Un resumen de resultados se almacena en la variable stat.results (aquí). x1 y x2 son enteros no negativos. Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.CBajo, stat.CAlto |
Intervalo de confianza que contiene la probabilidad de distribución del nivel de confianza |
|
stat.ÇDif |
La diferencia entre proporciones calculada |
|
stat.ME |
Margen de error |
|
stat.Ç1 |
Estimación de proporción de primera muestra |
|
stat.Ç2 |
Estimación de proporción de segunda muestra |
|
stat.n1 |
Tamaño de la muestra en una secuencia de datos |
|
stat.n2 |
Tamaño de la muestra en la secuencia de datos de dos |
|
Catálogo > |
|
|
zInterval_2Samp s1,s2 ,Lista1,Lista2[,Frec1[,Frec2,[nivelC]]] (Entrada de lista de datos) zInterval_2Samp s1,s2,v1,n1,v2,n2[,nivelC] (Entrada de estadísticas de resumen) Resuelve un intervalo de confianza Z de dos muestras. Un resumen de resultados se almacena en la variable stat.results (aquí). Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.CBajo, stat.CAlto |
Intervalo de confianza que contiene la probabilidad de distribución del nivel de confianza |
|
stat.x1-x2 |
Medias muestra de las secuencias de datos de la distribución aleatoria normal |
|
stat.ME |
Margen de error |
|
stat.x1, stat.x2 |
Medias muestra de las secuencias de datos de la distribución aleatoria normal |
|
stat.sx1, stat.sx2 |
Desviaciones estándar muestras para Lista 1 y Lista 2 |
|
stat.n1, stat.n2 |
Número de muestras en las secuencias de datos |
|
stat.r1, stat.r2 |
Desviaciones estándar de población conocidas para Lista 1 y Lista 2 |
|
Catálogo > |
|
|
zTest m0,s,Lista,[Frec[,Hipot]] (Entrada de lista de datos) zTest m0,s,v,n[,Hipot] (Entrada de estadísticas de resumen) Realiza una prueba z con frecuencia listaFrec. Un resumen de resultados se almacena en la variable stat.results (aquí). Pruebe H0: m = m0, contra uno de los siguientes: Para Ha: m < m0, configure Hipot<0 Para Ha: m ƒ m0 (predeterminado), configure Hipot=0 Para Ha: m > m0, configure Hipot>0 Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.z |
(x N m0) / (s / sqrt(n)) |
|
stat.Valor P |
Probabilidad más baja a la cual la hipótesis nula se puede rechazar |
|
stat.x |
Media de muestra de la secuencia de datos en Lista |
|
stat.ex |
Desviación estándar de muestras de la secuencia de datos. Sólo se entrega para la entrada de Datos . |
|
stat.n |
Tamaño de la muestra |
|
Catálogo > |
|
|
zTest_1Prop p0,x,n[,Hipot] Resuelve una prueba Z de una proporción. Un resumen de resultados se almacena en la variable stat.results (aquí). x es un entero no negativo. Pruebe H0: p = p0 contra uno de los siguientes: Para Ha: p > p0, configure Hipot>0 Para Ha: p ƒ p0 (predeterminado), configure Hipot=0 Para Ha: p < p0, configure Hipot<0 Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.p0 |
Proporción poblacional de la hipótesis |
|
stat.z |
Valor normal estándar calculado para la proporción |
|
stat.ValP |
Nivel más bajo de significancia en el cual la hipótesis nula se puede rechazar |
|
stat.Ç |
Proporción muestral estimada |
|
stat.n |
Tamaño de la muestra |
|
Catálogo > |
|
|
zTest_2Prop x1,n1,x2,n2[,Hipot] Resuelve una prueba Z de dos proporciones. Un resumen de resultados se almacena en la variable stat.results (aquí). x1 y x2 son enteros no negativos. Pruebe H0: p1 = p2, contra uno de los siguientes: Para Ha: p1 > p2, configure Hipot>0 Para Ha: p1 ƒ p2 (predeterminado), configure Hipot=0 Para Ha: p < p0, configure Hipot<0 Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.z |
Valor normal estándar calculado para la diferencia de las proporciones |
|
stat.ValP |
Nivel más bajo de significancia en el cual la hipótesis nula se puede rechazar |
|
stat.Ç1 |
Estimación de proporción de primera muestra |
|
stat.Ç2 |
Estimación de proporción de segunda muestra |
|
stat.Ç |
Estimación de proporción de muestras agrupadas |
|
stat.n1, stat.n2 |
Número de muestras tomadas en las pruebas 1 y 2 |
|
Catálogo > |
|
|
zTest_2Samp s1,s2 ,Lista1,Lista2[,Frec1[,Frec2[,Hipot]]] (Entrada de lista de datos) zTest_2Samp s1,s2,v1,n1,v2,n2[,Hipot] (Entrada de estadísticas de resumen) Resuelve una prueba Z de dos muestras. Un resumen de resultados se almacena en la variable stat.results (aquí). Pruebe H0: m1 = m2, contra uno de los siguientes: Para Ha: m1 < m2, configure Hipot<0 Para Ha: m1 ƒ m2 (predeterminado), configure Hipot=0 Para Ha: m1 > m2, Hipot>0 Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.z |
Valor normal estándar computado para la diferencia de las medias |
|
stat.ValP |
Nivel más bajo de significancia en el cual la hipótesis nula se puede rechazar |
|
stat.x1, stat.x2 |
Muestras de las medias de las secuencias de datos en Lista1 y Lista2 |
|
stat.sx1, stat.sx2 |
Desviaciones estándar de muestras de las secuencias de datos en Lista1 y Lista2 |
|
stat.n1, stat.n2 |
Tamaño de las muestras |