|
Catálogo > |
|
|
Lbl NomeDefinição Define uma definição com o nome NomeDefinição numa função. Pode utilizar uma instrução Goto NomeDefinição para transferir o controlo para a instrução imediatamente a seguir à definição. NomeDefinição tem de cumprir os mesmos requisitos de nomeação do nome de uma variável. Obs para introdução do exemplo: Para obter instruções sobre como introduzir programas com várias linhas e definições de funções, consulte a secção Calculadora do manual do utilizador do produto. |
|

|
Catálogo > |
|
|
lcm(Número1, Número2) Þexpressão lcm(Lista1, Lista2) Þlista lcm(Matriz1, Matriz2) Þmatriz Devolve o mínimo múltiplo comum dos dois argumentos. O lcm de duas fracções é o lcm dos numeradores divididos pelo gcd dos denominadores. O lcm dos números de ponto flutuante fraccionários é o produto. Para duas listas ou matrizes, devolve os mínimos múltiplos comuns dos elementos correspondentes. |
|
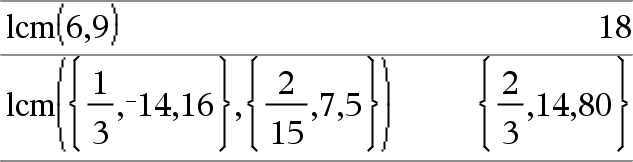
|
Catálogo > |
|
|
left(CadeiaDeOrigem [, Num ]) Þcadeia Devolve os caracteres Num mais à esquerda contidos na cadeia de caracteres CadeiaDeOrigem. Se omitir Num, devolve todos os caracteres de CadeiaDeOrigem. |
|
|
left(Lista1 [, Num ]) Þlista Devolve os elementos Num mais à esquerda em Lista1. Se omitir Num, devolve todos os elementos de Lista1. |
|
|
left(Comparação) Þexpressão Devolve o lado esquerdo de uma equação ou desigualdade. |
|



|
Catálogo > |
|
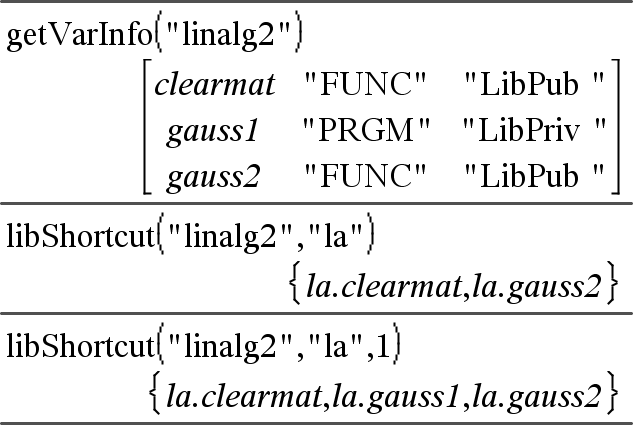
|
libShortcut(CadeiaDoNomeDaBiblioteca, CadeiaDoNomeDoAtalho [, MarcadorDeBibPriv])Þlista de variáveis Cria um grupo de variáveis no problema actual que contém referências a todos os objectos no documento da biblioteca especificado CadeiaDoNomeDaBiblioteca. Adiciona também os membros do grupo ao menu Variáveis. Pode referir-se a cada objecto com a CadeiaDoNomeDoAtalho. Definir MarcadorDeBibliotecaPrivada=0 para excluir objectos da biblioteca privada (predefinição) Definir MarcadorDeBibliotecaPrivada=1 para incluir objectos da biblioteca privada Para copiar um grupo de variáveis, consulte CopyVar, aqui. Para eliminar um grupo de variáveis, consulte DelVar, aqui. |
Este exemplo assume um documento de biblioteca actualizado e guardado adequadamente denominado linalg2 que contém objectos definidos como clearmat, gauss1 e gauss2.
|
|
Catálogo > |
|
|
limit(Expr1, Var, Ponto [, Direcção ]) Þexpressão limit(Lista1, Var, Ponto [, Direcção ]) Þlista limit(Matriz1, Var, Ponto [, Direcção ]) Þmatriz Devolve o limite requerido. Nota: Consulte também Modelo do limite, aqui. Direcção: negativa=da esquerda, positiva=da direita, caso contrário=ambos. (Se omitida, a Direcção predefine-se para ambos.) |
|
|
Os limites no ˆ positivo e no ˆ negativo são sempre convertidos para limites de um lado do lado finito. |
|
|
Dependendo das circunstâncias, limit() devolve-se ou undef quando não consegue determinar um limite único. Isto não significa necessariamente que não existe um limite único. undef significa que o resultado é um número desconhecido com a magnitude finita ou infinita, ou é um conjunto completo desses números. |
|
|
limit() utiliza método como a regra L’Hopital’s, logo existem limites únicos que não consegue determinar. Se a Expr1 contiver variáveis indefinidas diferentes de Var, pode ter de as limitar para obter um resultado mais conciso. Os limites podem ser muito sensíveis ao erro de arredondamento. Quando possível, evite a definição Aproximado do modo Auto ou Aproximado e os números aproximados quando calcular os limites. Caso contrário, os limites que devem ser zero ou ter magnitude infinita provavelmente não terão, e os limites que devem ter magnitude diferente de zero finita podem não ter. |
|
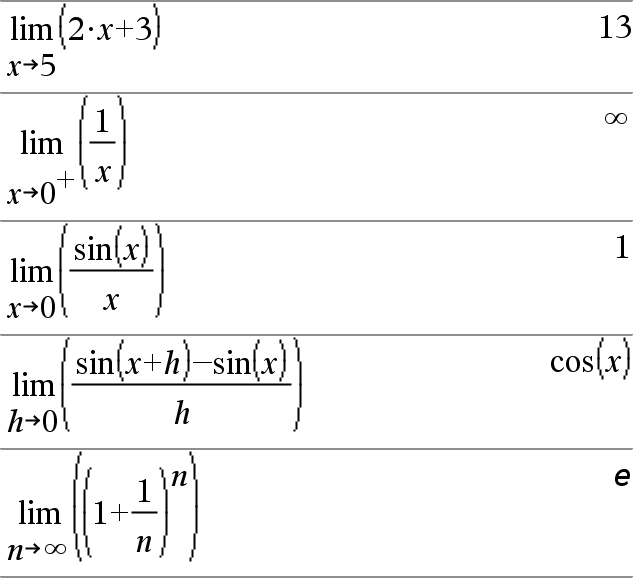
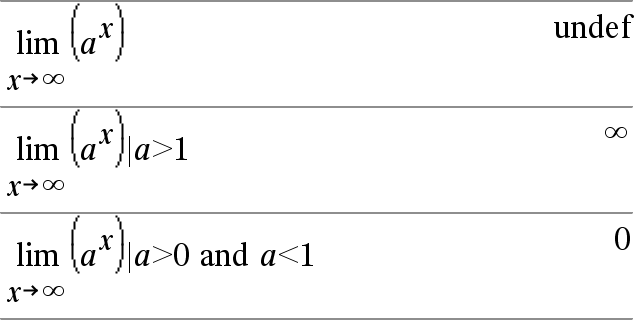
|
Catálogo > |
|
|
LinRegBx X,Y[,[Freq][,Categoria,Incluir]] Calcula a regressão lineary = a+b·xa partir das listas X e Y com a frequência Freq. Um resumo dos resultados é guardado na variável stat.results (aqui). Todas as listas têm de ter a mesma dimensão, excepto para Incluir. X e Y são listas de variáveis independentes e dependentes. Freq é uma lista opcional de valores de frequência. Cada elemento em Freq especifica a frequência de ocorrência para cada ponto de dados X e Y correspondente. O valor predefinido é 1. Todos os elementos têm de ser números inteiros 0. Categoria é uma lista de códigos de categorias para os dados X e Y correspondentes. Incluir é uma lista de um ou mais códigos de categorias. Apenas os itens de dados cujo código de categoria está incluído nesta lista são considerados no cálculo. Para mais informações sobre o efeito dos elementos vazios numa lista, consulte “Elementos (nulos) vazios” (aqui). |
|
|
Variável de saída |
Descrição |
|
stat.RegEqn |
Equação de regressão: a+b·x |
|
stat.a, stat.b |
Parâmetros de regressão |
|
stat.r2 |
Coeficiente de determinação |
|
stat.r |
Coeficiente de correlação |
|
stat.Resid |
Resíduos da regressão |
|
stat.XReg |
Lista de dados na Lista X modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.YReg |
Lista de dados na Lista Y modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.FreqReg |
Lista de frequências correspondentes a stat.XReg e stat.YReg |
s
|
Catálogo > |
|
|
LinRegMx X,Y[,[Freq][,Categoria,Incluir]] Calcula a regressão linear y = m·x+b a partir das listas X e Y com a frequência Freq. Um resumo dos resultados é guardado na variável stat.results (aqui). Todas as listas têm de ter a mesma dimensão, excepto para Incluir. X e Y são listas de variáveis independentes e dependentes. Freq é uma lista opcional de valores de frequência. Cada elemento em Freq especifica a frequência de ocorrência para cada ponto de dados X e Y correspondente. O valor predefinido é 1. Todos os elementos têm de ser números inteiros 0. Categoria é uma lista de códigos de categorias para os dados X e Y correspondentes. Incluir é uma lista de um ou mais códigos de categorias. Apenas os itens de dados cujo código de categoria está incluído nesta lista são considerados no cálculo. Para mais informações sobre o efeito dos elementos vazios numa lista, consulte “Elementos (nulos) vazios” (aqui). |
|
|
Variável de saída |
Descrição |
|
stat.RegEqn |
Equação de regressão: m·x+b |
|
stat.m, stat.b |
Parâmetros de regressão |
|
stat.r2 |
Coeficiente de determinação |
|
stat.r |
Coeficiente de correlação |
|
stat.Resid |
Resíduos da regressão |
|
stat.XReg |
Lista de dados na Lista X modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.YReg |
Lista de dados na Lista Y modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.FreqReg |
Lista de frequências correspondentes a stat.XReg e stat.YReg |
|
Catálogo > |
|
|
LinRegtIntervals X,Y[,F[,0[,NívC]]] Para declive. Calcula o intervalo de confiança de nível C do declive. LinRegtIntervals X,Y[,F[,1,ValX[,NívC]]] Para resposta. Calcula um valor y previsto, um intervalo de previsão de nível C para uma observação, e um intervalo de confiança de nível C para a resposta média. Um resumo dos resultados é guardado na variável stat.results (aqui). Todas as listas têm de ter a mesma dimensão. X e Y são listas de variáveis independentes e dependentes. F é uma lista opcional de valores de frequência. Cada elemento em F especifica a frequência de ocorrência para cada ponto de dados X e Y correspondente. O valor predefinido é 1. Todos os elementos têm de ser números inteiros | 0. Para mais informações sobre o efeito dos elementos vazios numa lista, consulte “Elementos (nulos) vazios” (aqui). |
|
|
Variável de saída |
Descrição |
|
stat.RegEqn |
Equação de regressão: a+b·x |
|
stat.a, stat.b |
Parâmetros de regressão |
|
stat.df |
Graus de liberdade |
|
stat.r2 |
Coeficiente de determinação |
|
stat.r |
Coeficiente de correlação |
|
stat.Resid |
Resíduos da regressão |
Apenas para o tipo de declive
|
Variável de saída |
Descrição |
|
[stat.CLower, stat.CUpper] |
Intervalo de confiança para o declive |
|
stat.ME |
Margem de erro do intervalo de confiança |
|
stat.SESlope |
Erro padrão do declive |
|
stat.s |
Erro padrão sobre a linha |
Apenas para o tipo de resposta
|
Variável de saída |
Descrição |
|
[stat.CLower, stat.CUpper] |
Intervalo de confiança para a resposta média |
|
stat.ME |
Margem de erro do intervalo de confiança |
|
stat.SE |
Erro padrão da resposta média |
|
[stat.LowerPred, stat.UpperPred] |
Intervalo de previsão para uma observação |
|
stat.MEPred |
Margem de erro do intervalo de previsão |
|
stat.SEPred |
Erro padrão para previsão |
|
stat.y |
a + b·XVal |
|
Catálogo > |
|
|
LinRegtTest X,Y[,Freq[,Hipótese]] Calcula uma regressão linear a partir das listas X e Y e um teste t no valor do declive b e o coeficiente de correlação r para a equação y=a+bx. Testa a hipótese nula H0:b=0 (equivalentemente, r=0) em relação a uma das três hipóteses alternativas. Todas as listas têm de ter a mesma dimensão. X e Y são listas de variáveis independentes e dependentes. Freq é uma lista opcional de valores de frequência. Cada elemento em Freq especifica a frequência de ocorrência para cada ponto de dados X e Y correspondente. O valor predefinido é 1. Todos os elementos têm de ser números inteiros 0. Hipótese é um valor opcional que especifica uma de três hipóteses alternativas em relação à qual a hipótese nula (H0:b=r=0) será testada. Para Ha: bƒ0 e rƒ0 (predefinição), defina Hipótese=0 Para Ha: b<0 e r<0, defina Hipótese<0 Para Ha: b>0 e r>0, defina Hipótese>0 Um resumo dos resultados é guardado na variável stat.results (aqui). Para mais informações sobre o efeito dos elementos vazios numa lista, consulte “Elementos (nulos) vazios” (aqui). |
|
|
Variável de saída |
Descrição |
|
stat.RegEqn |
Equação de regressão: a + b·x |
|
stat.t |
t-Estatística para teste de importância |
|
stat.PVal |
Menor nível de significância para o qual a hipótese nula pode ser rejeitada |
|
stat.df |
Graus de liberdade |
|
stat.a, stat.b |
Parâmetros de regressão |
|
stat.s |
Erro padrão sobre a linha |
|
stat.SESlope |
Erro padrão do declive |
|
stat.r2 |
Coeficiente de determinação |
|
stat.r |
Coeficiente de correlação |
|
stat.Resid |
Resíduos da regressão |
|
Catálogo > |
|
|
Devolve uma lista de soluções para as variáveis Var1, Var2, ... O primeiro argumento tem de avaliar um sistema de equações do 1º grau ou uma equação individual do 1º grau. Caso contrário, ocorre um erro de argumento. Por exemplo, a avaliação de linSolve(x=1 |
|

|
Catálogo > |
|
|
@List(Lista1) Þlista Nota: Pode introduzir esta função através da escrita de deltaList(...) no teclado. Devolve uma lista com as diferenças entre os elementos consecutivos em Lista1. Cada elemento de Lista1 é subtraído do elemento seguinte de Lista1. A lista resultante é sempre um elemento mais pequeno que a Lista1 original. |
|
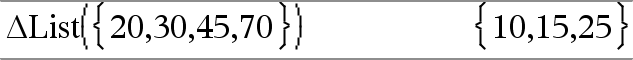
|
Catálogo > |
|
|
list4mat(Lista [, elementosPorLinha ]) Þmatriz Devolve uma matriz preenchida linha por linha com os elementos da Lista. elementosPorLinha, se incluído, especifica o número de elementos por linha. A predefinição é o número de elementos em Lista (uma linha). Se a Lista não preencher a matriz resultante, são adicionados zeros. Nota: Pode introduzir esta função através da escrita de list@>mat(...) no teclado do computador. |
|
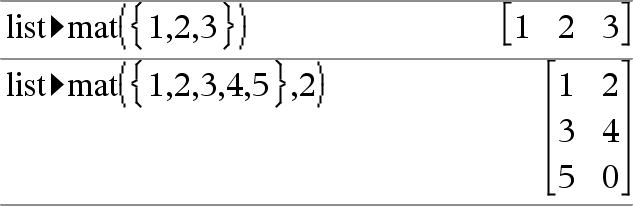
|
Catálogo > |
|
|
Expr 4ln Þexpressão Faz com que a entrada Expr seja convertida para uma expressão apenas com logaritmos naturais (ln). Nota: Pode introduzir este operador através da escrita de @>ln no teclado do computador. |
|

|
Teclas /u |
|
|
ln(Expr1) Þexpressão ln(Lista1) Þlista Devolve o logaritmo natural do argumento. Para uma lista, devolve os logaritmos naturais dos elementos. |
Se o modo do formato complexo for Real:
Se o modo do formato complexo for Rectangular:
|
|
ln(MatrizQuadrada1) ÞMatrizQuadrada Devolve o logaritmo natural da matriz de MatrizQuadrada1. Isto não é o mesmo que calcular o logaritmo natural de cada elemento. Para mais informações sobre o método de cálculo, consulte cos() em. MatrizQuadrada1 tem de ser diagnolizável. O resultado contém sempre os números de ponto flutuante. |
No modo de ângulo Radianos e Formato complexo rectangular:
Para ver o resultado completo, prima 5 e, de seguida, utilize 7 e 8 para mover o cursor. |


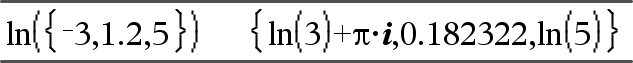

|
Catálogo > |
|
|
LnReg X, Y[, [Freq] [, Categoria, Incluir]] Calcula a regressão logarítmica y = a+b·ln(x) a partir das listas X e Y com a frequência Freq. Um resumo dos resultados é guardado na variável stat.results (aqui). Todas as listas têm de ter a mesma dimensão, excepto para Incluir. X e Y são listas de variáveis independentes e dependentes. Freq é uma lista opcional de valores de frequência. Cada elemento em Freq especifica a frequência de ocorrência para cada ponto de dados X e Y correspondente. O valor predefinido é 1. Todos os elementos têm de ser números inteiros 0. Categoria é uma lista de códigos de categorias para os dados X e Y correspondentes. Incluir é uma lista de um ou mais códigos de categorias. Apenas os itens de dados cujo código de categoria está incluído nesta lista são considerados no cálculo. Para mais informações sobre o efeito dos elementos vazios numa lista, consulte “Elementos (nulos) vazios” (aqui). |
|
|
Variável de saída |
Descrição |
|
stat.RegEqn |
Equação de regressão: a+b·ln(x) |
|
stat.a, stat.b |
Parâmetros de regressão |
|
stat.r2 |
Coeficiente de determinação linear para dados transformados |
|
stat.r |
Coeficiente de correlação para dados transformados (ln(x), y) |
|
stat.Resid |
Resíduos associados ao modelo logarítmico |
|
stat.ResidTrans |
Resíduos associados ao ajuste linear dos dados transformados |
|
stat.XReg |
Lista de dados na Lista X modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.YReg |
Lista de dados na Lista Y modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.FreqReg |
Lista de frequências correspondentes a stat.XReg e stat.YReg |
|
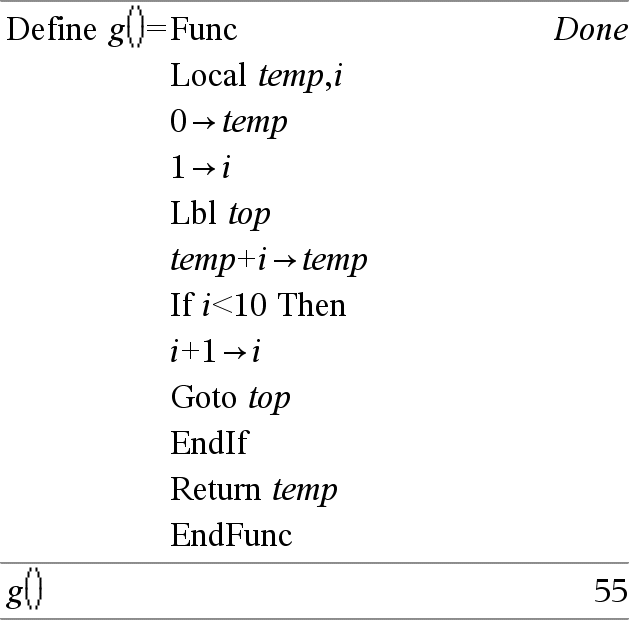
Catálogo > |
|
|
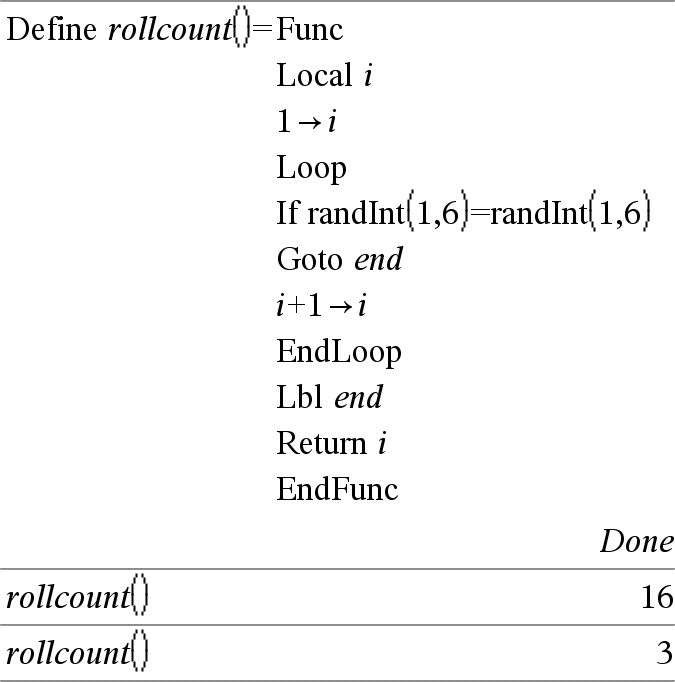
Local Var1 [, Var2 ] [, Var3 ] ... Declara as vars especificadas como variáveis locais. Essas variáveis só existem durante a avaliação de uma função e são eliminadas quando a função terminar a execução. Nota: As variáveis locais poupam memória porque só existem temporariamente. Também não perturbam nenhum valor da variável global existente. As variáveis locais têm de ser utilizadas para ciclos For e guardar temporariamente os valores numa função multilinhas visto que as modificações nas variáveis globais não são permitidas numa função. Obs para introdução do exemplo: Para obter instruções sobre como introduzir programas com várias linhas e definições de funções, consulte a secção Calculadora do manual do utilizador do produto. |
|
|
Catálogo > |
|
|
Bloqueia as variáveis ou o grupo de variáveis especificadas. Não pode eliminar ou modificar as variáveis bloqueadas. Não pode bloquear ou desbloquear a variável do sistema Ans, e não pode bloquear os grupos de variáveis do sistema stat. ou tvm. Nota: O comando Bloquear (Lock) apaga o histórico de Anular/Repetir quando aplicado a variáveis desbloqueadas. |
|

|
Teclas /s |
|
|
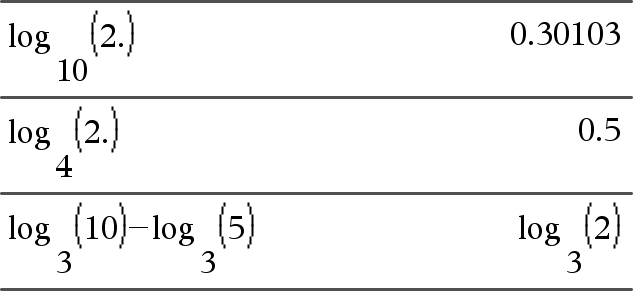
log (Lista1 [, Expr2 ]) Þlista
Devolve o logaritmo -Expr2 base do primeiro argumento. Nota: Consulte também Modelo do logaritmo, aqui. Para uma lista, devolve o logaritmo -Expr2 base dos elementos. Se omitir o segundo argumento, 10 é utilizado como a base. |
Se o modo do formato complexo for Real:
Se o modo do formato complexo for Rectangular:
|
|
Devolve o logaritmo Expr base da matriz de MatrizQuadrada1. Isto não é mesmo que calcular o logaritmo Expr base de cada elemento. Para mais informações sobre o método de cálculo, consulte cos(). MatrizQuadrada1 tem de ser diagnolizável. O resultado contém sempre os números de ponto flutuante. Se omitir o argumento base, 10 é utilizado como a base. |
No modo de ângulo Radianos e Formato complexo rectangular:
Para ver o resultado completo, prima 5 e, de seguida, utilize 7 e 8 para mover o cursor. |



|
Catálogo > |
|
|
Expr 4logbase(Expr1) Þexpressão Faz com que a entrada Expressão seja simplificada para uma expressão com a base Expr1. Nota: Pode introduzir este operador através da escrita de @>logbase(...) no teclado do computador. |
|

|
Catálogo > |
|
|
Logistic X, Y[, [Freq] [, Categoria, Incluir]] Calcula a regressão logísticay = (c/(1+a·e-bx))a partir das listas X e Y com a frequência Freq. Um resumo dos resultados é guardado na variável stat.results (aqui). Todas as listas têm de ter a mesma dimensão, excepto para Incluir. X e Y são listas de variáveis independentes e dependentes. Freq é uma lista opcional de valores de frequência. Cada elemento em Freq especifica a frequência de ocorrência para cada ponto de dados X e Y correspondente. O valor predefinido é 1. Todos os elementos têm de ser números inteiros 0. Categoria é uma lista de códigos de categorias para os dados X e Y correspondentes. Incluir é uma lista de um ou mais códigos de categorias. Apenas os itens de dados cujo código de categoria está incluído nesta lista são considerados no cálculo. Para mais informações sobre o efeito dos elementos vazios numa lista, consulte “Elementos (nulos) vazios” (aqui). |
|
|
Variável de saída |
Descrição |
|
stat.RegEqn |
Equação de regressão: c/(1+a·e-bx) |
|
stat.a, stat.b, stat.c |
Parâmetros de regressão |
|
stat.Resid |
Resíduos da regressão |
|
stat.XReg |
Lista de dados na Lista X modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.YReg |
Lista de dados na Lista Y modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.FreqReg |
Lista de frequências correspondentes a stat.XReg e stat.YReg |
|
Catálogo > |
|
|
LogisticD X, Y [, [Repetições], [Freq] [, Categoria, Incluir] ] Calcula a regressão logística y = (c/(1+a·e-bx)+d) a partir das listas X e Y com a frequência Freq, utilizando um número especificado de repetições. Um resumo dos resultados é guardado na variável stat.results (aqui). Todas as listas têm de ter a mesma dimensão, excepto para Incluir. X e Y são listas de variáveis independentes e dependentes. Iterações é um valor opcional que especifica o número máximo de vezes que uma solução será tentada. Se for omitido, 64 é utilizado. Em geral, valores maiores resultam numa melhor precisão, mas maiores tempos de execução, e vice-versa. Freq é uma lista opcional de valores de frequência. Cada elemento em Freq especifica a frequência de ocorrência para cada ponto de dados X e Y correspondente. O valor predefinido é 1. Todos os elementos têm de ser números inteiros 0. Categoria é uma lista de códigos de categorias para os dados X e Y correspondentes. Incluir é uma lista de um ou mais códigos de categorias. Apenas os itens de dados cujo código de categoria está incluído nesta lista são considerados no cálculo. Para mais informações sobre o efeito dos elementos vazios numa lista, consulte “Elementos (nulos) vazios” (aqui). |
|
|
Variável de saída |
Descrição |
|
stat.RegEqn |
Equação de regressão: c/(1+a·e-bx)+d) |
|
stat.a, stat.b, stat.c, stat.d |
Parâmetros de regressão |
|
stat.Resid |
Resíduos da regressão |
|
stat.XReg |
Lista de dados na Lista X modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.YReg |
Lista de dados na Lista Y modificada utilizada na regressão com base nas restrições de Freq, Lista de categorias e Incluir categorias |
|
stat.FreqReg |
Lista de frequências correspondentes a stat.XReg e stat.YReg |
|
Catálogo > |
|
|
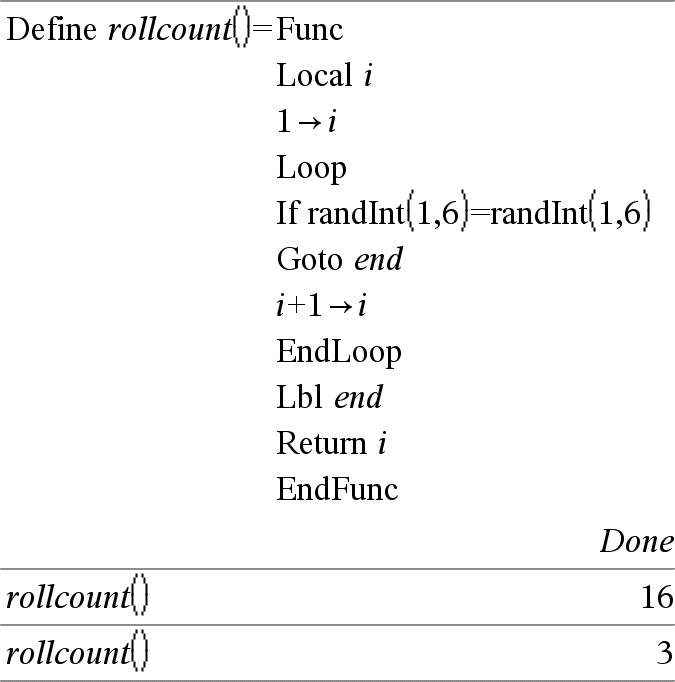
Ciclo Executa repetidamente as declarações em Bloco. Não se esqueça de que o ciclo será executado continuamente, excepto se executar a instrução Ir para ou Sair no Bloco. Bloco é uma sequência de declarações separadas pelo carácter “:”. Obs para introdução do exemplo: Para obter instruções sobre como introduzir programas com várias linhas e definições de funções, consulte a secção Calculadora do manual do utilizador do produto. |
|
|
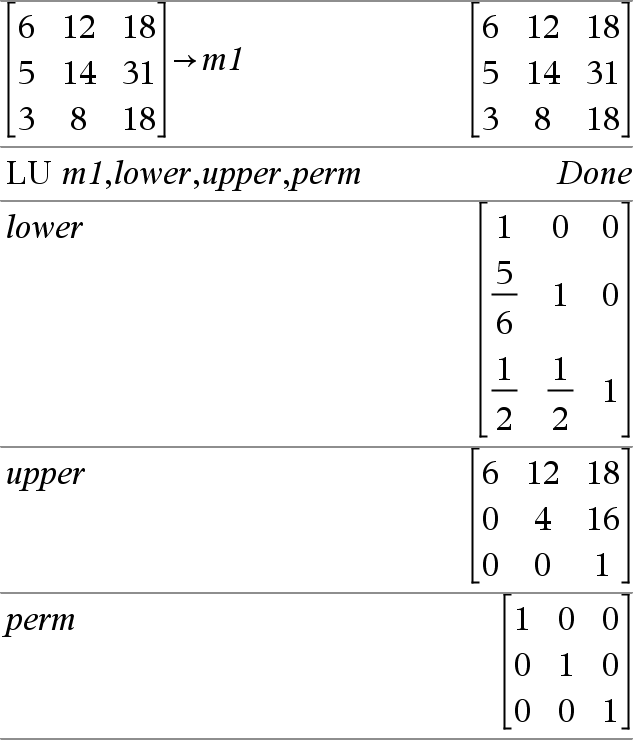
Catálogo > |
|||||||
|
LU Matriz, MatrizI, Matrizu, Matrizp[,Tol] Calcula a decomposição LU (inferior-superior) Doolittle LU de uma matriz complexa ou real. A matriz triangular inferior é guardada em MatrizI, a matriz triangular superior em Matrizu e a matriz de permutações (que descreve as trocas de linhas durante o cálculo) em Matrizp. MatrizI · Matrizu = Matrizp · matriz Opcionalmente, qualquer elemento da matriz é tratado como zero se o valor absoluto for inferior a Tol. Esta tolerância só é utilizada se a matriz tiver entradas de ponto flutuante e não contiver variáveis simbólicas sem um valor atribuído. Caso contrário, Tol é ignorado.
O algortimo de factorização LU utiliza a articulação parcial com as trocas de linhas. |
|