|
Catálogo > |
|
|
Lbl nombreEtiqueta Define una etiqueta con el nombre nombreEtiqueta dentro de una función. Usted puede usar una instrucción Goto nombreEtiqueta para transferir el control a la instrucción que sigue inmediatamente a la etiqueta. nombreEtiqueta debe cumplir con los mismos requisitos de nombrado que un nombre de variable. Nota para introducir el ejemplo: Para obtener instrucciones sobre cómo introducir las definiciones de programas y funciones en varias líneas, consulte la sección Calculadora de la guía del producto. |
|

|
Catálogo > |
|
|
lcm(Número1, Número2)Þexpresión lcm(Lista1, Lista2)Þlista lcm(Matriz1, Matriz2)Þmatriz Entrega el mínimo común múltiplo de los dos argumentos. El lcm de dos fracciones es el lcm de sus numeradores dividido entre el gcd de sus denominadores. El lcm de los números de punto flotante fraccional es su producto. Para dos listas o matrices, entrega los mínimos comunes múltiplos de los elementos correspondientes. |
|
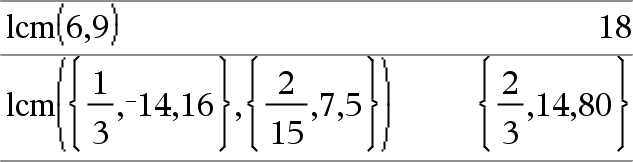
|
Catálogo > |
|
|
left(cadenaFuente[, Num])Þcadena Entrega los caracteres de Num del extremo izquierdo contenidos en una cadena de caracteres cadenaFuente. Si usted omite Num, entrega toda la cadenaFuente. |
|
|
left(Lista1[, Num])Þlista Entrega los elementos de Num del extremo izquierdo contenidos en Lista1. Si usted omite Num, entrega toda la Lista1. |
|
|
left(Comparación)Þexpresión Entrega el lado del extremo izquierdo de una ecuación o desigualdad. |


|
Catálogo > |
|
|
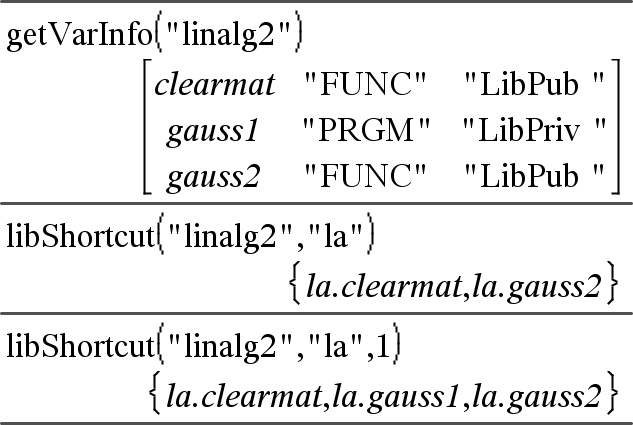
libShortcut(CadenaNombreLib, CadenaNombreAccesoDirecto [, BanderaLibPriv])Þlista de variables Crea un grupo de variables en el problema actual que contiene referencias para todos los objetos en el documento de librería especificado cadenaNombreLib. También agrega los miembros del grupo al menú de Variables. Entonces usted puede referirse a cada objeto al usar su CadenaNombreAccesoDirecto. Configure BanderaLibPriv=0 para excluir objetos de librería privada (predeterminado) Configure BanderaLibPriv=1 para incluir objetos de librería privada Para copiar un grupo de variables, vea CopyVar (aquí). Para borrar un grupo de variables, vea DelVar (aquí). |
Este ejemplo supone un documento de librería almacenado y actualizado en forma apropiada nombrado linalg2 que contiene objetos definidos como limpmat, gauss1y gauss2.
|
|
Catálogo > |
|
|
LinRegBx X,Y[,[Frec][,Categoría,Incluir]] Resuelve la regresión linealy = a+b·xen las listas X y Y con frecuencia Frec. Un resumen de resultados se almacena en la variable resultados.estad (aquí). Todas las listas deben tener una dimensión igual, excepto por Incluir. X y Y son listas de variables independientes y dependientes. Frec es una lista opcional de valores de frecuencia. Cada elemento en Frec especifica la frecuencia de la ocurrencia para cada punto de datos X y Y correspondientes. El valor predeterminado es 1. Todos los elementos deben ser enteros | 0. Categoría es una lista de códigos de categoría Incluir es una lista de uno o más códigos de categoría. Sólo aquellos elementos de datos cuyo código de categoría está incluido en esta lista están incluidos en el cálculo. Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.EcnReg |
Ecuación de regresión: a+b·x |
|
stat.a, stat.b |
Coeficientes de regresión |
|
stat.r2 |
Coeficiente de determinación |
|
stat.r |
Coeficiente de correlación |
|
stat.Resid |
Residuales de la regresión |
|
stat.XReg |
La lista de puntos de datos en Lista X modificada se usa de hecho en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.YReg |
La lista de puntos de datos en Lista Y modificada se usa de hecho en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.FrecReg |
Lista de frecuencias correspondientes a stat.XReg y stat.YReg |
|
Catálogo > |
|
|
LinRegMx X,Y[,[Frec][,Categoría,Incluir]] Resuelve la regresión lineal y = m·x+b en las listas X y Y con frecuencia Frec. Un resumen de resultados se almacena en la variable stat.results (aquí). Todas las listas deben tener una dimensión igual, excepto por Incluir. X y Y son listas de variables independientes y dependientes. Frec es una lista opcional de valores de frecuencia. Cada elemento en Frec especifica la frecuencia de la ocurrencia para cada punto de datos X y Y correspondientes. El valor predeterminado es 1. Todos los elementos deben ser enteros | 0. Categoría es una lista de códigos de categoría Incluir es una lista de uno o más códigos de categoría. Sólo aquellos elementos de datos cuyo código de categoría está incluido en esta lista están incluidos en el cálculo. Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.EcnReg |
Ecuación de regresión: y = m·x+b |
|
stat.m, stat.b |
Coeficientes de regresión |
|
stat.r2 |
Coeficiente de determinación |
|
stat.r |
Coeficiente de correlación |
|
stat.Resid |
Residuales de la regresión |
|
stat.XReg |
La lista de puntos de datos en Lista X modificada se usa de hecho en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.YReg |
La lista de puntos de datos en Lista Y modificada se usa de hecho en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.FrecReg |
Lista de frecuencias correspondientes a stat.XReg y stat.YReg |
|
Catálogo > |
|
|
LinRegtIntervals X,Y[,F[,0[,NivC]]] Para Pendiente. Resuelve en un intervalo de confianza de nivel C para la pendiente. LinRegtIntervals X,Y[,F[,1,valX[,nivC]]] Para Respuesta. Resuelve un valor "y" previsto en un intervalo de predicción de nivel C para una observación sencilla, así como un intervalo de confianza de nivel C para la respuesta promedio. Un resumen de resultados se almacena en la variable stat.results (aquí). Todas las listas deben tener una dimensión igual. X y Y son listas de variables independientes y dependientes. F es una lista opcional de valores de frecuencia. Cada elemento en F especifica la frecuencia de la ocurrencia para cada punto de datos X y Y correspondientes. El valor predeterminado es 1. Todos los elementos deben ser enteros | 0. Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.EcnReg |
Ecuación de regresión: a+b·x |
|
stat.a, stat.b |
Coeficientes de regresión |
|
stat.df |
Grados de libertad |
|
stat.r2 |
Coeficiente de determinación |
|
stat.r |
Coeficiente de correlación |
|
stat.Resid |
Residuales de la regresión |
Únicamente para un tipo de pendiente
|
Variable de salida |
Descripción |
|
[stat.CBajo, stat.CAlto] |
Intervalo de confianza para la pendiente. |
|
stat.ME |
Margen de error del intervalo de confianza |
|
stat.EEPendiente |
Error estándar de pendiente |
|
stat.s |
Error estándar sobre la línea |
Para tipo de Respuesta únicamente
|
Variable de salida |
Descripción |
|
[stat.CBajo, stat.CAlto] |
Intervalo de confianza para la respuesta promedio |
|
stat.ME |
Margen de error del intervalo de confianza |
|
stat.EE |
Error estándar de respuesta promedio |
|
[stat.PredBaja, stat.PredAlta] |
Intervalo de predicción para una observación sencilla |
|
stat.MEPred |
Margen de error del intervalo de predicción |
|
stat.EEPred |
Error estándar para la predicción |
|
stat.y |
a + b·valX |
|
Catálogo > |
|
|
LinRegtTest X,Y[,Frec[,Hipot]] Resuelve una regresión lineal en las listas X y Y y una prueba t en el valor de la pendiente b y el coeficiente de correlación r para la ecuación y=a+bx. Prueba la hipótesis nula H0:b=0 (equivalentemente, r=0) contra una de las tres hipótesis alternativas. Todas las listas deben tener una dimensión igual. X y Y son listas de variables independientes y dependientes. Frec es una lista opcional de valores de frecuencia. Cada elemento en Frec especifica la frecuencia de la ocurrencia para cada punto de datos X y Y correspondientes. El valor predeterminado es 1. Todos los elementos deben ser enteros | 0. Hipot es un valor opcional que especifica una de las tres hipótesis alternativas contra la cual se probará la hipótesis nula (H0:b=r=0). Para Ha: bƒ0 y rƒ0 (predeterminada), configuran Hipot=0 Para Ha: b<0 y r<0, configuran Hipot<0 Para Ha: b>0 y r>0, configuran Hipot>0 Un resumen de resultados se almacena en la variable stat.results (aquí). Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.EcnReg |
Ecuación de regresión: a + b·x |
|
stat.t |
t-Estadística para prueba de significancia |
|
stat.ValP |
Nivel más bajo de significancia en el cual la hipótesis nula se puede rechazar |
|
stat.df |
Grados de libertad |
|
stat.a, stat.b |
Coeficientes de regresión |
|
stat.s |
Error estándar sobre la línea |
|
stat.EEPendiente |
Error estándar de pendiente |
|
stat.r2 |
Coeficiente de determinación |
|
stat.r |
Coeficiente de correlación |
|
stat.Resid |
Residuales de la regresión |
|
Catálogo > |
|
|
Entrega una lista de soluciones para las variables Var1, Var2, ... El primer argumento se debe evaluar para un sistema de ecuaciones lineales o una ecuación lineal sencilla. De otro modo, ocurrirá un error de argumento. Por ejemplo, evaluar |
|

|
Catálogo > |
|
|
@List(Lista1)Þlista Nota: Usted puede insertar esta función desde el teclado al escribir deltaList(...). Entrega una lista que contiene las diferencias entre los elementos consecutivos en Lista1. Cada elemento de Lista1 se sustrae del siguiente elemento de Lista1. La lista resultante siempre es un elemento más corto que la Lista1original. |
|
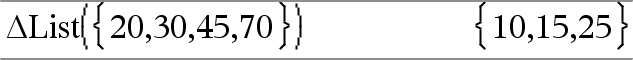
|
Catálogo > |
|
|
list4mat(Lista [, elementosPorFila])Þmatriz Entrega una matriz llenada fila por fila con los elementos de Lista1. elementosPorFila, si están incluidos, especifica el número de elementos por fila. El predeterminado es el número de elementos en Lista (una fila). Si Lista no llena la matriz resultante, se agregan ceros. Nota: Usted puede insertar esta función desde el teclado de la computadora al escribir list@>mat(...). |
|
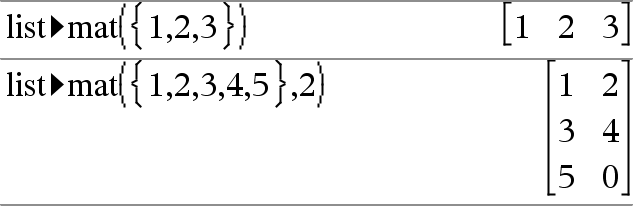
|
/u teclas |
|
|
In(Valor1)Þvalor In(Lista)Þlista Entrega el logaritmo natural del argumento. Para una lista, entrega los logaritmos naturales de los elementos. |
Si el modo de formato complejo es Real:
Si el modo de formato complejo es Rectangular:
|
|
ln(matrizCuadrada1)ÞmatrizCuadrada Entrega el logaritmo natural de la matriz de matrizCuadrada1. Esto no es lo mismo que calcular el logaritmo natural de cada elemento. Para obtener información acerca del método de cálculo, consulte cos() en. matrizCuadrada1 debe ser diagonalizable. El resultado siempre contiene números de punto flotante. |
En el modo de ángulo en Radianes y el formato complejo Rectangular:
Para ver el resultado completo, presione 5 y después use 7 y 8 para mover el cursor. |


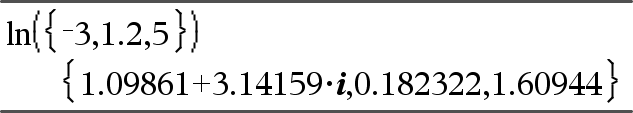

|
Catálogo > |
|
|
LnReg X, Y[, [Frec] [, Categoría, Incluir]] Resuelve la regresión logarítmica y = a+b·In(x) en las listas X y Y con frecuencia Frec. Un resumen de resultados se almacena en la variable stat.results (aquí). Todas las listas deben tener una dimensión igual, excepto por Incluir. X y Y son listas de variables independientes y dependientes. Frec es una lista opcional de valores de frecuencia. Cada elemento en Frec especifica la frecuencia de la ocurrencia para cada punto de datos X y Y correspondientes. El valor predeterminado es 1. Todos los elementos deben ser enteros | 0. Categoría es una lista de códigos de categoría Incluir es una lista de uno o más códigos de categoría. Sólo aquellos elementos de datos cuyo código de categoría está incluido en esta lista están incluidos en el cálculo. Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.EcnReg |
Ecuación de regresión: a+b·In(x) |
|
stat.a, stat.b |
Coeficientes de regresión |
|
stat.r2 |
Coeficiente de determinación lineal para datos transformados |
|
stat.r |
Coeficiente de correlación para datos transformados (ln(x), y) |
|
stat.Resid |
Residuales asociados con el modelo logarítmico |
|
stat.TransResid |
Residuales asociadas con el ajuste lineal de datos transformados |
|
stat.XReg |
La lista de puntos de datos en Lista X modificada se usa de hecho en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.YReg |
La lista de puntos de datos en Lista Y modificada se usa de hecho en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.FrecReg |
Lista de frecuencias correspondientes a stat.XReg y stat.YReg |
|
Catálogo > |
|
|
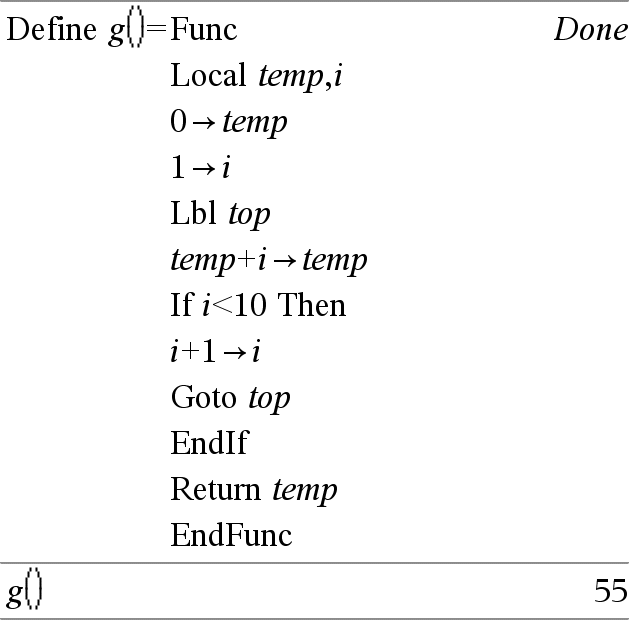
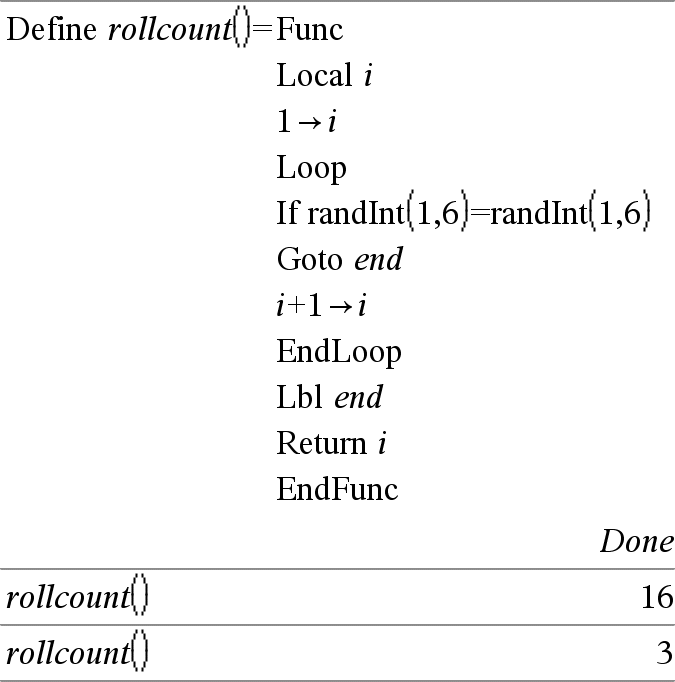
Local Var1[, Var2] [, Var3] ... Declara las vars especificadas como variables locales. Esas variables existen sólo durante la evaluación de una función y se borran cuando la función termina la ejecución. Nota: Las variables locales ahorran memoria porque sólo existen en forma temporal. Asimismo, no alteran ninguno de los valores de variable global existentes. Las variables locales se deben usar para los bucles y para guardar temporalmente los valores en una función de líneas múltiples, ya que las modificaciones en las variables globales no están permitidas en una función. Nota para introducir el ejemplo: Para obtener instrucciones sobre cómo introducir las definiciones de programas y funciones en varias líneas, consulte la sección Calculadora de la guía del producto. |
|
|
Catálogo > |
|
|
Bloquea las variables o el grupo de variables especificado. Las variables bloqueadas no se pueden modificar ni borrar. Usted no puede bloquear o desbloquear la variable de sistema Ans, y no puede bloquear los grupos de variables de sistema stat. o tvm. Nota: El comando Lock limpia el historial de Deshacer/Rehacer cuando se aplica a variables no bloqueadas. |
|

|
/s teclas |
|
|
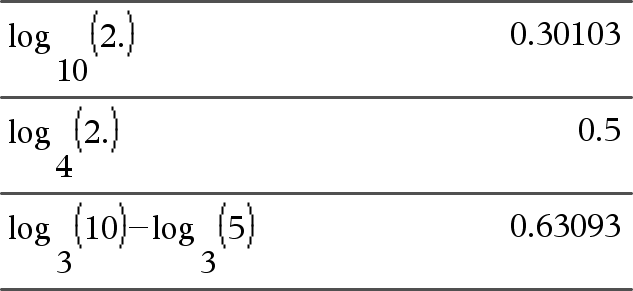
log(Lista1[,Valor2])Þlista
Entrega el logaritmoValor2 base del primer argumento. Nota: Vea también Plantilla de logaritmos, aquí. Para una lista, entrega el logaritmoValor2 base de los elementos. Si el segundo argumento se omite, se usa 10 como la base. |
Si el modo de formato complejo es Real:
Si el modo de formato complejo es Rectangular:
|
|
Entrega el logaritmoValor base de la matriz de matrizCuadrada1. Esto no es lo mismo que calcular el logaritmoValor base de cada elemento. Para obtener información acerca del método de cálculo, consulte cos(). matrizCuadrada1 debe ser diagonalizable. El resultado siempre contiene números de punto flotante. Si el argumento base se omite, se usa 10 como la base. |
En el modo de ángulo en Radianes y el formato complejo Rectangular:
Para ver el resultado completo, presione 5 y después use 7 y 8 para mover el cursor. |



|
Catálogo > |
|
|
Logístic X, Y[, [Frec] [, Categoría, Incluir]] Resuelve la regresión logísticay = (c/(1+a·e^bx)+d)en las listas X y Y con frecuencia Frec. Un resumen de resultados se almacena en la variable stat.results (aquí). Todas las listas deben tener una dimensión igual, excepto por Incluir. X y Y son listas de variables independientes y dependientes. Frec es una lista opcional de valores de frecuencia. Cada elemento en Frec especifica la frecuencia de la ocurrencia para cada punto de datos X y Y correspondientes. El valor predeterminado es 1. Todos los elementos deben ser enteros | 0. Categoría es una lista de códigos de categoría Incluir es una lista de uno o más códigos de categoría. Sólo aquellos elementos de datos cuyo código de categoría está incluido en esta lista están incluidos en el cálculo. Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.EcnReg |
Ecuación de regresión: c/(1+a·e^bx+d) |
|
stat.a, stat.b, stat.c |
Coeficientes de regresión |
|
stat.Resid |
Residuales de la regresión |
|
stat.XReg |
La lista de puntos de datos en la Lista X modificada que se usa en realidad en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.YReg |
La lista de puntos de datos en la Lista Y modificada que se usa en realidad en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.FrecReg |
Lista de frecuencias correspondientes a stat.XReg y stat.YReg |
|
Catálogo > |
|
|
LogísticD X, Y [ , [Iteraciones] , [Frec] [, Categoría, Incluir] ] Resuelve la regresión logística y = (c/(1+a·e^bx)) en las listas X y Y con frecuencia Frec, utilizando un número específico de Iteraciones. Un resumen de resultados se almacena en la variable stat.results (aquí). Todas las listas deben tener una dimensión igual, excepto por Incluir. X y Y son listas de variables independientes y dependientes. Frec es una lista opcional de valores de frecuencia. Cada elemento en Frec especifica la frecuencia de la ocurrencia para cada punto de datos X y Y correspondientes. El valor predeterminado es 1. Todos los elementos deben ser enteros | 0. Categoría es una lista de códigos de categoría Incluir es una lista de uno o más códigos de categoría. Sólo aquellos elementos de datos cuyo código de categoría está incluido en esta lista están incluidos en el cálculo. Para obtener información sobre el efecto de los elementos vacíos en una lista, vea “Elementos vacíos (inválidos)” (aquí). |
|
|
Variable de salida |
Descripción |
|
stat.EcnReg |
Ecuación de regresión: c/(1+a·e^bx) |
|
stat.a, stat.b, stat.c, stat.d |
Coeficientes de regresión |
|
stat.Resid |
Residuales de la regresión |
|
stat.XReg |
La lista de puntos de datos en la Lista X modificada que se usa en realidad en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.YReg |
La lista de puntos de datos en la Lista Y modificada que se usa en realidad en la regresión con base en las restricciones de las Categorías Frec, Lista de Categoríae Incluir |
|
stat.FrecReg |
Lista de frecuencias correspondientes a stat.XReg y stat.YReg |
|
Catálogo > |
|
|
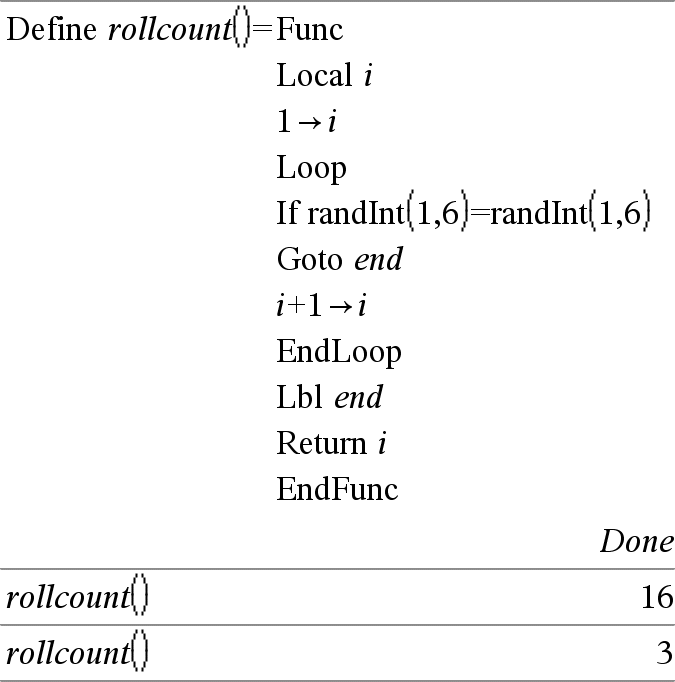
Loop Ejecuta en forma repetida las sentencias en el Bloque. Tome en cuenta que el bucle se ejecutará sin parar, a menos que se ejecute una instrucción Goto o Exit dentro del Bloque. Bloque es una secuencia de sentencias separadas con el caracter ":". Nota para introducir el ejemplo: Para obtener instrucciones sobre cómo introducir las definiciones de programas y funciones en varias líneas, consulte la sección Calculadora de la guía del producto. |
|
|
Catálogo > |
|||||||
|
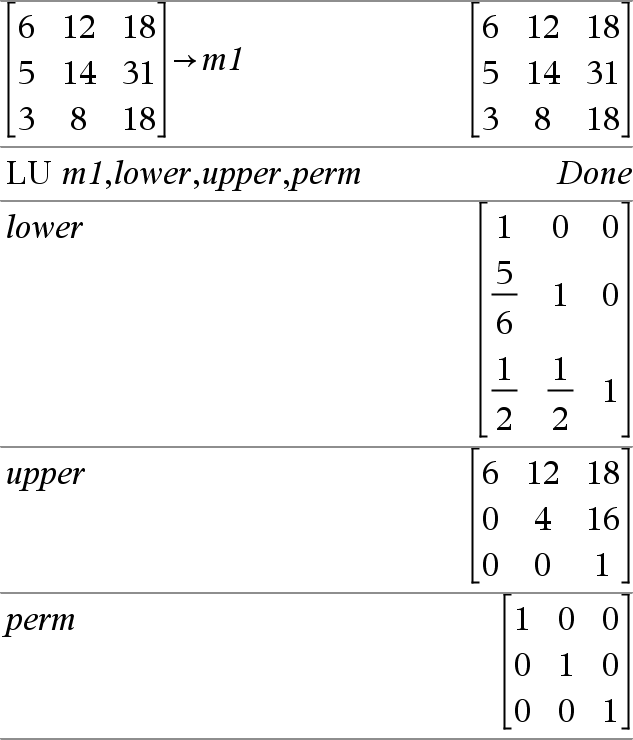
LU Matriz, matrizB, matrizA, matrizP[,Tol] Calcula la descomposición BA (baja-alta) de Doolittle de una matriz real o compleja. La matriz triangular baja se almacena en matriz B, la matriz triangular alta en matriz Ay la matriz de permutación (que describe los cambios de fila realizados durante el cálculo) en matriz P. matrizB · matrizA = matrizP · matriz De manera opcional, cualquier elemento de matriz se trata como cero si su valor absoluto es menor que la Tolerancia. Esta tolerancia se usa sólo si la matriz tiene ingresos de punto flotante y no contiene ninguna variable simbólica a la que no se le haya asignado un valor. De otro modo, la Tolerancia se ignora.
El algoritmo de factorización LU usa un pivoteo parcial con intercambios de filas. |
|