|
Catálogo > |
|||||||||||||
|
factor(NúmeroRacional) devolve o número racional em primos. Para números compostos, o tempo de cálculo cresce exponencialmente com o número de dígitos no segundo maior factor. Por exemplo, a decomposição em factores de um número inteiro de 30 dígitos pode demorar mais de um dia e a decomposição em factores de um número de 100 dígitos pode demorarar mais de um século. Para parar um cálculo manualmente,
Se quiser apenas determinar se um número é primo, utilize isPrime(). É muito mais rápido, em especial, se o NúmeroRacional não for primo e o segundo maior factor tiver mais de cinco dígitos. |
|


|
Catálogo > |
|
|
FCdf(LimiteInferior, LimiteSuperior, dfNumer, dfDenom) Þnúmero se LimiteInferior e LimiteSuperior forem números, lista se LimiteInferior e LimiteSuperior forem listas FCdf(LimiteInferior, LimiteSuperior, dfNumer, dfDenom) Þnúmero se LimiteInferior e LimiteSuperior forem números, lista se LimiteInferior e LimiteSuperior forem listas Calcula a probabilidade da distribuição F entre LimiteInferior e LimiteSuperior para o dfNumer (graus de liberdade) e dfDenom especificados. Para P(X { LimiteSuperior), definir LimiteInferior = 0. |
|
|
Catálogo > |
|
|
Fill Valor, VarMatriz Þmatriz Substitui cada elemento na variável VarMatriz por Valor. matrixVar já tem de existir. |
|
|
Fill Valor, VarLista Þlista Substitui cada elemento na variável VarLista por Valor. VarLista já tem de existir. |
|


|
Catálogo > |
|
|
FiveNumSummary X[,[Freq][,Categoria,Incluir]] Fornece uma versão abreviada da estatística de 1 variável na lista X. Um resumo dos resultados é guardado na variável stat.results (aqui). X representa uma lista de dados. Freq é uma lista opcional de valores de frequência. Cada elemento em Freq especifica a frequência de ocorrência para cada valor X correspondente. O valor predefinido é 1. Todos os elementos têm de ser números inteiros 0. Categoria é uma lista de códigos de categorias numéricos para os valores X correspondentes. Incluir é uma lista de um ou mais códigos de categorias. Apenas os itens de dados cujo código de categoria está incluído nesta lista são considerados no cálculo. Um elemento (nulo) vazio em qualquer das listas X, Freq ou Category resulta num nulo para o elemento correspondente de todas essas listas. Para mais informações sobre os elementos vazios, consulte aqui. |
|
|
Variável de saída |
Descrição |
|
stat.MinX |
Mínimo dos valores x |
|
stat.Q1X |
1º quartil de x |
|
stat.MedianX |
Mediana de x |
|
stat.Q3X |
3º quartil de x |
|
stat.MaxX |
Máximo dos valores x |
|
Catálogo > |
|
|
floor(Valor1) Þnúmero inteiro Devolve o maior número inteiro que é { o argumento. Esta função é idêntica a int(). O argumento pode ser um número complexo ou real. |
|
|
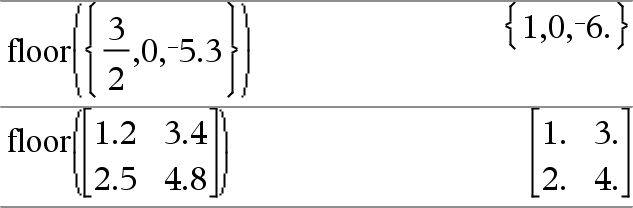
floor(Lista1) Þlista floor(Matriz1) Þmatriz Devolve uma lista ou matriz do floor de cada elemento. Nota: Consulte também ceiling() e int(). |
|

|
Catálogo > |
|
|
For Var, Baixo, Alto [, Passo ] Bloco EndFor Executa as declarações em Bloco iterativamente para cada valor de Var, de Baixo para Alto, em incrementos de Passo. Var não tem de ser uma variável do sistema. Passo pode ser positivo ou negativo. O valor predefinido é 1. Bloco pode ser uma declaração ou uma série de declarações separadas pelo carácter “:”. Obs para introdução do exemplo: Para obter instruções sobre como introduzir programas com várias linhas e definições de funções, consulte a secção Calculadora do manual do utilizador do produto. |
|

|
Catálogo > |
|
|
format(Valor [, CadeiaFormato ]) Þcadeia Devolve Valor como uma cadeia de caracteres com base no modelo do formato. CadeiaFormato é uma cadeia e tem de estar na forma: “F[n]”, “S[n]”, “E[n]”, “G[n][c]”, em que [ ] indica porções opcionais. F[n]: Formato fixo. n é o número de dígitos para visualizar o ponto decimal. S[n]: Formato científico. n é o número de dígitos para visualizar o ponto decimal. E[n]: Formato de engenharia. n é o número de dígitos após o primeiro dígito significante. O exponente é ajustado para um múltiplo de três e o ponto decimal é movido para a direita zero, um ou dois dígitos. G[n][c]: Igual ao formato fixo mas também separa os dígitos à esquerda da raiz em grupos de três. c especifica o carácter do separador de grupos e predefine para uma vírgula. Se c for um ponto, a raiz será apresentada como uma vírgula. [Rc]: Qualquer um dos especificadores acima pode ser sufixado com o marcador de raiz Rc, em que c é um carácter que especifica o que substituir pelo ponto da raiz. |
|

|
Catálogo > |
|
|
fPart(Expr1) Þexpressão fPart(Lista1) Þlista fPart(Matriz1) Þmatriz Devolve a parte fraccionária do argumento. Para uma lista ou matriz, devolve as partes fraccionárias dos elementos. O argumento pode ser um número complexo ou real. |
|

|
Catálogo > |
|
|
FPdf(ValX, dfNumer, dfDenom) Þnúmero se ValX for um número, lista se ValX for uma lista Calcula a probabilidade da distribuição F no ValX para o dfNumer (graus de liberdade) e o dfDenom especificados. |
|
|
Catálogo > |
|
|
freqTable4list(Lista1,ListaNúmerosInteirosFreq)Þlista Apresenta uma lista com os elementos de Lista1 expandida de acordo com as frequências em ListaNúmerosInteirosFreq. Esta função pode ser utilizada para construir uma tabela de frequência para a aplicação Dados e Estatística. Lista1 pode ser qualquer lista válida. ListaNúmerosInteirosFreq tem de ter a mesma dimensão da Lista1 e só deve conter elementos de números inteiros não negativos. Cada elemento especifica o número de vezes que o elemento de Lista1 correspondente é repetido na lista de resultados. Um valor de zero exclui o elemento de Lista1 correspondente. Nota: Pode introduzir esta função através da escrita de freqTable@>list(...) no teclado do computador. Os elementos (nulos) vazios são ignorados. Para mais informações sobre os elementos vazios, consulte aqui. |
|

|
Catálogo > |
|
|
frequency(Lista1,Listabins) Þlista Devolve uma lista que contém as contagens dos elementos em Lista1. As contagens são baseadas em intervalos (bins) definidos em Listabins. Se Listabins for {b(1), b(2), …, b(n)}, os intervalos especificados são {?{ b(1), b(1)<?{ b(2),…,b(n-1)<?{ b(n), b(n)>?}. A lista resultante é um elemento maior que Listabins. Cada elemento do resultado corresponde ao número de elementos de Lista1 que estão no intervalo desse lote. Expresso em termos da função countIf(), o resultado é { countIf(list, ?{ b(1)), countIf(lista, b(1)<?{ b(2)), …, countIf(lista, b(n-1)<?{ b(n)), countIf(lista, b(n)>?)}. Elementos de Lista1 que não podem ser “colocados num lote” são ignorados. Elementos de Lista1 que não podem ser “colocados num lote” são ignorados. Os elementos (nulos) vazios também são ignorados. Para mais informações sobre os elementos vazios, consulte aqui. Na aplicação Listas e Folha de cálculo, pode utilizar um intervalo de células no lugar de ambos os argumentos. Nota: Consulte também countIf(), aqui. |
Explicação do resultado: 2 elementos da Lista de dados são { 2.5 4 elementos da Lista de dados são >2.5 e { 4.5 3 elementos da Lista de dados são >4.5 O elemento “hello” é uma cadeia e não pode ser colocado em nenhum lote definido. |

|
Catálogo > |
|
|
FTest_2Samp Lista1, Lista2 [, Freq1 [, Freq2 [, Hipótese ]]] FTest_2Samp Lista1, Lista2 [, Freq1 [, Freq2 [, Hipótese ]]] (Entrada da lista de dados) FTest_2Samp sx1, n1, sx2, n2 [, Hipótese] FTest_2Samp sx1, n1, sx2, n2 [, Hipótese] (Entrada estatística do resumo) Efectua um teste F de duas amostras. Um resumo dos resultados é guardado na variável stat.results (aqui). ou Ha: s1 > s2, defina Hipótese>0 Para Ha: s1 ƒ s2 (predefinição), defina Hipótese =0 Para Ha: s1 < s2, defina Hipótese<0 Para mais informações sobre o efeito dos elementos vazios numa lista, consulte “Elementos (nulos) vazios” (aqui). |
|
|
Variável de saída |
Descrição |
|
stat.F |
Estatística Û calculada para a sequência de dados |
|
stat.PVal |
Menor nível de significância para o qual a hipótese nula pode ser rejeitada |
|
stat.dfNumer |
graus de liberdade do “numerador” = n1-1 |
|
stat.dfDenom |
graus de liberdade do “denominador”= n2-1 |
|
stat.sx1, stat.sx2 |
Desvios padrão da amostra das sequências de dados em Lista 1 e Lista 2 |
|
stat.x1_bar stat.x2_bar |
Médias da amostra das sequência de dados em Lista 1 e Lista 2 |
|
stat.n1, stat.n2 |
Tamanho das amostras |
|
Catálogo > |
|
|
Func Bloco EndFunc Modelo para criar uma função definida pelo utilizador. Bloco pode ser uma declaração, uma série de declarações separadas pelo carácter “:” ou uma série de declarações em linhas separadas. A função pode utilizar a função Return para devolver um resultado específicos. Obs para introdução do exemplo: Para obter instruções sobre como introduzir programas com várias linhas e definições de funções, consulte a secção Calculadora do manual do utilizador do produto. |
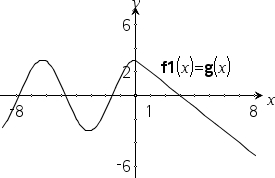
Definir uma função por ramos:
Resultado do gráfico g(x)
|