|
Catalogue > |
|
|
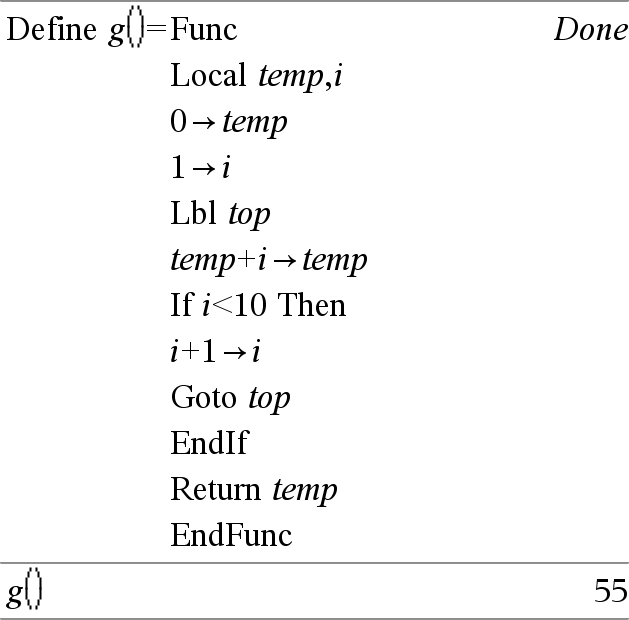
Lbl labelName Defines a label with the name labelName within a function. You can use a Goto labelName instruction to transfer control to the instruction immediately following the label. labelName must meet the same naming requirements as a variable name. Note for entering the example: For instructions on entering multi-line programme and function definitions, refer to the Calculator section of your product guidebook. |
|

|
Catalogue > |
|
|
lcm(Number1, Number2)Þexpression lcm(List1, List2)Þlist lcm(Matrix1, Matrix2)Þmatrix Returns the least common multiple of the two arguments. The lcm of two fractions is the lcm of their numerators divided by the gcd of their denominators. The lcm of fractional floating-point numbers is their product. For two lists or matrices, returns the least common multiples of the corresponding elements. |
|
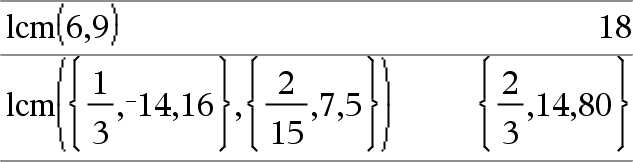
|
Catalogue > |
|
|
left(sourceString[, Num])Þstring Returns the leftmost Num characters contained in character string sourceString. If you omit Num, returns all of sourceString. |
|
|
left(List1[, Num])Þlist Returns the leftmost Num elements contained in List1. If you omit Num, returns all of List1. |
|
|
left(Comparison)Þexpression Returns the left-hand side of an equation or inequality. |
|



|
Catalogue > |
|
|
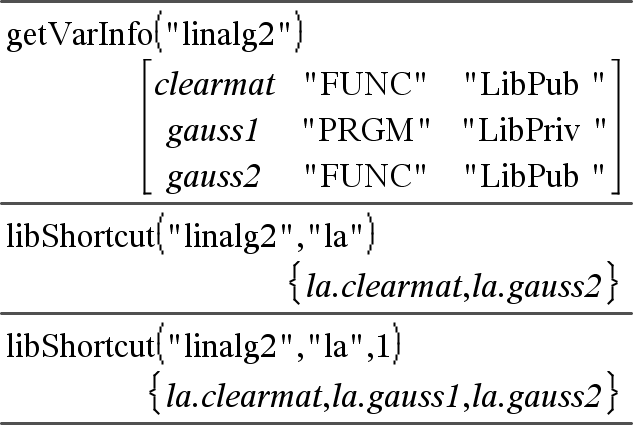
libShortcut(LibNameString, ShortcutNameString [, LibPrivFlag])Þlist of variables Creates a variable group in the current problem that contains references to all the objects in the specified library document libNameString. Also adds the group members to the Variables menu. You can then refer to each object using its ShortcutNameString. Set LibPrivFlag=0 to exclude private library objects (default) Set LibPrivFlag=1 to include private library objects To copy a variable group, see CopyVar, here. To delete a variable group, see DelVar, here. |
This example assumes a properly stored and refreshed library document named linalg2 that contains objects defined as clearmat, gauss1 and gauss2.
|
|
Catalogue > |
|
|
limit(Expr1, Var, Point [,Direction])Þexpression limit(List1, Var, Point [, Direction])Þlist limit(Matrix1, Var, Point [, Direction])Þmatrix Returns the limit requested. Note: See also Limit template, here. Direction: negative=from left, positive=from right, otherwise=both. (If omitted, Direction defaults to both.) |
|
|
Limits at positive ˆ and at negative ˆ are always converted to one-sided limits from the finite side. |
|
|
Depending on the circumstances, limit() returns itself or undef when it cannot determine a unique limit. This does not necessarily mean that a unique limit does not exist. undef means that the result is either an unknown number with finite or infinite magnitude, or it is the entire set of such numbers. |
|
|
limit() uses methods such as L’Hopital’s rule, so there are unique limits that it cannot determine. If Expr1 contains undefined variables other than Var, you might have to constrain them to obtain a more concise result. Limits can be very sensitive to rounding error. When possible, avoid the Approximate setting of the Auto or Approximate mode and approximate numbers when computing limits. Otherwise, limits that should be zero or have infinite magnitude probably will not, and limits that should have finite non-zero magnitude might not. |
|
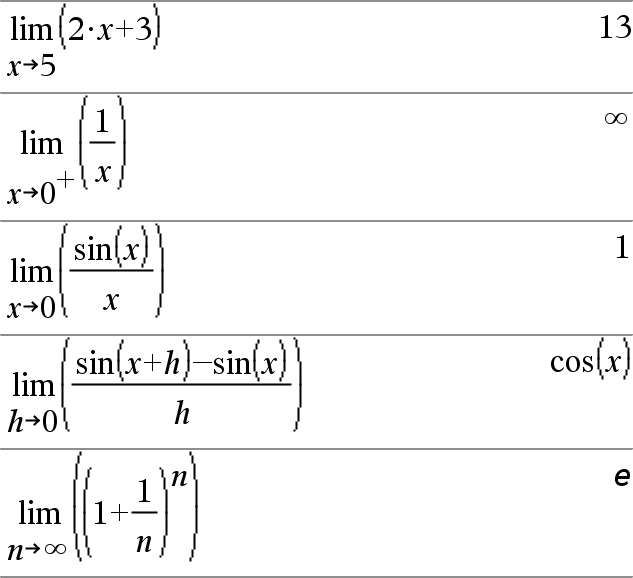
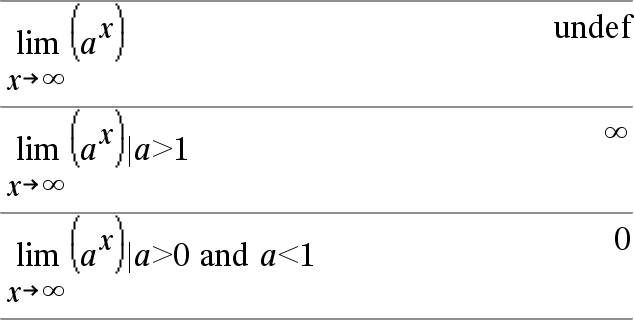
|
Catalogue > |
|
|
LinRegBx X,Y[,[Freq][,Category,Include]] Computes the linear regressiony = a+b·xon lists X and Y with frequency Freq. A summary of results is stored in the stat.results variable (here). All the lists must have equal dimension except for Include. X and Y are lists of independent and dependent variables. Freq is an optional list of frequency values. Each element in Freq specifies the frequency of occurrence for each corresponding X and Y data point. The default value is 1. All elements must be integers | 0. Category is a list of category codes for the corresponding X and Y data. Include is a list of one or more of the category codes. Only those data items whose category code is included in this list are included in the calculation. For information on the effect of empty elements in a list, see “Empty (Void) Elements”, here. |
|
|
Output variable |
Description |
|
stat.RegEqn |
Regression Equation: a+b·x |
|
stat.a, stat.b |
Regression coefficients |
|
stat.r2 |
Coefficient of determination |
|
stat.r |
Correlation coefficient |
|
stat.Resid |
Residuals from the regression |
|
stat.XReg |
List of data points in the modified X List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.YReg |
List of data points in the modified Y List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.FreqReg |
List of frequencies corresponding to stat.XReg and stat.YReg |
|
Catalogue > |
|
|
LinRegMx X,Y[,[Freq][,Category,Include]] Computes the linear regression y = m·x+b on lists X and Y with frequency Freq. A summary of results is stored in the stat.results variable (here). All the lists must have equal dimension except for Include. X and Y are lists of independent and dependent variables. Freq is an optional list of frequency values. Each element in Freq specifies the frequency of occurrence for each corresponding X and Y data point. The default value is 1. All elements must be integers | 0. Category is a list of category codes for the corresponding X and Y data. Include is a list of one or more of the category codes. Only those data items whose category code is included in this list are included in the calculation. For information on the effect of empty elements in a list, see “Empty (Void) Elements”, here. |
|
|
Output variable |
Description |
|
stat.RegEqn |
Regression Equation: y = m·x+b |
|
stat.m, stat.b |
Regression coefficients |
|
stat.r2 |
Coefficient of determination |
|
stat.r |
Correlation coefficient |
|
stat.Resid |
Residuals from the regression |
|
stat.XReg |
List of data points in the modified X List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.YReg |
List of data points in the modified Y List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.FreqReg |
List of frequencies corresponding to stat.XReg and stat.YReg |
|
Catalogue > |
|
|
LinRegtIntervals X,Y[,F[,0[,CLev]]] For Slope. Computes a level C confidence interval for the slope. LinRegtIntervals X,Y[,F[,1,Xval[,CLev]]] For Response. Computes a predicted y-value, a level C prediction interval for a single observation and a level C confidence interval for the mean response. A summary of results is stored in the stat.results variable (here). All the lists must have equal dimension. X and Y are lists of independent and dependent variables. F is an optional list of frequency values. Each element in F specifies the frequency of occurrence for each corresponding X and Y data point. The default value is 1. All elements must be integers | 0. For information on the effect of empty elements in a list, see “Empty (Void) Elements”, here. |
|
|
Output variable |
Description |
|
stat.RegEqn |
Regression Equation: a+b·x |
|
stat.a, stat.b |
Regression coefficients |
|
stat.df |
Degrees of freedom |
|
stat.r2 |
Coefficient of determination |
|
stat.r |
Correlation coefficient |
|
stat.Resid |
Residuals from the regression |
For Slope type only
|
Output variable |
Description |
|
[stat.CLower, stat.CUpper] |
Confidence interval for the slope |
|
stat.ME |
Confidence interval margin of error |
|
stat.SESlope |
Standard error of slope |
|
stat.s |
Standard error about the line |
For Response type only
|
Output variable |
Description |
|
[stat.CLower, stat.CUpper] |
Confidence interval for the mean response |
|
stat.ME |
Confidence interval margin of error |
|
stat.SE |
Standard error of mean response |
|
[stat.LowerPred, stat.UpperPred] |
Prediction interval for a single observation |
|
stat.MEPred |
Prediction interval margin of error |
|
stat.SEPred |
Standard error for prediction |
|
stat.y |
a + b·XVal |
|
Catalogue > |
|
|
LinRegtTest X,Y[,Freq[,Hypoth]] Computes a linear regression on the X and Y lists and a t test on the value of slope b and the correlation coefficient r for the equation y=a+bx. It tests the null hypothesis H0:b=0 (equivalently, r=0) against one of three alternative hypotheses. All the lists must have equal dimension. X and Y are lists of independent and dependent variables. Freq is an optional list of frequency values. Each element in Freq specifies the frequency of occurrence for each corresponding X and Y data point. The default value is 1. All elements must be integers | 0. Hypoth is an optional value specifying one of three alternative hypotheses against which the null hypothesis (H0:b=r=0) will be tested. For Ha: bƒ0 and rƒ0 (default), set Hypoth=0 For Ha: b<0 and r<0, set Hypoth<0 For Ha: b>0 and r>0, set Hypoth>0 A summary of results is stored in the stat.results variable (here). For information on the effect of empty elements in a list, see “Empty (Void) Elements”, here. |
|
|
Output variable |
Description |
|
stat.RegEqn |
Regression equation: a + b·x |
|
stat.t |
t-Statistic for significance test |
|
stat.PVal |
Smallest level of significance at which the null hypothesis can be rejected |
|
stat.df |
Degrees of freedom |
|
stat.a, stat.b |
Regression coefficients |
|
stat.s |
Standard error about the line |
|
stat.SESlope |
Standard error of slope |
|
stat.r2 |
Coefficient of determination |
|
stat.r |
Correlation coefficient |
|
stat.Resid |
Residuals from the regression |
|
Catalogue > |
|
|
Returns a list of solutions for the variables Var1, Var2, ... The first argument must evaluate to a system of linear equations or a single linear equation. Otherwise, an argument error occurs. For example, evaluating |
|

|
Catalogue > |
|
|
@List(List1)Þlist Note: You can insert this function from the keyboard by typing deltaList(...). Returns a list containing the differences between consecutive elements in List1. Each element of List1 is subtracted from the next element of List1. The resulting list is always one element shorter than the original List1. |
|
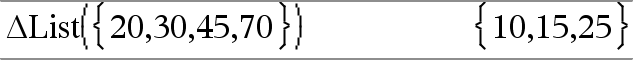
|
Catalogue > |
|
|
list4mat(List [, elementsPerRow])Þmatrix Returns a matrix filled row-by-row with the elements from List. elementsPerRow, if included, specifies the number of elements per row. Default is the number of elements in List (one row). If List does not fill the resulting matrix, zeroes are added. Note: You can insert this function from the computer keyboard by typing list@>mat(...). |
|
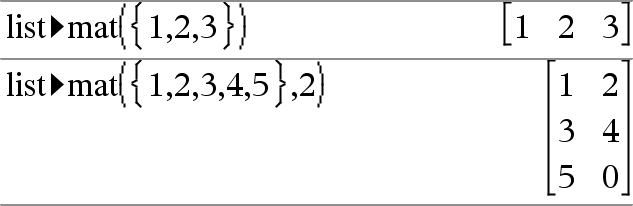
|
Catalogue > |
|
|
Expr 4lnÞexpression Causes the input Expr to be converted to an expression containing only natural logs (ln). Note: You can insert this operator from the computer keyboard by typing @>ln. |
|

|
/u keys |
|
|
ln(Expr1)Þexpression ln(List1)Þlist Returns the natural logarithm of the argument. For a list, returns the natural logarithms of the elements. |
If complex format mode is Real:
If complex format mode is Rectangular:
|
|
ln(squareMatrix1)ÞsquareMatrix Returns the matrix natural logarithm of squareMatrix1. This is not the same as calculating the natural logarithm of each element. For information about the calculation method, refer to cos() on. squareMatrix1 must be diagonalisable. The result always contains floating-point numbers. |
In Radian angle mode and Rectangular complex format:
To see the entire result, press 5 and then use 7 and 8 to move the cursor. |


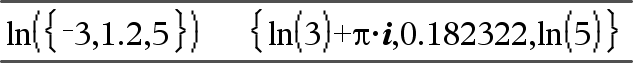

|
Catalogue > |
|
|
LnReg X, Y[, [Freq] [, Category, Include]] Computes the logarithmic regression y = a+b·ln(x) on lists X and Y with frequency Freq. A summary of results is stored in the stat.results variable (here). All the lists must have equal dimension except for Include. X and Y are lists of independent and dependent variables. Freq is an optional list of frequency values. Each element in Freq specifies the frequency of occurrence for each corresponding X and Y data point. The default value is 1. All elements must be integers | 0. Category is a list of category codes for the corresponding X and Y data. Include is a list of one or more of the category codes. Only those data items whose category code is included in this list are included in the calculation. For information on the effect of empty elements in a list, see “Empty (Void) Elements”, here. |
|
|
Output variable |
Description |
|
stat.RegEqn |
Regression equation: a+b·ln(x) |
|
stat.a, stat.b |
Regression coefficients |
|
stat.r2 |
Coefficient of linear determination for transformed data |
|
stat.r |
Correlation coefficient for transformed data (ln(x), y) |
|
stat.Resid |
Residuals associated with the logarithmic model |
|
stat.ResidTrans |
Residuals associated with linear fit of transformed data |
|
stat.XReg |
List of data points in the modified X List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.YReg |
List of data points in the modified Y List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.FreqReg |
List of frequencies corresponding to stat.XReg and stat.YReg |
|
Catalogue > |
|
|
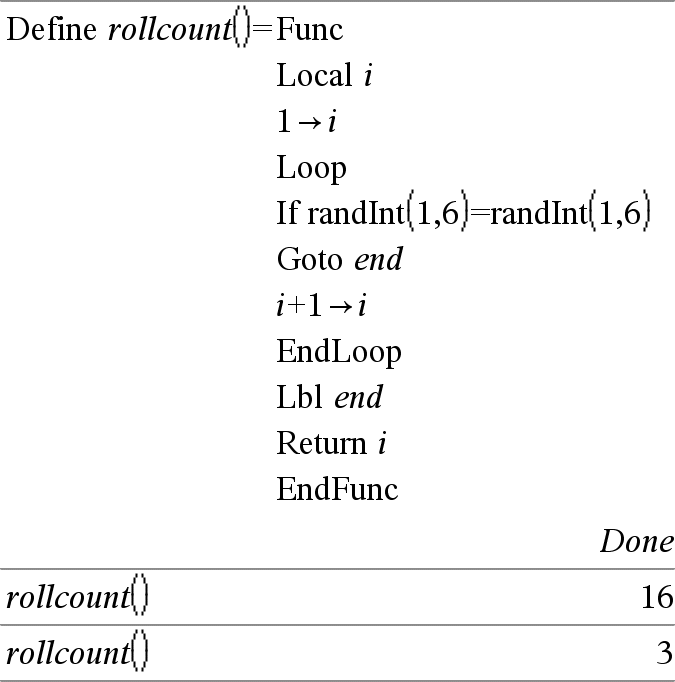
Local Var1[, Var2] [, Var3] ... Declares the specified vars as local variables. Those variables exist only during evaluation of a function and are deleted when the function finishes execution. Note: Local variables save memory because they only exist temporarily. Also, they do not disturb any existing global variable values. Local variables must be used for For loops and for temporarily saving values in a multi-line function since modifications on global variables are not allowed in a function. Note for entering the example: For instructions on entering multi-line programme and function definitions, refer to the Calculator section of your product guidebook. |
|
|
Catalogue > |
|
|
Locks the specified variables or variable group. Locked variables cannot be modified or deleted. You cannot lock or unlock the system variable Ans, and you cannot lock the system variable groups stat. or tvm. Note: The Lock command clears the Undo/Redo history when applied to unlocked variables. |
|

|
/s keys |
|
|
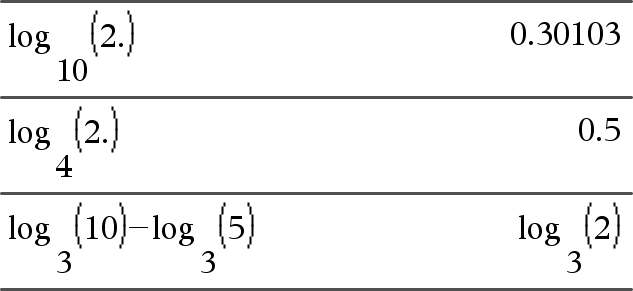
log(List1[,Expr2])Þlist
Returns the base-Expr2 logarithm of the first argument. Note: See also Log template, here. For a list, returns the base-Expr2 logarithm of the elements. If the second argument is omitted, 10 is used as the base. |
If complex format mode is Real:
If complex format mode is Rectangular:
|
|
Returns the matrix base-Expr logarithm of squareMatrix1. This is not the same as calculating the base-Expr logarithm of each element. For information about the calculation method, refer to cos(). squareMatrix1 must be diagonalisable. The result always contains floating-point numbers. If the base argument is omitted, 10 is used as base. |
In Radian angle mode and Rectangular complex format:
To see the entire result, press 5 and then use 7 and 8 to move the cursor. |



|
Catalogue > |
|
|
Expr 4logbase(Expr1)Þexpression Causes the input Expression to be simplified to an expression using base Expr1. Note: You can insert this operator from the computer keyboard by typing @>logbase(...). |
|

|
Catalogue > |
|
|
Logistic X, Y[, [Freq] [, Category, Include]] Computes the logistic regressiony = (c/(1+a·e-bx))on lists X and Y with frequency Freq. A summary of results is stored in the stat.results variable (here). All the lists must have equal dimension except for Include. X and Y are lists of independent and dependent variables. Freq is an optional list of frequency values. Each element in Freq specifies the frequency of occurrence for each corresponding X and Y data point. The default value is 1. All elements must be integers | 0. Category is a list of category codes for the corresponding X and Y data. Include is a list of one or more of the category codes. Only those data items whose category code is included in this list are included in the calculation. For information on the effect of empty elements in a list, see “Empty (Void) Elements”, here. |
|
|
Output variable |
Description |
|
stat.RegEqn |
Regression equation: c/(1+a·e-bx) |
|
stat.a, stat.b, stat.c |
Regression coefficients |
|
stat.Resid |
Residuals from the regression |
|
stat.XReg |
List of data points in the modified X List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.YReg |
List of data points in the modified Y List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.FreqReg |
List of frequencies corresponding to stat.XReg and stat.YReg |
|
Catalogue > |
|
|
LogisticD X, Y [ , [Iterations] , [Freq] [, Category, Include] ] Computes the logistic regression y = (c/(1+a·e-bx)+d) on lists X and Y with frequency Freq, using a specified number of Iterations. A summary of results is stored in the stat.results variable (here). All the lists must have equal dimension except for Include. X and Y are lists of independent and dependent variables. Freq is an optional list of frequency values. Each element in Freq specifies the frequency of occurrence for each corresponding X and Y data point. The default value is 1. All elements must be integers | 0. Category is a list of category codes for the corresponding X and Y data. Include is a list of one or more of the category codes. Only those data items whose category code is included in this list are included in the calculation. For information on the effect of empty elements in a list, see “Empty (Void) Elements”, here. |
|
|
Output variable |
Description |
|
stat.RegEqn |
Regression equation: c/(1+a·e-bx)+d) |
|
stat.a, stat.b, stat.c, stat.d |
Regression coefficients |
|
stat.Resid |
Residuals from the regression |
|
stat.XReg |
List of data points in the modified X List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.YReg |
List of data points in the modified Y List actually used in the regression based on restrictions of Freq, Category List and Include Categories |
|
stat.FreqReg |
List of frequencies corresponding to stat.XReg and stat.YReg |
|
Catalogue > |
|
|
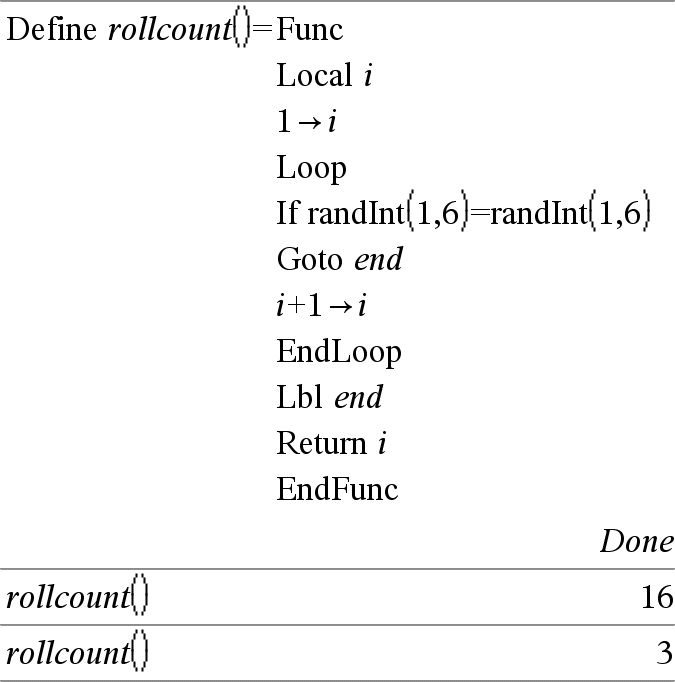
Loop Block EndLoop Repeatedly executes the statements in Block. Note that the loop will be executed endlessly, unless a Goto or Exit instruction is executed within Block. Block is a sequence of statements separated with the “:” character. Note for entering the example: For instructions on entering multi-line programme and function definitions, refer to the Calculator section of your product guidebook. |
|
|
Catalogue > |
|||||||
|
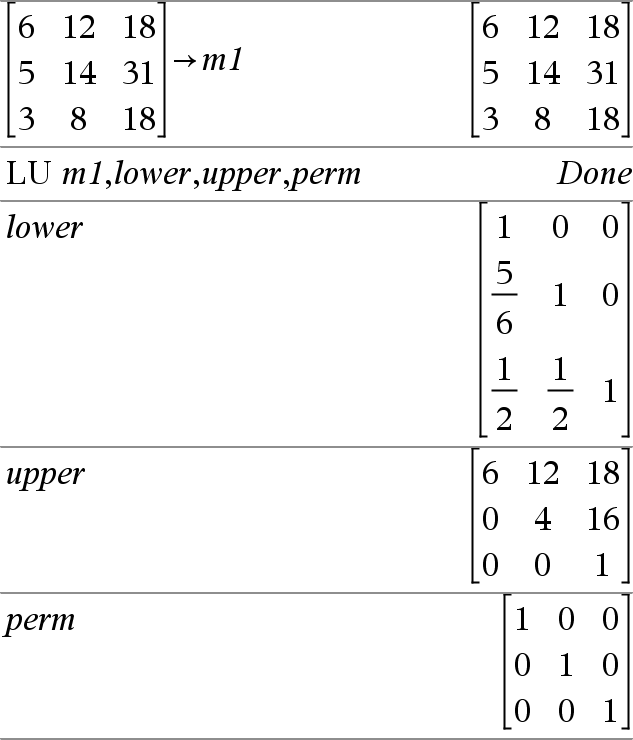
LU Matrix, lMatrix, uMatrix, pMatrix[,Tol] Calculates the Doolittle LU (lower-upper) decomposition of a real or complex matrix. The lower triangular matrix is stored in lMatrix, the upper triangular matrix in uMatrix and the permutation matrix (which describes the row swaps done during the calculation) in pMatrix. lMatrix · uMatrix = pMatrix · matrix Optionally, any matrix element is treated as zero if its absolute value is less than Tol. This tolerance is used only if the matrix has floating-point entries and does not contain any symbolic variables that have not been assigned a value. Otherwise, Tol is ignored.
The LU factorization algorithm uses partial pivoting with row interchanges. |
|